 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVR Based Emotion Recognition Using Deep Multimodal Fusion With Biosignals Across Multiple Anatomical Domains
Paper and Code
Dec 03, 2024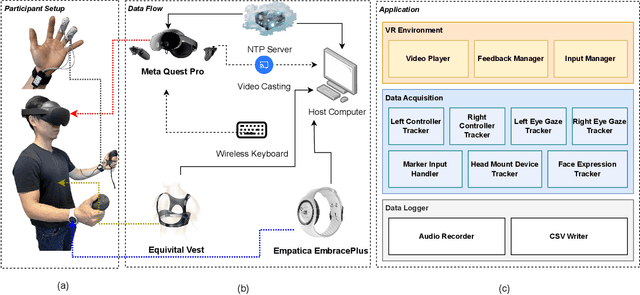
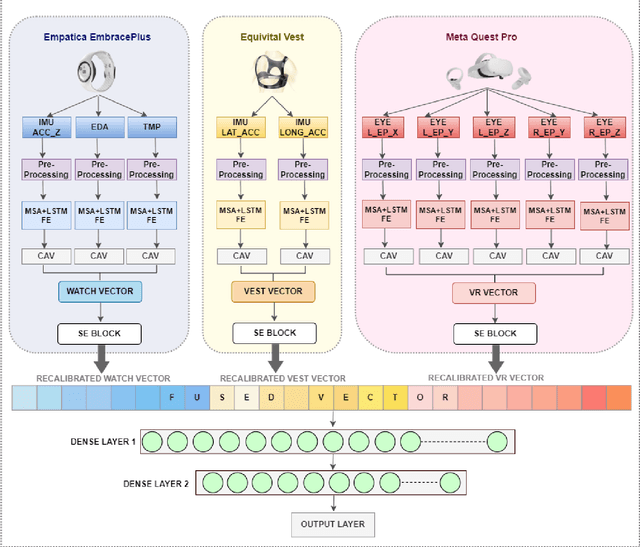
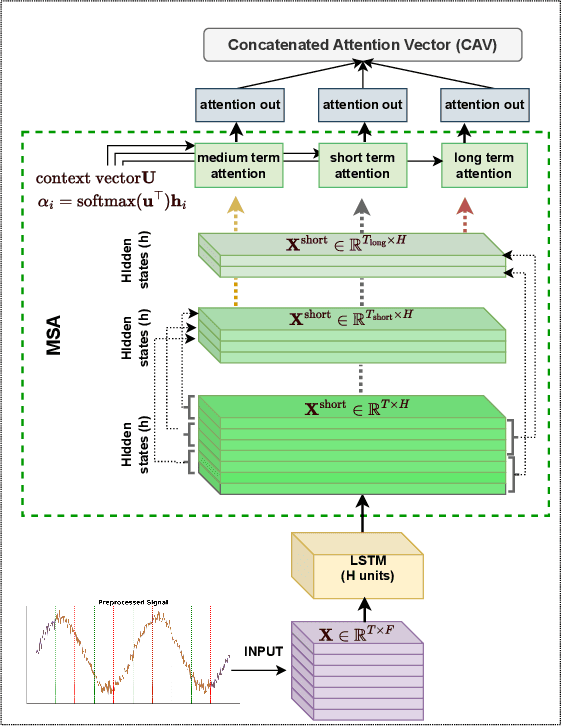
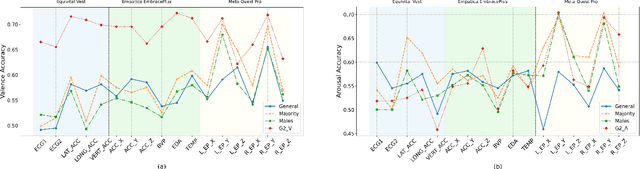
Emotion recognition is significantly enhanced by integrating multimodal biosignals and IMU data from multiple domains. In this paper, we introduce a novel multi-scale attention-based LSTM architecture, combined with Squeeze-and-Excitation (SE) blocks, by leveraging multi-domain signals from the head (Meta Quest Pro VR headset), trunk (Equivital Vest), and peripheral (Empatica Embrace Plus) during affect elicitation via visual stimuli. Signals from 23 participants were recorded, alongside self-assessed valence and arousal ratings after each stimulus. LSTM layers extract features from each modality, while multi-scale attention captures fine-grained temporal dependencies, and SE blocks recalibrate feature importance prior to classification. We assess which domain's signals carry the most distinctive emotional information during VR experiences, identifying key biosignals contributing to emotion detection. The proposed architecture, validated in a user study, demonstrates superior performance in classifying valance and arousal level (high / low), showcasing the efficacy of multi-domain and multi-modal fusion with biosignals (e.g., TEMP, EDA) with IMU data (e.g., accelerometer) for emotion recognition in real-world applications.