 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounded Exploration with World Model Uncertainty in Soft Actor-Critic Reinforcement Learning Algorithm
Dec 09, 2024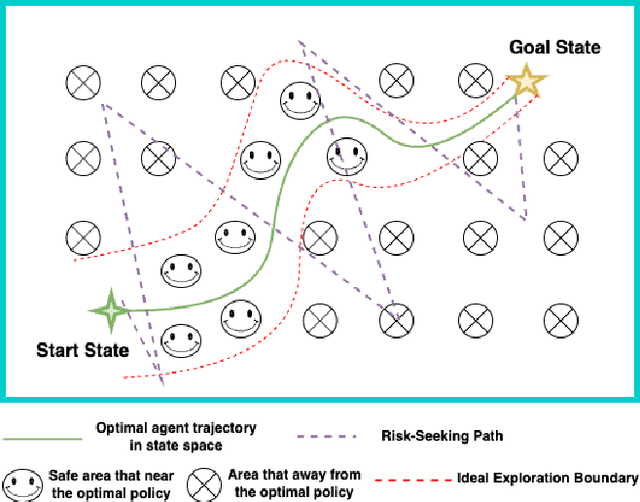
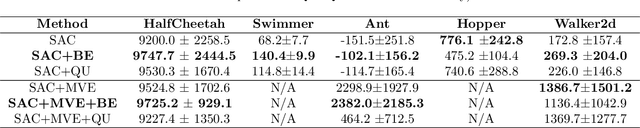
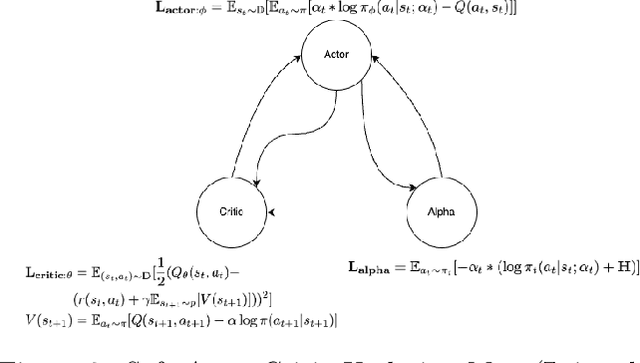
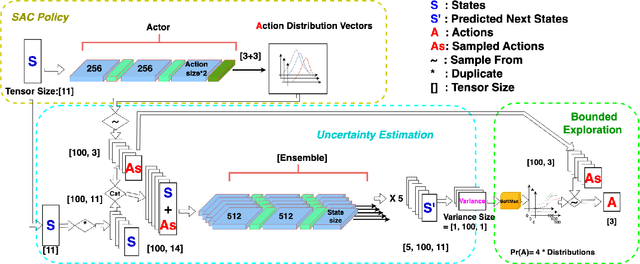
One of the bottlenecks preventing Deep Reinforcement Learning algorithms (DRL) from real-world applications is how to explore the environment and collect informative transitions efficiently. The present paper describes bounded exploration, a novel exploration method that integrates both 'soft' and intrinsic motivation exploration. Bounded exploration notably improved the Soft Actor-Critic algorithm's performance and its model-based extension's converging speed. It achieved the highest score in 6 out of 8 experiments. Bounded exploration presents an alternative method to introduce intrinsic motivations to exploration when the original reward function has strict meanings.
* 8 pages, 7 figures. Accepted as a poster presentation in the Australian Robotics and Automation Association (2023)
Benchmarking Reinforcement Learning Methods for Dexterous Robotic Manipulation with a Three-Fingered Gripper
Aug 27, 2024Reinforcement Learning (RL) training is predominantly conducted in cost-effective and controlled simulation environments. However, the transfer of these trained models to real-world tasks often presents unavoidable challenges. This research explores the direct training of RL algorithms in controlled yet realistic real-world settings for the execution of dexterous manipulation. The benchmarking results of three RL algorithms trained on intricate in-hand manipulation tasks within practical real-world contexts are presented. Our study not only demonstrates the practicality of RL training in authentic real-world scenarios, facilitating direct real-world applications, but also provides insights into the associated challenges and considerations. Additionally, our experiences with the employed experimental methods are shared, with the aim of empowering and engaging fellow researchers and practitioners in this dynamic field of robotics.
Image-Based Deep Reinforcement Learning with Intrinsically Motivated Stimuli: On the Execution of Complex Robotic Tasks
Jul 31, 2024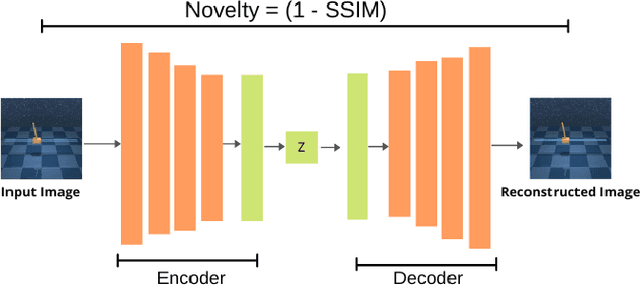
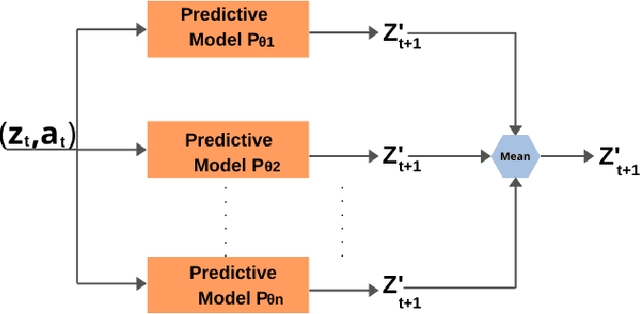
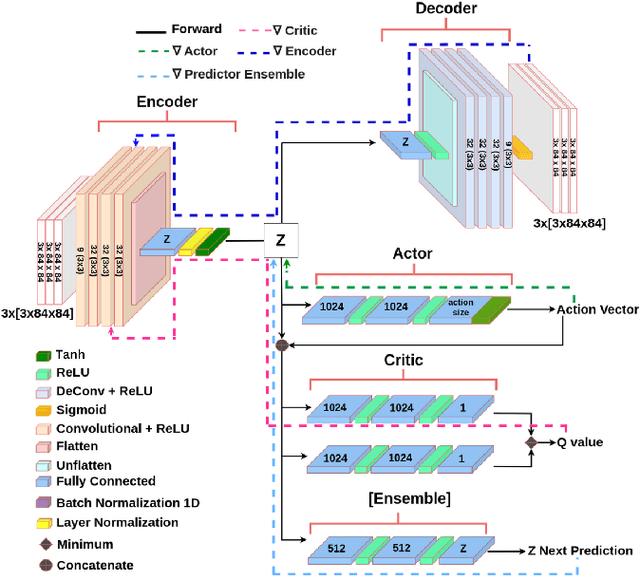
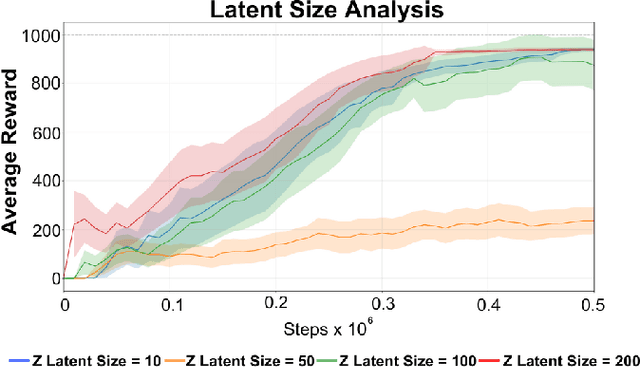
Reinforcement Learning (RL) has been widely used to solve tasks where the environment consistently provides a dense reward value. However, in real-world scenarios, rewards can often be poorly defined or sparse. Auxiliary signals are indispensable for discovering efficient exploration strategies and aiding the learning process. In this work, inspired by intrinsic motivation theory, we postulate that the intrinsic stimuli of novelty and surprise can assist in improving exploration in complex, sparsely rewarded environments. We introduce a novel sample-efficient method able to learn directly from pixels, an image-based extension of TD3 with an autoencoder called \textit{NaSA-TD3}. The experiments demonstrate that NaSA-TD3 is easy to train and an efficient method for tackling complex continuous-control robotic tasks, both in simulated environments and real-world settings. NaSA-TD3 outperforms existing state-of-the-art RL image-based methods in terms of final performance without requiring pre-trained models or human demonstrations.
CTD4 - A Deep Continuous Distributional Actor-Critic Agent with a Kalman Fusion of Multiple Critics
May 04, 2024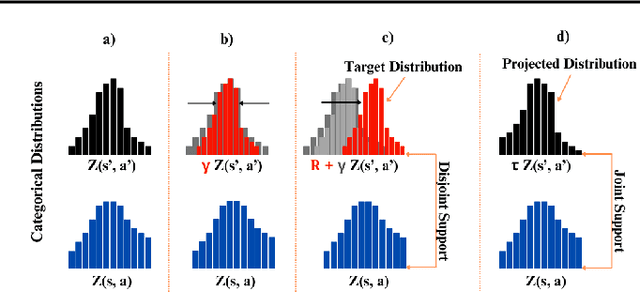
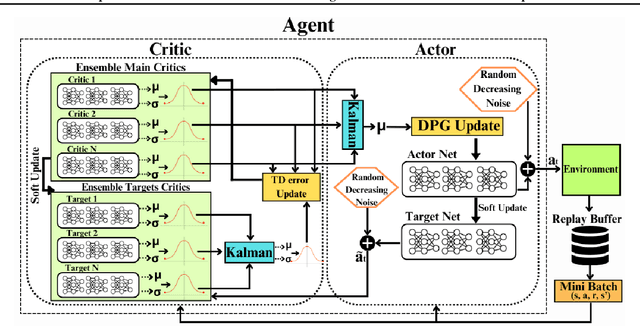
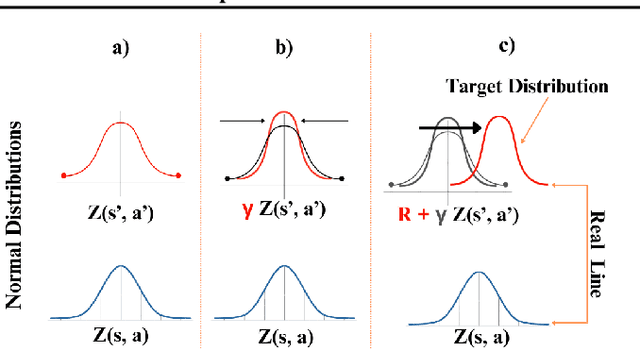
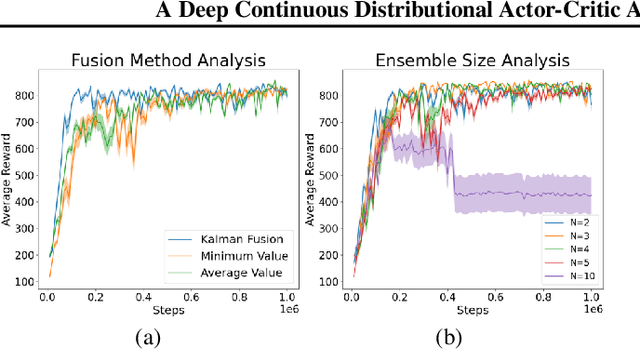
Categorical Distributional Reinforcement Learning (CDRL) has demonstrated superior sample efficiency in learning complex tasks compared to conventional Reinforcement Learning (RL) approaches. However, the practical application of CDRL is encumbered by challenging projection steps, detailed parameter tuning, and domain knowledge. This paper addresses these challenges by introducing a pioneering Continuous Distributional Model-Free RL algorithm tailored for continuous action spaces. The proposed algorithm simplifies the implementation of distributional RL, adopting an actor-critic architecture wherein the critic outputs a continuous probability distribution. Additionally, we propose an ensemble of multiple critics fused through a Kalman fusion mechanism to mitigate overestimation bias. Through a series of experiments, we validate that our proposed method is easy to train and serves as a sample-efficient solution for executing complex continuous-control tasks.
Racing Towards Reinforcement Learning based control of an Autonomous Formula SAE Car
Aug 24, 2023
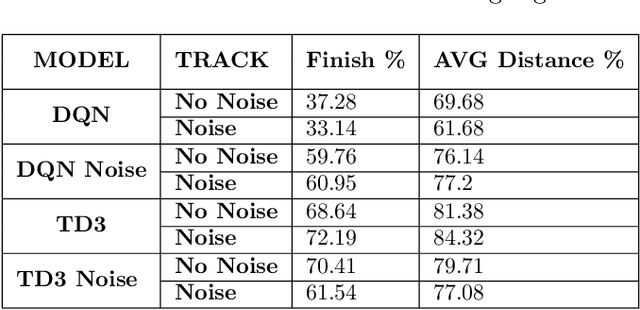


With the rising popularity of autonomous navigation research, Formula Student (FS) events are introducing a Driverless Vehicle (DV) category to their event list. This paper presents the initial investigation into utilising Deep Reinforcement Learning (RL) for end-to-end control of an autonomous FS race car for these competitions. We train two state-of-the-art RL algorithms in simulation on tracks analogous to the full-scale design on a Turtlebot2 platform. The results demonstrate that our approach can successfully learn to race in simulation and then transfer to a real-world racetrack on the physical platform. Finally, we provide insights into the limitations of the presented approach and guidance into the future directions for applying RL toward full-scale autonomous FS racing.