 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Quanvolutional Neural Networks Robustness for Speech in Healthcare Applications
Jan 05, 2026Speech-based machine learning systems are sensitive to noise, complicating reliable deployment in emotion recognition and voice pathology detection. We evaluate the robustness of a hybrid quantum machine learning model, quanvolutional neural networks (QNNs) against classical convolutional neural networks (CNNs) under four acoustic corruptions (Gaussian noise, pitch shift, temporal shift, and speed variation) in a clean-train/corrupted-test regime. Using AVFAD (voice pathology) and TESS (speech emotion), we compare three QNN models (Random, Basic, Strongly) to a simple CNN baseline (CNN-Base), ResNet-18 and VGG-16 using accuracy and corruption metrics (CE, mCE, RCE, RmCE), and analyze architectural factors (circuit complexity or depth, convergence) alongside per-emotion robustness. QNNs generally outperform the CNN-Base under pitch shift, temporal shift, and speed variation (up to 22% lower CE/RCE at severe temporal shift), while the CNN-Base remains more resilient to Gaussian noise. Among quantum circuits, QNN-Basic achieves the best overall robustness on AVFAD, and QNN-Random performs strongest on TESS. Emotion-wise, fear is most robust (80-90% accuracy under severe corruptions), neutral can collapse under strong Gaussian noise (5.5% accuracy), and happy is most vulnerable to pitch, temporal, and speed distortions. QNNs also converge up to six times faster than the CNN-Base. To our knowledge, this is a systematic study of QNN robustness for speech under common non-adversarial acoustic corruptions, indicating that shallow entangling quantum front-ends can improve noise resilience while sensitivity to additive noise remains a challenge.
Enhancing Federated Learning Through Secure Cluster-Weighted Client Aggregation
Mar 29, 2025Federated learning (FL) has emerged as a promising paradigm in machine learning, enabling collaborative model training across decentralized devices without the need for raw data sharing. In FL, a global model is trained iteratively on local datasets residing on individual devices, each contributing to the model's improvement. However, the heterogeneous nature of these local datasets, stemming from diverse user behaviours, device capabilities, and data distributions, poses a significant challenge. The inherent heterogeneity in federated learning gives rise to various issues, including model performance discrepancies, convergence challenges, and potential privacy concerns. As the global model progresses through rounds of training, the disparities in local data quality and quantity can impede the overall effectiveness of federated learning systems. Moreover, maintaining fairness and privacy across diverse user groups becomes a paramount concern. To address this issue, this paper introduces a novel FL framework, ClusterGuardFL, that employs dissimilarity scores, k-means clustering, and reconciliation confidence scores to dynamically assign weights to client updates. The dissimilarity scores between global and local models guide the formation of clusters, with cluster size influencing the weight allocation. Within each cluster, a reconciliation confidence score is calculated for individual data points, and a softmax layer generates customized weights for clients. These weights are utilized in the aggregation process, enhancing the model's robustness and privacy. Experimental results demonstrate the efficacy of the proposed approach in achieving improved model performance in diverse datasets.
VR Based Emotion Recognition Using Deep Multimodal Fusion With Biosignals Across Multiple Anatomical Domains
Dec 03, 2024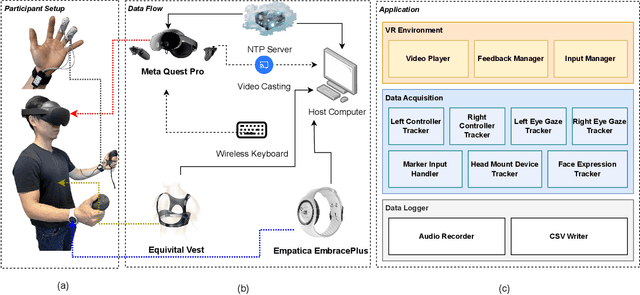
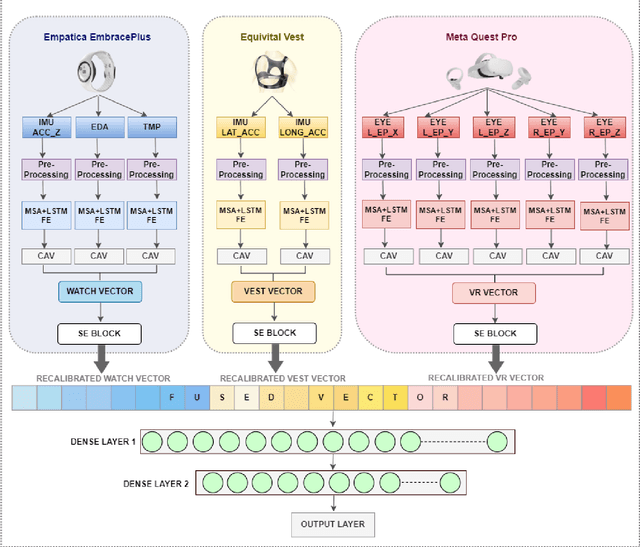
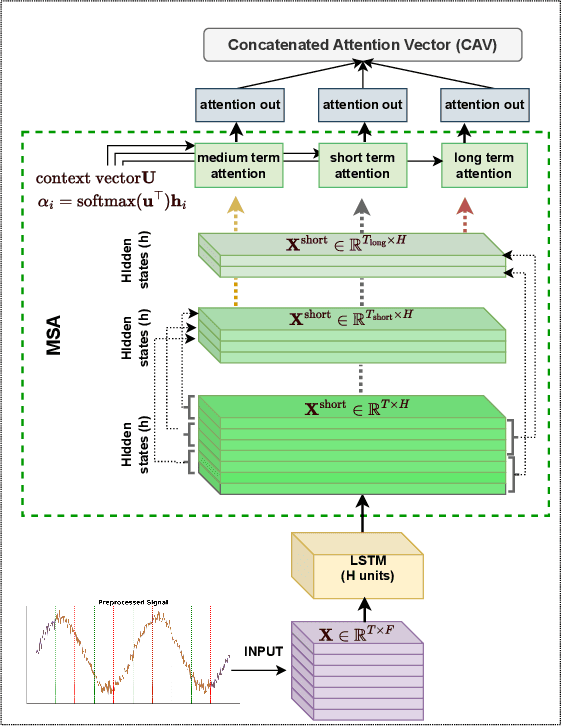
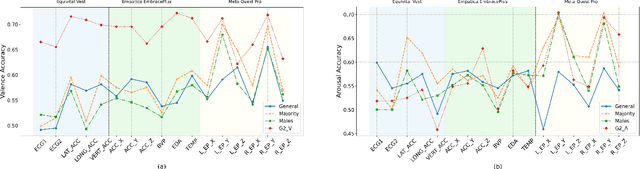
Emotion recognition is significantly enhanced by integrating multimodal biosignals and IMU data from multiple domains. In this paper, we introduce a novel multi-scale attention-based LSTM architecture, combined with Squeeze-and-Excitation (SE) blocks, by leveraging multi-domain signals from the head (Meta Quest Pro VR headset), trunk (Equivital Vest), and peripheral (Empatica Embrace Plus) during affect elicitation via visual stimuli. Signals from 23 participants were recorded, alongside self-assessed valence and arousal ratings after each stimulus. LSTM layers extract features from each modality, while multi-scale attention captures fine-grained temporal dependencies, and SE blocks recalibrate feature importance prior to classification. We assess which domain's signals carry the most distinctive emotional information during VR experiences, identifying key biosignals contributing to emotion detection. The proposed architecture, validated in a user study, demonstrates superior performance in classifying valance and arousal level (high / low), showcasing the efficacy of multi-domain and multi-modal fusion with biosignals (e.g., TEMP, EDA) with IMU data (e.g., accelerometer) for emotion recognition in real-world applications.