 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
Dec 19, 2025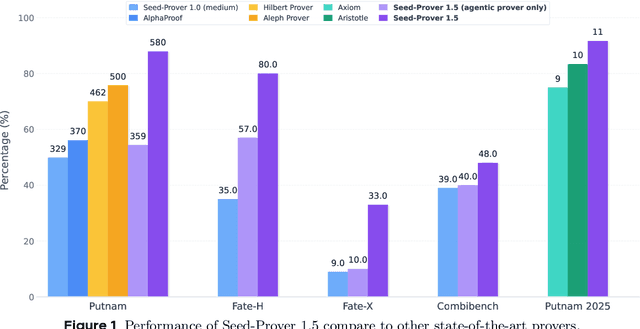

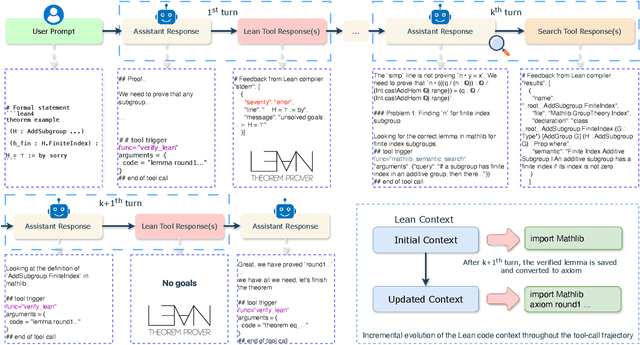

Large language models have recently made significant progress to generate rigorous mathematical proofs. In contrast, utilizing LLMs for theorem proving in formal languages (such as Lean) remains challenging and computationally expensive, particularly when addressing problems at the undergraduate level and beyond. In this work, we present \textbf{Seed-Prover 1.5}, a formal theorem-proving model trained via large-scale agentic reinforcement learning, alongside an efficient test-time scaling (TTS) workflow. Through extensive interactions with Lean and other tools, the model continuously accumulates experience during the RL process, substantially enhancing the capability and efficiency of formal theorem proving. Furthermore, leveraging recent advancements in natural language proving, our TTS workflow efficiently bridges the gap between natural and formal languages. Compared to state-of-the-art methods, Seed-Prover 1.5 achieves superior performance with a smaller compute budget. It solves \textbf{88\% of PutnamBench} (undergraduate-level), \textbf{80\% of Fate-H} (graduate-level), and \textbf{33\% of Fate-X} (PhD-level) problems. Notably, using our system, we solved \textbf{11 out of 12 problems} from Putnam 2025 within 9 hours. Our findings suggest that scaling learning from experience, driven by high-quality formal feedback, holds immense potential for the future of formal mathematical reasoning.
Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Aug 01, 2025LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1\%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50\% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
Heimdall: test-time scaling on the generative verification
Apr 16, 2025An AI system can create and maintain knowledge only to the extent that it can verify that knowledge itself. Recent work on long Chain-of-Thought reasoning has demonstrated great potential of LLMs on solving competitive problems, but their verification ability remains to be weak and not sufficiently investigated. In this paper, we propose Heimdall, the long CoT verification LLM that can accurately judge the correctness of solutions. With pure reinforcement learning, we boost the verification accuracy from 62.5% to 94.5% on competitive math problems. By scaling with repeated sampling, the accuracy further increases to 97.5%. Through human evaluation, Heimdall demonstrates impressive generalization capabilities, successfully detecting most issues in challenging math proofs, the type of which is not included during training. Furthermore, we propose Pessimistic Verification to extend the functionality of Heimdall to scaling up the problem solving. It calls Heimdall to judge the solutions from a solver model and based on the pessimistic principle, selects the most likely correct solution with the least uncertainty. Taking DeepSeek-R1-Distill-Qwen-32B as the solver model, Pessimistic Verification improves the solution accuracy on AIME2025 from 54.2% to 70.0% with 16x compute budget and to 83.3% with more compute budget. With the stronger solver Gemini 2.5 Pro, the score reaches 93.0%. Finally, we prototype an automatic knowledge discovery system, a ternary system where one poses questions, another provides solutions, and the third verifies the solutions. Using the data synthesis work NuminaMath for the first two components, Heimdall effectively identifies problematic records within the dataset and reveals that nearly half of the data is flawed, which interestingly aligns with the recent ablation studies from NuminaMath.
Flaming-hot Initiation with Regular Execution Sampling for Large Language Models
Oct 28, 2024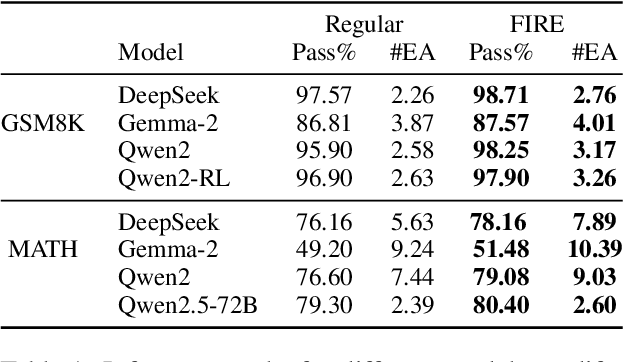


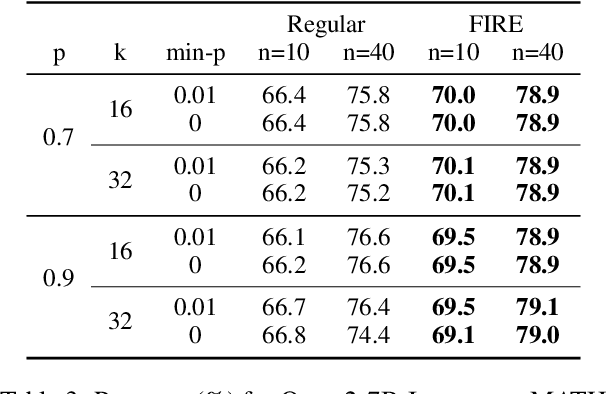
Since the release of ChatGPT, large language models (LLMs) have demonstrated remarkable capabilities across various domains. A key challenge in developing these general capabilities is efficiently sourcing diverse, high-quality data. This becomes especially critical in reasoning-related tasks with sandbox checkers, such as math or code, where the goal is to generate correct solutions to specific problems with higher probability. In this work, we introduce Flaming-hot Initiation with Regular Execution (FIRE) sampling, a simple yet highly effective method to efficiently find good responses. Our empirical findings show that FIRE sampling enhances inference-time generation quality and also benefits training in the alignment stage. Furthermore, we explore how FIRE sampling improves performance by promoting diversity and analyze the impact of employing FIRE at different positions within a response.
Process Supervision-Guided Policy Optimization for Code Generation
Oct 23, 2024
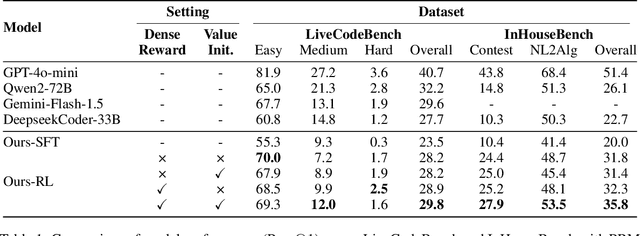

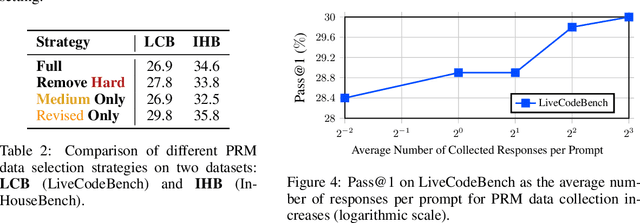
Reinforcement Learning (RL) with unit test feedback has enhanced large language models (LLMs) code generation, but relies on sparse rewards provided only after complete code evaluation, limiting learning efficiency and incremental improvements. When generated code fails all unit tests, no learning signal is received, hindering progress on complex tasks. To address this, we propose a Process Reward Model (PRM) that delivers dense, line-level feedback on code correctness during generation, mimicking human code refinement and providing immediate guidance. We explore various strategies for training PRMs and integrating them into the RL framework, finding that using PRMs both as dense rewards and for value function initialization significantly boosts performance. Our approach increases our in-house LLM's pass rate from 28.2% to 29.8% on LiveCodeBench and from 31.8% to 35.8% on our internal benchmark. Our experimental results highlight the effectiveness of PRMs in enhancing RL-driven code generation, especially for long-horizon scenarios.
Generic and Robust Root Cause Localization for Multi-Dimensional Data in Online Service Systems
May 05, 2023



Localizing root causes for multi-dimensional data is critical to ensure online service systems' reliability. When a fault occurs, only the measure values within specific attribute combinations are abnormal. Such attribute combinations are substantial clues to the underlying root causes and thus are called root causes of multidimensional data. This paper proposes a generic and robust root cause localization approach for multi-dimensional data, PSqueeze. We propose a generic property of root cause for multi-dimensional data, generalized ripple effect (GRE). Based on it, we propose a novel probabilistic cluster method and a robust heuristic search method. Moreover, we identify the importance of determining external root causes and propose an effective method for the first time in literature. Our experiments on two real-world datasets with 5400 faults show that the F1-score of PSqueeze outperforms baselines by 32.89%, while the localization time is around 10 seconds across all cases. The F1-score in determining external root causes of PSqueeze achieves 0.90. Furthermore, case studies in several production systems demonstrate that PSqueeze is helpful to fault diagnosis in the real world.