 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthTools: A Framework for Scaling Synthetic Tools for Agent Development
Nov 11, 2025



AI agents increasingly rely on external tools to solve complex, long-horizon tasks. Advancing such agents requires reproducible evaluation and large-scale training in controllable, diverse, and realistic tool-use environments. However, real-world APIs are limited in availability, domain coverage, and stability, often requiring access keys and imposing rate limits, which render them impractical for stable evaluation or scalable training. To address these challenges, we introduce SynthTools, a flexible and scalable framework for generating synthetic tool ecosystems. Our framework consists of three core components: Tool Generation for automatic and scalable creation of diverse tools, Tool Simulation to emulate realistic tool behaviors, and Tool Audit to ensure correctness and consistency of tool simulation. To illustrate its scalability, we show that SynthTools can readily produce toolsets that span twice as many domains and twice as many tools per domain as prior work. Furthermore, the tool simulation and tool audit components demonstrate strong reliability, achieving $94\%$ and $99\%$ accuracy respectively. Finally, we construct downstream tasks from the generated tools that even state-of-the-art models struggle to complete. By enabling scalable, diverse, and reliable tool ecosystems, SynthTools provides a practical path toward large-scale training and stable evaluation of tool-use agents. Our code is available at https://github.com/namkoong-lab/SynthTools.
Speculative Actions: A Lossless Framework for Faster Agentic Systems
Oct 05, 2025Despite growing interest in AI agents across industry and academia, their execution in an environment is often slow, hampering training, evaluation, and deployment. For example, a game of chess between two state-of-the-art agents may take hours. A critical bottleneck is that agent behavior unfolds sequentially: each action requires an API call, and these calls can be time-consuming. Inspired by speculative execution in microprocessors and speculative decoding in LLM inference, we propose speculative actions, a lossless framework for general agentic systems that predicts likely actions using faster models, enabling multiple steps to be executed in parallel. We evaluate this framework across three agentic environments: gaming, e-commerce, web search, and a "lossy" extension for an operating systems environment. In all cases, speculative actions achieve substantial accuracy in next-action prediction (up to 55%), translating into significant reductions in end-to-end latency. Moreover, performance can be further improved through stronger guessing models, top-K action prediction, multi-step speculation, and uncertainty-aware optimization, opening a promising path toward deploying low-latency agentic systems in the real world.
AI Agents for Web Testing: A Case Study in the Wild
Sep 05, 2025Automated web testing plays a critical role in ensuring high-quality user experiences and delivering business value. Traditional approaches primarily focus on code coverage and load testing, but often fall short of capturing complex user behaviors, leaving many usability issues undetected. The emergence of large language models (LLM) and AI agents opens new possibilities for web testing by enabling human-like interaction with websites and a general awareness of common usability problems. In this work, we present WebProber, a prototype AI agent-based web testing framework. Given a URL, WebProber autonomously explores the website, simulating real user interactions, identifying bugs and usability issues, and producing a human-readable report. We evaluate WebProber through a case study of 120 academic personal websites, where it uncovered 29 usability issues--many of which were missed by traditional tools. Our findings highlight agent-based testing as a promising direction while outlining directions for developing next-generation, user-centered testing frameworks.
Differences-in-Neighbors for Network Interference in Experiments
Mar 04, 2025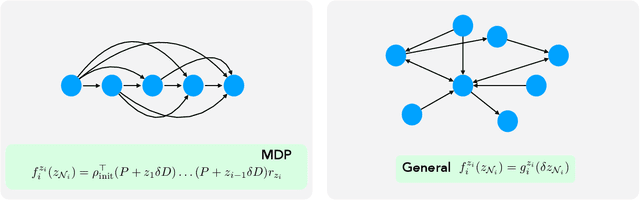

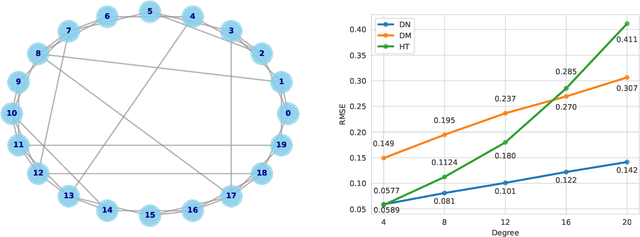
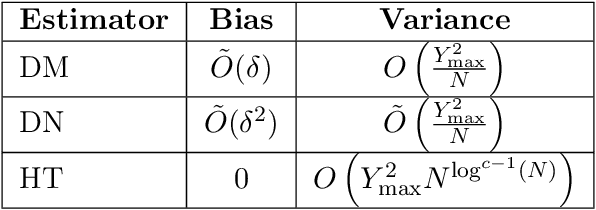
Experiments in online platforms frequently suffer from network interference, in which a treatment applied to a given unit affects outcomes for other units connected via the platform. This SUTVA violation biases naive approaches to experiment design and estimation. A common solution is to reduce interference by clustering connected units, and randomizing treatments at the cluster level, typically followed by estimation using one of two extremes: either a simple difference-in-means (DM) estimator, which ignores remaining interference; or an unbiased Horvitz-Thompson (HT) estimator, which eliminates interference at great cost in variance. Even combined with clustered designs, this presents a limited set of achievable bias variance tradeoffs. We propose a new estimator, dubbed Differences-in-Neighbors (DN), designed explicitly to mitigate network interference. Compared to DM estimators, DN achieves bias second order in the magnitude of the interference effect, while its variance is exponentially smaller than that of HT estimators. When combined with clustered designs, DN offers improved bias-variance tradeoffs not achievable by existing approaches. Empirical evaluations on a large-scale social network and a city-level ride-sharing simulator demonstrate the superior performance of DN in experiments at practical scale.
PersonalLLM: Tailoring LLMs to Individual Preferences
Sep 30, 2024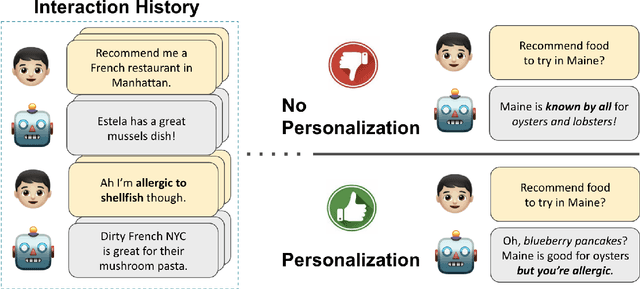



As LLMs become capable of complex tasks, there is growing potential for personalized interactions tailored to the subtle and idiosyncratic preferences of the user. We present a public benchmark, PersonalLLM, focusing on adapting LLMs to provide maximal benefits for a particular user. Departing from existing alignment benchmarks that implicitly assume uniform preferences, we curate open-ended prompts paired with many high-quality answers over which users would be expected to display heterogeneous latent preferences. Instead of persona-prompting LLMs based on high-level attributes (e.g., user's race or response length), which yields homogeneous preferences relative to humans, we develop a method that can simulate a large user base with diverse preferences from a set of pre-trained reward models. Our dataset and generated personalities offer an innovative testbed for developing personalization algorithms that grapple with continual data sparsity--few relevant feedback from the particular user--by leveraging historical data from other (similar) users. We explore basic in-context learning and meta-learning baselines to illustrate the utility of PersonalLLM and highlight the need for future methodological development. Our dataset is available at https://huggingface.co/datasets/namkoong-lab/PersonalLLM
Pre-training and in-context learning IS Bayesian inference a la De Finetti
Aug 06, 2024



Accurately gauging uncertainty on the underlying environment is a longstanding goal of intelligent systems. We characterize which latent concepts pre-trained sequence models are naturally able to reason with. We go back to De Finetti's predictive view of Bayesian reasoning: instead of modeling latent parameters through priors and likelihoods like topic models do, De Finetti has long advocated for modeling exchangeable (permutation invariant) sequences of observables. According to this view, pre-training autoregressive models formulates informed beliefs based on prior observations ("empirical Bayes"), and forward generation is a simulated instantiation of an environment ("posterior inference"). This connection allows extending in-context learning (ICL) beyond predictive settings, highlighting sequence models' ability to perform explicit statistical inference. In particular, we show the sequence prediction loss over exchangeable documents controls performance on downstream tasks where uncertainty quantification is key. Empirically, we propose and demonstrate several approaches for encoding exchangeability in sequence model architectures: data augmentation, regularization, and causal masking.