 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating bias in calibration error estimation
Paper and Code
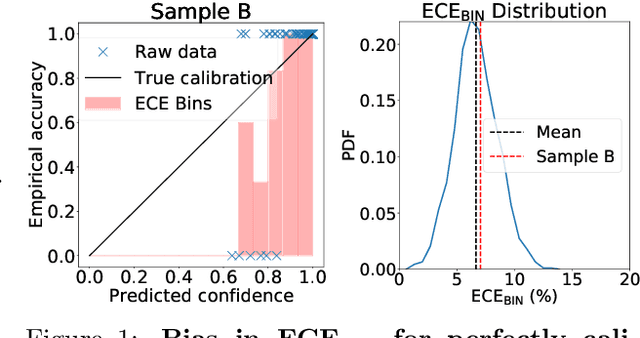
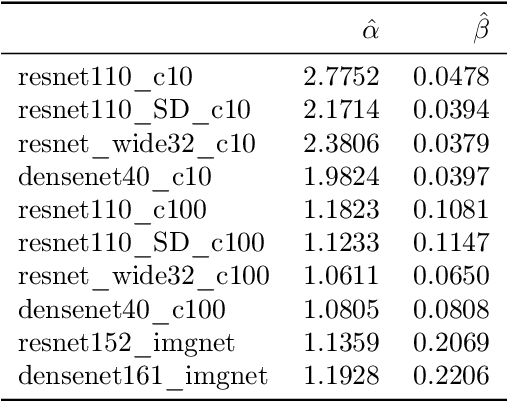
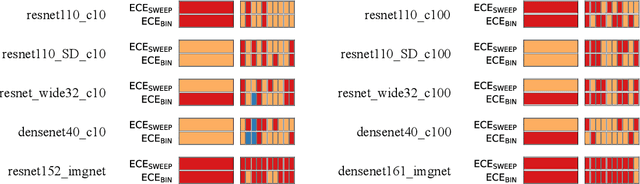
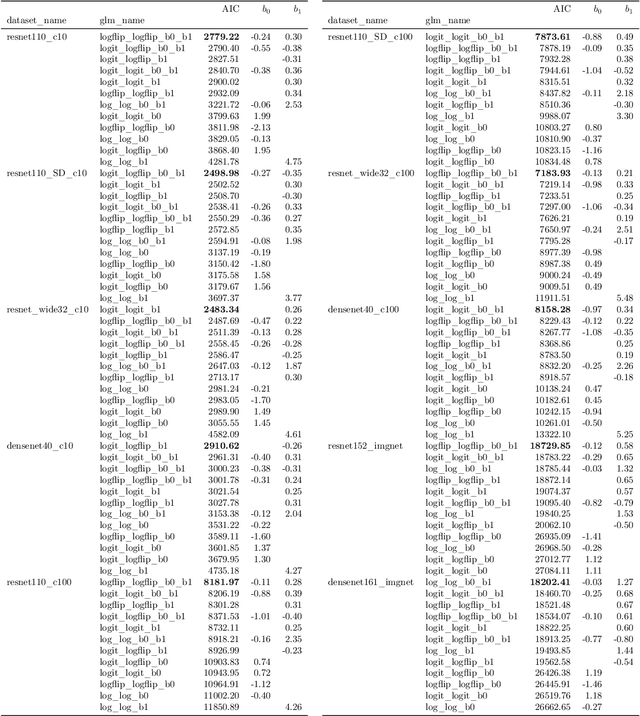
Building reliable machine learning systems requires that we correctly understand their level of confidence. Calibration focuses on measuring the degree of accuracy in a model's confidence and most research in calibration focuses on techniques to improve an empirical estimate of calibration error, ECE_bin. Using simulation, we show that ECE_bin can systematically underestimate or overestimate the true calibration error depending on the nature of model miscalibration, the size of the evaluation data set, and the number of bins. Critically, ECE_bin is more strongly biased for perfectly calibrated models. We propose a simple alternative calibration error metric, ECE_sweep, in which the number of bins is chosen to be as large as possible while preserving monotonicity in the calibration function. Evaluating our measure on distributions fit to neural network confidence scores on CIFAR-10, CIFAR-100, and ImageNet, we show that ECE_sweep produces a less biased estimator of calibration error and therefore should be used by any researcher wishing to evaluate the calibration of models trained on similar datasets.