 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Learning Mixture of Linear Regressions in the Non-Realizable Setting
Paper and Code
May 26, 2022
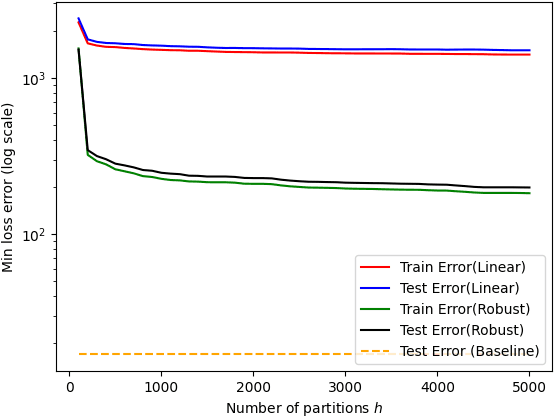


While mixture of linear regressions (MLR) is a well-studied topic, prior works usually do not analyze such models for prediction error. In fact, {\em prediction} and {\em loss} are not well-defined in the context of mixtures. In this paper, first we show that MLR can be used for prediction where instead of predicting a label, the model predicts a list of values (also known as {\em list-decoding}). The list size is equal to the number of components in the mixture, and the loss function is defined to be minimum among the losses resulted by all the component models. We show that with this definition, a solution of the empirical risk minimization (ERM) achieves small probability of prediction error. This begs for an algorithm to minimize the empirical risk for MLR, which is known to be computationally hard. Prior algorithmic works in MLR focus on the {\em realizable} setting, i.e., recovery of parameters when data is probabilistically generated by a mixed linear (noisy) model. In this paper we show that a version of the popular alternating minimization (AM) algorithm finds the best fit lines in a dataset even when a realizable model is not assumed, under some regularity conditions on the dataset and the initial points, and thereby provides a solution for the ERM. We further provide an algorithm that runs in polynomial time in the number of datapoints, and recovers a good approximation of the best fit lines. The two algorithms are experimentally compared.