 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboLight: A Dataset with Linearly Composable Illumination for Robotic Manipulation
Mar 04, 2026In this paper, we introduce RoboLight, the first real-world robotic manipulation dataset capturing synchronized episodes under systematically varied lighting conditions. RoboLight consists of two components. (a) RoboLight-Real contains 2,800 real-world episodes collected in our custom Light Cube setup, a calibrated system equipped with eight programmable RGB LED lights. It includes structured illumination variation along three independently controlled dimensions: color, direction, and intensity. Each dimension is paired with a dedicated task featuring objects of diverse geometries and materials to induce perceptual challenges. All image data are recorded in high-dynamic-range (HDR) format to preserve radiometric accuracy. Leveraging the linearity of light transport, we introduce (b) RoboLight-Synthetic, comprising 196,000 episodes synthesized through interpolation in the HDR image space of RoboLight-Real. In principle, RoboLight-Synthetic can be arbitrarily expanded by refining the interpolation granularity. We further verify the dataset quality through qualitative analysis and real-world policy roll-outs, analyzing task difficulty, distributional diversity, and the effectiveness of synthesized data. We additionally demonstrate three representative use cases of the proposed dataset. The full dataset, along with the system software and hardware design, will be released as open-source to support continued research.
Can Visuo-motor Policies Benefit from Random Exploration Data? A Case Study on Stacking
Mar 30, 2025Human demonstrations have been key to recent advancements in robotic manipulation, but their scalability is hampered by the substantial cost of the required human labor. In this paper, we focus on random exploration data-video sequences and actions produced autonomously via motions to randomly sampled positions in the workspace-as an often overlooked resource for training visuo-motor policies in robotic manipulation. Within the scope of imitation learning, we examine random exploration data through two paradigms: (a) by investigating the use of random exploration video frames with three self-supervised learning objectives-reconstruction, contrastive, and distillation losses-and evaluating their applicability to visual pre-training; and (b) by analyzing random motor commands in the context of a staged learning framework to assess their effectiveness in autonomous data collection. Towards this goal, we present a large-scale experimental study based on over 750 hours of robot data collection, comprising 400 successful and 12,000 failed episodes. Our results indicate that: (a) among the three self-supervised learning objectives, contrastive loss appears most effective for visual pre-training while leveraging random exploration video frames; (b) data collected with random motor commands may play a crucial role in balancing the training data distribution and improving success rates in autonomous data collection within this study. The source code and dataset will be made publicly available at https://cloudgripper.org.
Video Transformers under Occlusion: How Physics and Background Attributes Impact Large Models for Robotic Manipulation
Oct 11, 2023


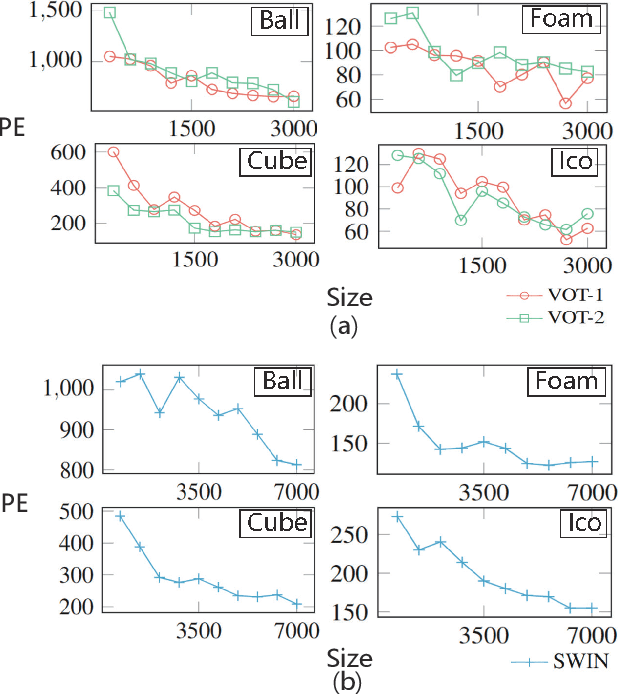
As transformer architectures and dataset sizes continue to scale, the need to understand the specific dataset factors affecting model performance becomes increasingly urgent. This paper investigates how object physics attributes (color, friction coefficient, shape) and background characteristics (static, dynamic, background complexity) influence the performance of Video Transformers in trajectory prediction tasks under occlusion. Beyond mere occlusion challenges, this study aims to investigate three questions: How do object physics attributes and background characteristics influence the model performance? What kinds of attributes are most influential to the model generalization? Is there a data saturation point for large transformer model performance within a single task? To facilitate this research, we present OccluManip, a real-world video-based robot pushing dataset comprising 460,000 consistent recordings of objects with different physics and varying backgrounds. 1.4 TB and in total 1278 hours of high-quality videos of flexible temporal length along with target object trajectories are collected, accommodating tasks with different temporal requirements. Additionally, we propose Video Occlusion Transformer (VOT), a generic video-transformer-based network achieving an average 96% accuracy across all 18 sub-datasets provided in OccluManip. OccluManip and VOT will be released at: https://github.com/ShutongJIN/OccluManip.git
CloudGripper: An Open Source Cloud Robotics Testbed for Robotic Manipulation Research, Benchmarking and Data Collection at Scale
Sep 22, 2023We present CloudGripper, an open source cloud robotics testbed, consisting of a scalable, space and cost-efficient design constructed as a rack of 32 small robot arm work cells. Each robot work cell is fully enclosed and features individual lighting, a low-cost custom 5 degree of freedom Cartesian robot arm with an attached parallel jaw gripper and a dual camera setup for experimentation. The system design is focused on continuous operation and features a 10 Gbit/s network connectivity allowing for high throughput remote-controlled experimentation and data collection for robotic manipulation. CloudGripper furthermore is intended to form a community testbed to study the challenges of large scale machine learning and cloud and edge-computing in the context of robotic manipulation. In this work, we describe the mechanical design of the system, its initial software stack and evaluate the repeatability of motions executed by the proposed robot arm design. A local network API throughput and latency analysis is also provided. CloudGripper-Rope-100, a dataset of more than a hundred hours of randomized rope pushing interactions and approximately 4 million camera images is collected and serves as a proof of concept demonstrating data collection capabilities. A project website with more information is available at https://cloudgripper.org.