 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCitations as Queries: Source Attribution Using Language Models as Rerankers
Paper and Code
Jun 29, 2023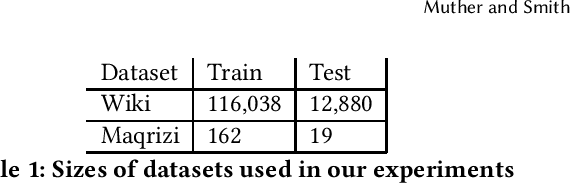


This paper explores new methods for locating the sources used to write a text, by fine-tuning a variety of language models to rerank candidate sources. After retrieving candidates sources using a baseline BM25 retrieval model, a variety of reranking methods are tested to see how effective they are at the task of source attribution. We conduct experiments on two datasets, English Wikipedia and medieval Arabic historical writing, and employ a variety of retrieval and generation based reranking models. In particular, we seek to understand how the degree of supervision required affects the performance of various reranking models. We find that semisupervised methods can be nearly as effective as fully supervised methods while avoiding potentially costly span-level annotation of the target and source documents.