 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Convolutional Inverse Graphics Network
Paper and Code

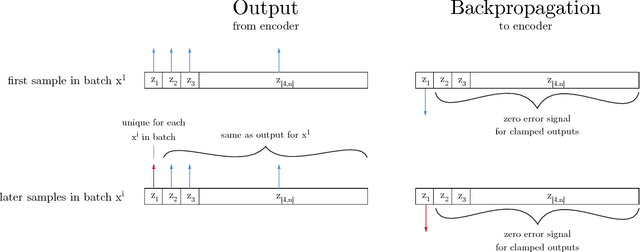

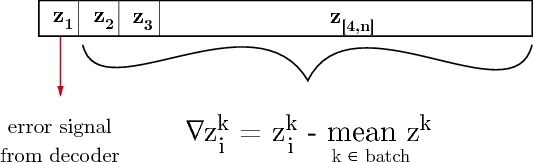
This paper presents the Deep Convolution Inverse Graphics Network (DC-IGN), a model that learns an interpretable representation of images. This representation is disentangled with respect to transformations such as out-of-plane rotations and lighting variations. The DC-IGN model is composed of multiple layers of convolution and de-convolution operators and is trained using the Stochastic Gradient Variational Bayes (SGVB) algorithm. We propose a training procedure to encourage neurons in the graphics code layer to represent a specific transformation (e.g. pose or light). Given a single input image, our model can generate new images of the same object with variations in pose and lighting. We present qualitative and quantitative results of the model's efficacy at learning a 3D rendering engine.