 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Deepening Sampling for Large Language Models
Paper and Code
Feb 08, 2025
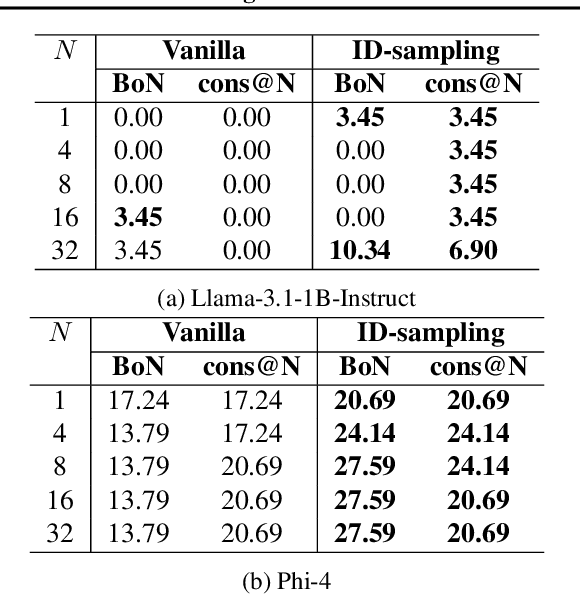
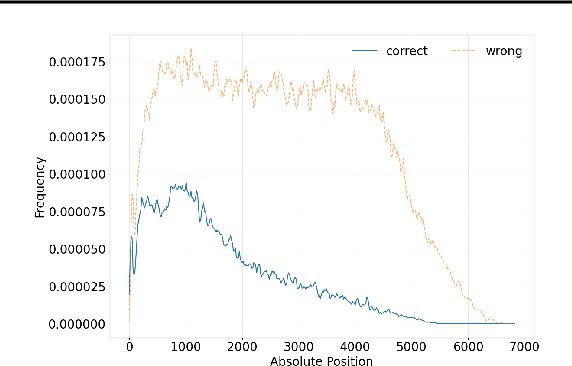
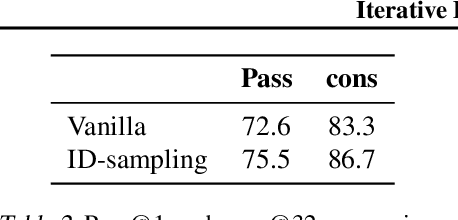
The recent release of OpenAI's o1 models and other similar frameworks showcasing test-time scaling laws has demonstrated their exceptional capability to tackle complex reasoning tasks. Inspired by this, subsequent research has revealed that such test-time scaling laws hinge on the model's ability to search both within a single response (intra-response) and across multiple responses (inter-response) during training. Crucially, beyond selecting a single optimal response, the model must also develop robust self-correction capabilities within its own outputs. However, training models to achieve effective self-evaluation and self-correction remains a significant challenge, heavily dependent on the quality of self-reflection data. In this paper, we address this challenge by focusing on enhancing the quality of self-reflection data generation for complex problem-solving, which can subsequently improve the training of next-generation large language models (LLMs). Specifically, we explore how manually triggering a model's self-correction mechanisms can improve performance on challenging reasoning tasks. To this end, we propose a novel iterative deepening sampling algorithm framework designed to enhance self-correction and generate higher-quality samples. Through extensive experiments on Math500 and AIME benchmarks, we demonstrate that our method achieves a higher success rate on difficult tasks and provide detailed ablation studies to analyze its effectiveness across diverse settings.