 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Post-Training Recipes for Multimodal Time-Series Forecasting
May 28, 2026Time-Series Foundation Models (TSFMs) excel at zero-shot unimodal forecasting using numerical data, but unlike LLMs they cannot consume multimodal, non-numerical context that often shape real-world trajectories. In this work, we bridge this gap and argue for a multimodal time-series forecasting approach that post-trains LLMs to act as context-guided revisors over strong numerical TSFM priors. We introduce PostTime, a post-training recipe combining Supervised Fine-Tuning (SFT) and Reinforcement Learning with Verifiable Rewards (RLVR), along with a methodology to generate automated reasoning traces for forecast revisions. PostTime teaches an LLM to generate context-conditioned forecast interventions -- decisions to revise, preserve, or ignore the TSFM prior based on the multimodal context. We evaluate this approach on the TimesX multimodal forecasting benchmark using a Gemma-3-4B LLM and TimesFM-2.5 TSFM, and show that it significantly outperforms standalone TSFMs, LLM-only baselines, and existing multimodal forecasting approaches.
Multi-Modal Forecaster: Jointly Predicting Time Series and Textual Data
Nov 21, 2024Current forecasting approaches are largely unimodal and ignore the rich textual data that often accompany the time series due to lack of well-curated multimodal benchmark dataset. In this work, we develop TimeText Corpus (TTC), a carefully curated, time-aligned text and time dataset for multimodal forecasting. Our dataset is composed of sequences of numbers and text aligned to timestamps, and includes data from two different domains: climate science and healthcare. Our data is a significant contribution to the rare selection of available multimodal datasets. We also propose the Hybrid Multi-Modal Forecaster (Hybrid-MMF), a multimodal LLM that jointly forecasts both text and time series data using shared embeddings. However, contrary to our expectations, our Hybrid-MMF model does not outperform existing baselines in our experiments. This negative result highlights the challenges inherent in multimodal forecasting. Our code and data are available at https://github.com/Rose-STL-Lab/Multimodal_ Forecasting.
In-Context Fine-Tuning for Time-Series Foundation Models
Oct 31, 2024



Motivated by the recent success of time-series foundation models for zero-shot forecasting, we present a methodology for $\textit{in-context fine-tuning}$ of a time-series foundation model. In particular, we design a pretrained foundation model that can be prompted (at inference time) with multiple time-series examples, in order to forecast a target time-series into the future. Our foundation model is specifically trained to utilize examples from multiple related time-series in its context window (in addition to the history of the target time-series) to help it adapt to the specific distribution of the target domain at inference time. We show that such a foundation model that uses in-context examples at inference time can obtain much better performance on popular forecasting benchmarks compared to supervised deep learning methods, statistical models, as well as other time-series foundation models. Interestingly, our in-context fine-tuning approach even rivals the performance of a foundation model that is explicitly fine-tuned on the target domain.
A Combinatorial Approach to Robust PCA
Nov 28, 2023We study the problem of recovering Gaussian data under adversarial corruptions when the noises are low-rank and the corruptions are on the coordinate level. Concretely, we assume that the Gaussian noises lie in an unknown $k$-dimensional subspace $U \subseteq \mathbb{R}^d$, and $s$ randomly chosen coordinates of each data point fall into the control of an adversary. This setting models the scenario of learning from high-dimensional yet structured data that are transmitted through a highly-noisy channel, so that the data points are unlikely to be entirely clean. Our main result is an efficient algorithm that, when $ks^2 = O(d)$, recovers every single data point up to a nearly-optimal $\ell_1$ error of $\tilde O(ks/d)$ in expectation. At the core of our proof is a new analysis of the well-known Basis Pursuit (BP) method for recovering a sparse signal, which is known to succeed under additional assumptions (e.g., incoherence or the restricted isometry property) on the underlying subspace $U$. In contrast, we present a novel approach via studying a natural combinatorial problem and show that, over the randomness in the support of the sparse signal, a high-probability error bound is possible even if the subspace $U$ is arbitrary.
Transformers can optimally learn regression mixture models
Nov 14, 2023
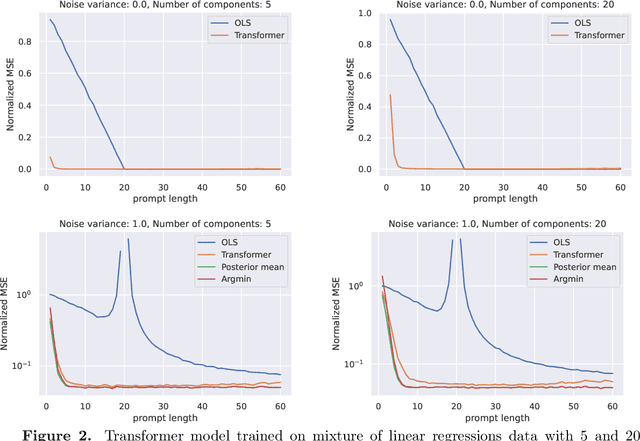


Mixture models arise in many regression problems, but most methods have seen limited adoption partly due to these algorithms' highly-tailored and model-specific nature. On the other hand, transformers are flexible, neural sequence models that present the intriguing possibility of providing general-purpose prediction methods, even in this mixture setting. In this work, we investigate the hypothesis that transformers can learn an optimal predictor for mixtures of regressions. We construct a generative process for a mixture of linear regressions for which the decision-theoretic optimal procedure is given by data-driven exponential weights on a finite set of parameters. We observe that transformers achieve low mean-squared error on data generated via this process. By probing the transformer's output at inference time, we also show that transformers typically make predictions that are close to the optimal predictor. Our experiments also demonstrate that transformers can learn mixtures of regressions in a sample-efficient fashion and are somewhat robust to distribution shifts. We complement our experimental observations by proving constructively that the decision-theoretic optimal procedure is indeed implementable by a transformer.
A decoder-only foundation model for time-series forecasting
Oct 14, 2023



Motivated by recent advances in large language models for Natural Language Processing (NLP), we design a time-series foundation model for forecasting whose out-of-the-box zero-shot performance on a variety of public datasets comes close to the accuracy of state-of-the-art supervised forecasting models for each individual dataset. Our model is based on pretraining a patched-decoder style attention model on a large time-series corpus, and can work well across different forecasting history lengths, prediction lengths and temporal granularities.
Linear Regression using Heterogeneous Data Batches
Sep 05, 2023


In many learning applications, data are collected from multiple sources, each providing a \emph{batch} of samples that by itself is insufficient to learn its input-output relationship. A common approach assumes that the sources fall in one of several unknown subgroups, each with an unknown input distribution and input-output relationship. We consider one of this setup's most fundamental and important manifestations where the output is a noisy linear combination of the inputs, and there are $k$ subgroups, each with its own regression vector. Prior work~\cite{kong2020meta} showed that with abundant small-batches, the regression vectors can be learned with only few, $\tilde\Omega( k^{3/2})$, batches of medium-size with $\tilde\Omega(\sqrt k)$ samples each. However, the paper requires that the input distribution for all $k$ subgroups be isotropic Gaussian, and states that removing this assumption is an ``interesting and challenging problem". We propose a novel gradient-based algorithm that improves on the existing results in several ways. It extends the applicability of the algorithm by: (1) allowing the subgroups' underlying input distributions to be different, unknown, and heavy-tailed; (2) recovering all subgroups followed by a significant proportion of batches even for infinite $k$; (3) removing the separation requirement between the regression vectors; (4) reducing the number of batches and allowing smaller batch sizes.
Long-term Forecasting with TiDE: Time-series Dense Encoder
Apr 27, 2023



Recent work has shown that simple linear models can outperform several Transformer based approaches in long term time-series forecasting. Motivated by this, we propose a Multi-layer Perceptron (MLP) based encoder-decoder model, Time-series Dense Encoder (TiDE), for long-term time-series forecasting that enjoys the simplicity and speed of linear models while also being able to handle covariates and non-linear dependencies. Theoretically, we prove that the simplest linear analogue of our model can achieve near optimal error rate for linear dynamical systems (LDS) under some assumptions. Empirically, we show that our method can match or outperform prior approaches on popular long-term time-series forecasting benchmarks while being 5-10x faster than the best Transformer based model.
Efficient List-Decodable Regression using Batches
Nov 23, 2022We begin the study of list-decodable linear regression using batches. In this setting only an $\alpha \in (0,1]$ fraction of the batches are genuine. Each genuine batch contains $\ge n$ i.i.d. samples from a common unknown distribution and the remaining batches may contain arbitrary or even adversarial samples. We derive a polynomial time algorithm that for any $n\ge \tilde \Omega(1/\alpha)$ returns a list of size $\mathcal O(1/\alpha^2)$ such that one of the items in the list is close to the true regression parameter. The algorithm requires only $\tilde{\mathcal{O}}(d/\alpha^2)$ genuine batches and works under fairly general assumptions on the distribution. The results demonstrate the utility of batch structure, which allows for the first polynomial time algorithm for list-decodable regression, which may be impossible for the non-batch setting, as suggested by a recent SQ lower bound \cite{diakonikolas2021statistical} for the non-batch setting.
Trimmed Maximum Likelihood Estimation for Robust Learning in Generalized Linear Models
Jun 09, 2022We study the problem of learning generalized linear models under adversarial corruptions. We analyze a classical heuristic called the iterative trimmed maximum likelihood estimator which is known to be effective against label corruptions in practice. Under label corruptions, we prove that this simple estimator achieves minimax near-optimal risk on a wide range of generalized linear models, including Gaussian regression, Poisson regression and Binomial regression. Finally, we extend the estimator to the more challenging setting of label and covariate corruptions and demonstrate its robustness and optimality in that setting as well.