 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Operator Takeover for Visuomotor Diffusion Policy Training
Feb 04, 2025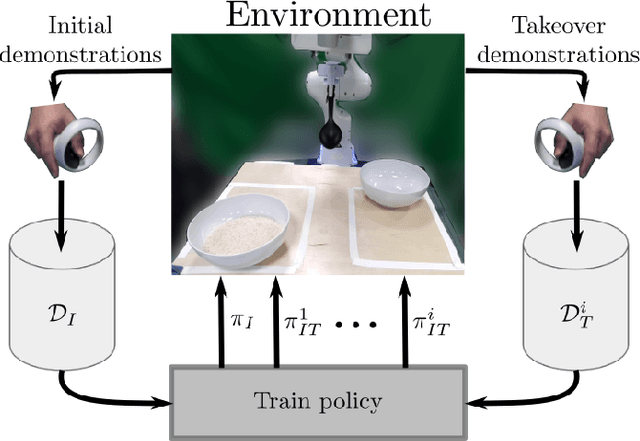

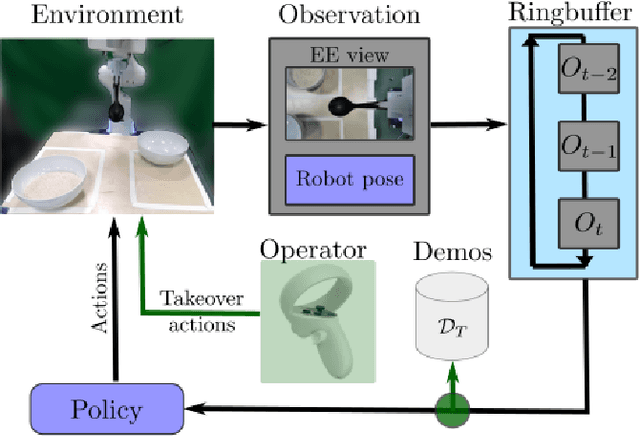
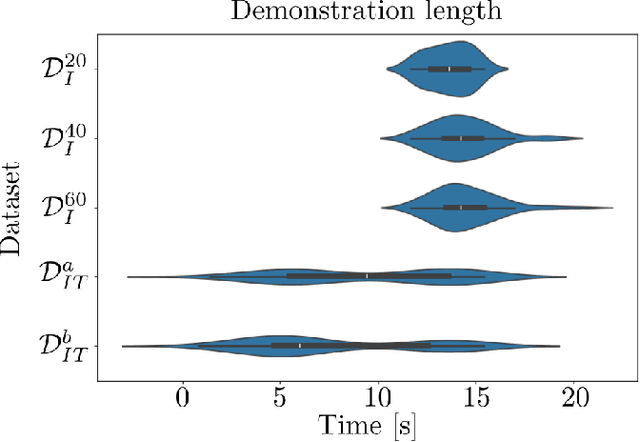
We present a Real-Time Operator Takeover (RTOT) paradigm enabling operators to seamlessly take control of a live visuomotor diffusion policy, guiding the system back into desirable states or reinforcing specific demonstrations. We presents new insights in using the Mahalonobis distance to automaicaly identify undesirable states. Once the operator has intervened and redirected the system, the control is seamlessly returned to the policy, which resumes generating actions until further intervention is required. We demonstrate that incorporating the targeted takeover demonstrations significantly improves policy performance compared to training solely with an equivalent number of, but longer, initial demonstrations. We provide an in-depth analysis of using the Mahalanobis distance to detect out-of-distribution states, illustrating its utility for identifying critical failure points during execution. Supporting materials, including videos of initial and takeover demonstrations and all rice-scooping experiments, are available on the project website: https://operator-takeover.github.io/
Feature Extractor or Decision Maker: Rethinking the Role of Visual Encoders in Visuomotor Policies
Sep 30, 2024



An end-to-end (E2E) visuomotor policy is typically treated as a unified whole, but recent approaches using out-of-domain (OOD) data to pretrain the visual encoder have cleanly separated the visual encoder from the network, with the remainder referred to as the policy. We propose Visual Alignment Testing, an experimental framework designed to evaluate the validity of this functional separation. Our results indicate that in E2E-trained models, visual encoders actively contribute to decision-making resulting from motor data supervision, contradicting the assumed functional separation. In contrast, OOD-pretrained models, where encoders lack this capability, experience an average performance drop of 42% in our benchmark results, compared to the state-of-the-art performance achieved by E2E policies. We believe this initial exploration of visual encoders' role can provide a first step towards guiding future pretraining methods to address their decision-making ability, such as developing task-conditioned or context-aware encoders.
A Robotic Skill Learning System Built Upon Diffusion Policies and Foundation Models
Mar 25, 2024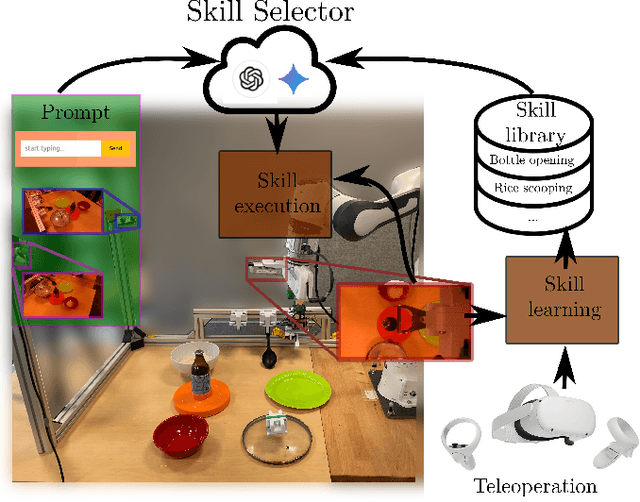

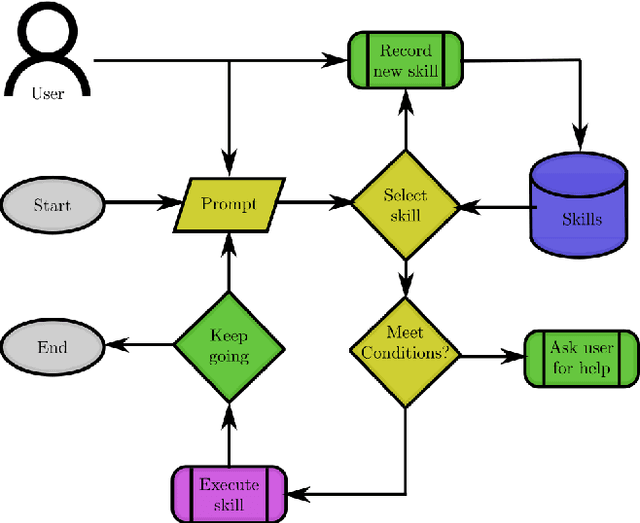
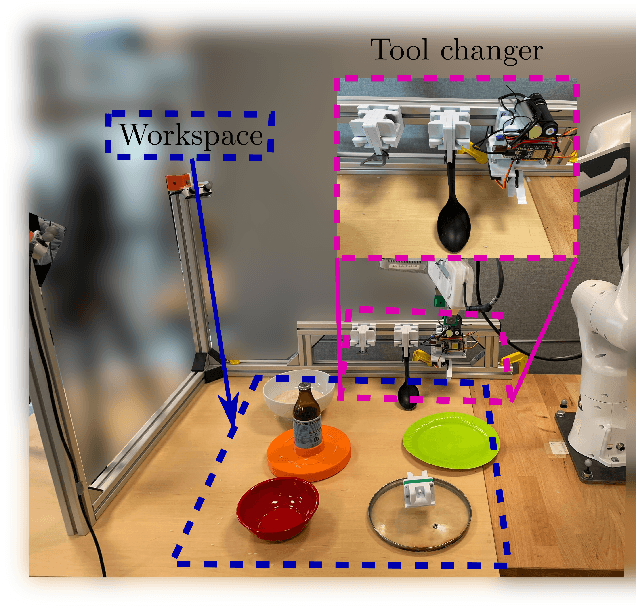
In this paper, we build upon two major recent developments in the field, Diffusion Policies for visuomotor manipulation and large pre-trained multimodal foundational models to obtain a robotic skill learning system. The system can obtain new skills via the behavioral cloning approach of visuomotor diffusion policies given teleoperated demonstrations. Foundational models are being used to perform skill selection given the user's prompt in natural language. Before executing a skill the foundational model performs a precondition check given an observation of the workspace. We compare the performance of different foundational models to this end as well as give a detailed experimental evaluation of the skills taught by the user in simulation and the real world. Finally, we showcase the combined system on a challenging food serving scenario in the real world. Videos of all experimental executions, as well as the process of teaching new skills in simulation and the real world, are available on the project's website.