 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks on Learned Policies for Surgical Robotic Tasks
Jun 10, 2026Learning-based policies are being considered to augment the dexterity of human surgeons in robot-assisted surgery. Can the end-to-end mapping from visual observations to robot actions be vulnerable to adversarial attacks, potentially leading to patient injury? In this paper, we present the first study of adversarial threats to learning-based policies in surgical robotics. We investigate two threat modes: (a) disruptive attacks, where imperceptible visual perturbations interrupt policy execution, and (b) steering attacks, where such perturbations steer policy actions toward attacker-specified directions. We formulate three adversarial attack methods, each with increasing access to policy information, and evaluate their impact on two surgical subtasks: debridement and suturing. Our evaluation covers three end-to-end policy architectures: ACT, Diffusion Policy, and Pi0. In addition, we introduce a new class of photometric adversarial attacks that mimic natural visual changes, such as lighting variations, to generate effective yet visually plausible perturbations. Results from 560 physical experiments using phantoms for debridement and suturing suggest that state-of-the-art policies can be significantly disrupted, resulting in an average 61% reduction in surgical subtask success rates. Project page: https://sites.google.com/view/adversary-surgery
Speculative Policy Orchestration: A Latency-Resilient Framework for Cloud-Robotic Manipulation
Mar 19, 2026Cloud robotics enables robots to offload high-dimensional motion planning and reasoning to remote servers. However, for continuous manipulation tasks requiring high-frequency control, network latency and jitter can severely destabilize the system, causing command starvation and unsafe physical execution. To address this, we propose Speculative Policy Orchestration (SPO), a latency-resilient cloud-edge framework. SPO utilizes a cloud-hosted world model to pre-compute and stream future kinematic waypoints to a local edge buffer, decoupling execution frequency from network round-trip time. To mitigate unsafe execution caused by predictive drift, the edge node employs an $ε$-tube verifier that strictly bounds kinematic execution errors. The framework is coupled with an Adaptive Horizon Scaling mechanism that dynamically expands or shrinks the speculative pre-fetch depth based on real-time tracking error. We evaluate SPO on continuous RLBench manipulation tasks under emulated network delays. Results show that even when deployed with learned models of modest accuracy, SPO reduces network-induced idle time by over 60% compared to blocking remote inference. Furthermore, SPO discards approximately 60% fewer cloud predictions than static caching baselines. Ultimately, SPO enables fluid, real-time cloud-robotic control while maintaining bounded physical safety.
RoboLight: A Dataset with Linearly Composable Illumination for Robotic Manipulation
Mar 04, 2026In this paper, we introduce RoboLight, the first real-world robotic manipulation dataset capturing synchronized episodes under systematically varied lighting conditions. RoboLight consists of two components. (a) RoboLight-Real contains 2,800 real-world episodes collected in our custom Light Cube setup, a calibrated system equipped with eight programmable RGB LED lights. It includes structured illumination variation along three independently controlled dimensions: color, direction, and intensity. Each dimension is paired with a dedicated task featuring objects of diverse geometries and materials to induce perceptual challenges. All image data are recorded in high-dynamic-range (HDR) format to preserve radiometric accuracy. Leveraging the linearity of light transport, we introduce (b) RoboLight-Synthetic, comprising 196,000 episodes synthesized through interpolation in the HDR image space of RoboLight-Real. In principle, RoboLight-Synthetic can be arbitrarily expanded by refining the interpolation granularity. We further verify the dataset quality through qualitative analysis and real-world policy roll-outs, analyzing task difficulty, distributional diversity, and the effectiveness of synthesized data. We additionally demonstrate three representative use cases of the proposed dataset. The full dataset, along with the system software and hardware design, will be released as open-source to support continued research.
Can Visuo-motor Policies Benefit from Random Exploration Data? A Case Study on Stacking
Mar 30, 2025Human demonstrations have been key to recent advancements in robotic manipulation, but their scalability is hampered by the substantial cost of the required human labor. In this paper, we focus on random exploration data-video sequences and actions produced autonomously via motions to randomly sampled positions in the workspace-as an often overlooked resource for training visuo-motor policies in robotic manipulation. Within the scope of imitation learning, we examine random exploration data through two paradigms: (a) by investigating the use of random exploration video frames with three self-supervised learning objectives-reconstruction, contrastive, and distillation losses-and evaluating their applicability to visual pre-training; and (b) by analyzing random motor commands in the context of a staged learning framework to assess their effectiveness in autonomous data collection. Towards this goal, we present a large-scale experimental study based on over 750 hours of robot data collection, comprising 400 successful and 12,000 failed episodes. Our results indicate that: (a) among the three self-supervised learning objectives, contrastive loss appears most effective for visual pre-training while leveraging random exploration video frames; (b) data collected with random motor commands may play a crucial role in balancing the training data distribution and improving success rates in autonomous data collection within this study. The source code and dataset will be made publicly available at https://cloudgripper.org.
PACA: Perspective-Aware Cross-Attention Representation for Zero-Shot Scene Rearrangement
Oct 29, 2024



Scene rearrangement, like table tidying, is a challenging task in robotic manipulation due to the complexity of predicting diverse object arrangements. Web-scale trained generative models such as Stable Diffusion can aid by generating natural scenes as goals. To facilitate robot execution, object-level representations must be extracted to match the real scenes with the generated goals and to calculate object pose transformations. Current methods typically use a multi-step design that involves separate models for generation, segmentation, and feature encoding, which can lead to a low success rate due to error accumulation. Furthermore, they lack control over the viewing perspectives of the generated goals, restricting the tasks to 3-DoF settings. In this paper, we propose PACA, a zero-shot pipeline for scene rearrangement that leverages perspective-aware cross-attention representation derived from Stable Diffusion. Specifically, we develop a representation that integrates generation, segmentation, and feature encoding into a single step to produce object-level representations. Additionally, we introduce perspective control, thus enabling the matching of 6-DoF camera views and extending past approaches that were limited to 3-DoF top-down views. The efficacy of our method is demonstrated through its zero-shot performance in real robot experiments across various scenes, achieving an average matching accuracy and execution success rate of 87% and 67%, respectively.
Feature Extractor or Decision Maker: Rethinking the Role of Visual Encoders in Visuomotor Policies
Sep 30, 2024



An end-to-end (E2E) visuomotor policy is typically treated as a unified whole, but recent approaches using out-of-domain (OOD) data to pretrain the visual encoder have cleanly separated the visual encoder from the network, with the remainder referred to as the policy. We propose Visual Alignment Testing, an experimental framework designed to evaluate the validity of this functional separation. Our results indicate that in E2E-trained models, visual encoders actively contribute to decision-making resulting from motor data supervision, contradicting the assumed functional separation. In contrast, OOD-pretrained models, where encoders lack this capability, experience an average performance drop of 42% in our benchmark results, compared to the state-of-the-art performance achieved by E2E policies. We believe this initial exploration of visual encoders' role can provide a first step towards guiding future pretraining methods to address their decision-making ability, such as developing task-conditioned or context-aware encoders.
RealCraft: Attention Control as A Solution for Zero-shot Long Video Editing
Dec 21, 2023Although large-scale text-to-image generative models have shown promising performance in synthesizing high-quality images, directly applying these models to image editing remains a significant challenge. This challenge is further amplified in video editing due to the additional dimension of time. Especially for editing real videos as it necessitates maintaining a stable semantic layout across the frames while executing localized edits precisely without disrupting the existing backgrounds. In this paper, we propose RealCraft, an attention-control-based method for zero-shot editing in real videos. By employing the object-centric manipulation of cross-attention between prompts and frames and spatial-temporal attention within the frames, we achieve precise shape-wise editing along with enhanced consistency. Our model can be used directly with Stable Diffusion and operates without the need for additional localized information. We showcase our zero-shot attention-control-based method across a range of videos, demonstrating localized, high-fidelity, shape-precise and time-consistent editing in videos of various lengths, up to 64 frames.
Video Transformers under Occlusion: How Physics and Background Attributes Impact Large Models for Robotic Manipulation
Oct 11, 2023


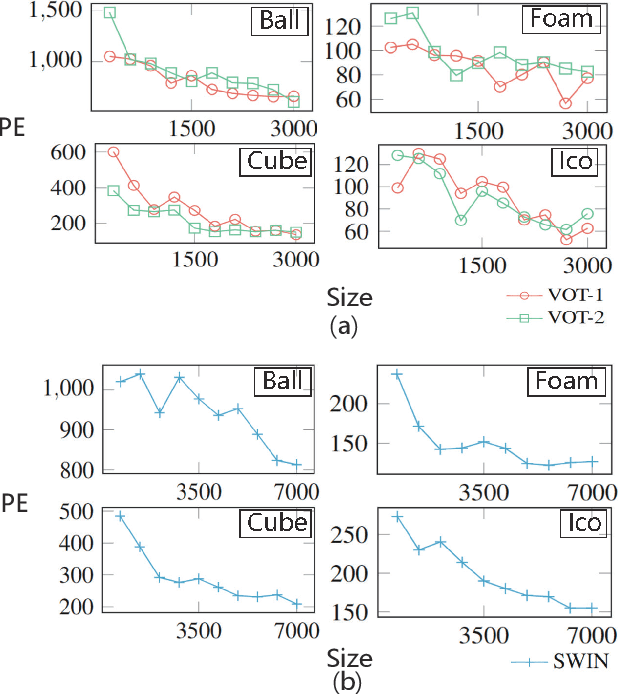
As transformer architectures and dataset sizes continue to scale, the need to understand the specific dataset factors affecting model performance becomes increasingly urgent. This paper investigates how object physics attributes (color, friction coefficient, shape) and background characteristics (static, dynamic, background complexity) influence the performance of Video Transformers in trajectory prediction tasks under occlusion. Beyond mere occlusion challenges, this study aims to investigate three questions: How do object physics attributes and background characteristics influence the model performance? What kinds of attributes are most influential to the model generalization? Is there a data saturation point for large transformer model performance within a single task? To facilitate this research, we present OccluManip, a real-world video-based robot pushing dataset comprising 460,000 consistent recordings of objects with different physics and varying backgrounds. 1.4 TB and in total 1278 hours of high-quality videos of flexible temporal length along with target object trajectories are collected, accommodating tasks with different temporal requirements. Additionally, we propose Video Occlusion Transformer (VOT), a generic video-transformer-based network achieving an average 96% accuracy across all 18 sub-datasets provided in OccluManip. OccluManip and VOT will be released at: https://github.com/ShutongJIN/OccluManip.git