 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Match: Two-Sided Matching with Temporally Extended Feedback
Jun 04, 2026Two-sided matching markets often involve information that unfolds over time through interviews, repeated interaction, learning, and separation. Existing matching models typically reduce this process to immediate sub-Gaussian feedback about fixed preferences, missing settings where payoff-relevant information is revealed gradually and changes future matching decisions. We introduce a framework with temporally extended feedback, that formulates two-sided matching as a partially observable Markov game with costly pre-match screening, noisy post-match observations, evolving latent profiles, and endogenous continuation or dissolution. We instantiate this framework in Learn2Match, a multi-agent reinforcement-learning benchmark for dynamic matching markets. Learn2Match supports decentralized decision making over whom to interview, whom to match with, and when to dissolve a match, while evaluating policies using regret, social welfare, and an information-friction loss that measures the welfare gap caused by incomplete revelation of latent preferences. We find that independent PPO achieves higher cumulative social welfare and lower cumulative regret than the bandit-style CA-ETC baseline under temporally extended feedback, demonstrating the promise of MARL for dynamic matching markets. However, PPO still incurs higher information-friction loss, revealing that end-to-end MARL does not yet provide the coordinated exploration structure of matching-bandit methods. These results position Learn2Match as a benchmark for developing the next generation of matching-market algorithms: methods that are adaptive like RL agents, statistically disciplined like bandit algorithms, and structurally aware like stable-matching mechanisms.
E2HiL: Entropy-Guided Sample Selection for Efficient Real-World Human-in-the-Loop Reinforcement Learning
Jan 27, 2026Human-in-the-loop guidance has emerged as an effective approach for enabling faster convergence in online reinforcement learning (RL) of complex real-world manipulation tasks. However, existing human-in-the-loop RL (HiL-RL) frameworks often suffer from low sample efficiency, requiring substantial human interventions to achieve convergence and thereby leading to high labor costs. To address this, we propose a sample-efficient real-world human-in-the-loop RL framework named \method, which requires fewer human intervention by actively selecting informative samples. Specifically, stable reduction of policy entropy enables improved trade-off between exploration and exploitation with higher sample efficiency. We first build influence functions of different samples on the policy entropy, which is efficiently estimated by the covariance of action probabilities and soft advantages of policies. Then we select samples with moderate values of influence functions, where shortcut samples that induce sharp entropy drops and noisy samples with negligible effect are pruned. Extensive experiments on four real-world manipulation tasks demonstrate that \method achieves a 42.1\% higher success rate while requiring 10.1\% fewer human interventions compared to the state-of-the-art HiL-RL method, validating its effectiveness. The project page providing code, videos, and mathematical formulations can be found at https://e2hil.github.io/.
Generative Inbetweening: Adapting Image-to-Video Models for Keyframe Interpolation
Aug 27, 2024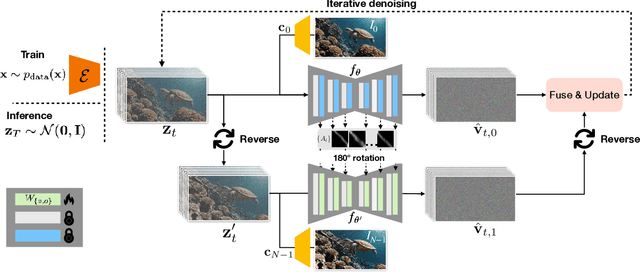
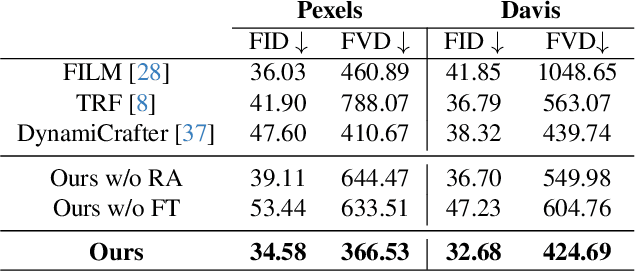

We present a method for generating video sequences with coherent motion between a pair of input key frames. We adapt a pretrained large-scale image-to-video diffusion model (originally trained to generate videos moving forward in time from a single input image) for key frame interpolation, i.e., to produce a video in between two input frames. We accomplish this adaptation through a lightweight fine-tuning technique that produces a version of the model that instead predicts videos moving backwards in time from a single input image. This model (along with the original forward-moving model) is subsequently used in a dual-directional diffusion sampling process that combines the overlapping model estimates starting from each of the two keyframes. Our experiments show that our method outperforms both existing diffusion-based methods and traditional frame interpolation techniques.
F$^2$AT: Feature-Focusing Adversarial Training via Disentanglement of Natural and Perturbed Patterns
Oct 23, 2023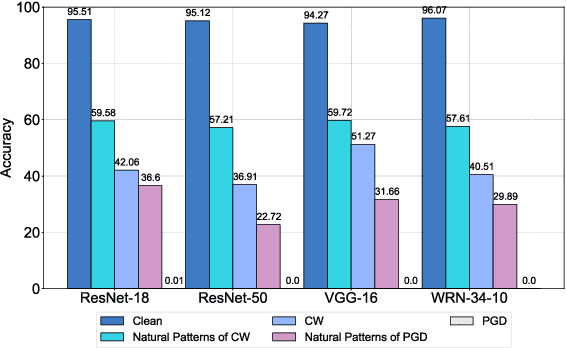

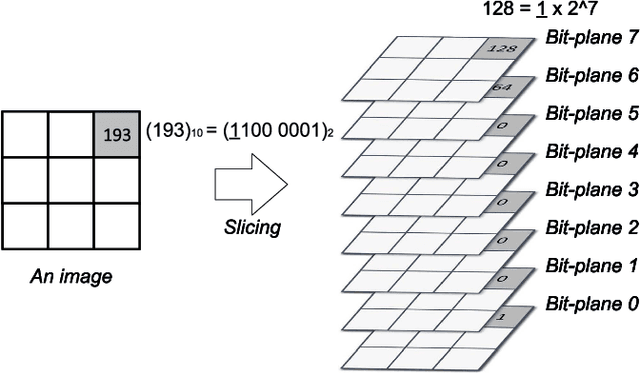
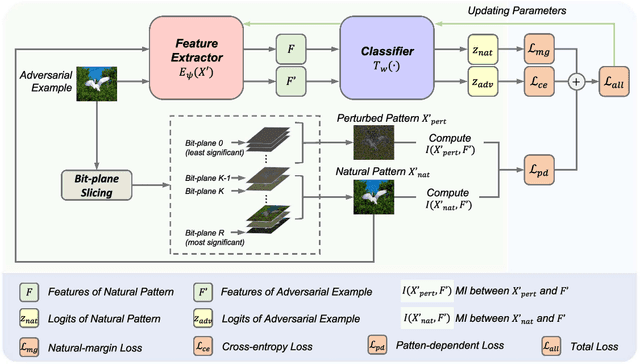
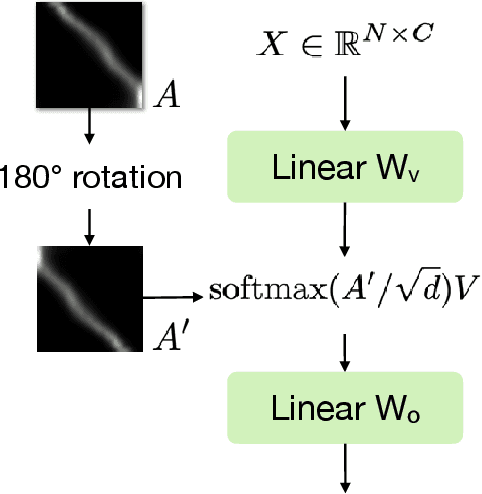
Deep neural networks (DNNs) are vulnerable to adversarial examples crafted by well-designed perturbations. This could lead to disastrous results on critical applications such as self-driving cars, surveillance security, and medical diagnosis. At present, adversarial training is one of the most effective defenses against adversarial examples. However, traditional adversarial training makes it difficult to achieve a good trade-off between clean accuracy and robustness since spurious features are still learned by DNNs. The intrinsic reason is that traditional adversarial training makes it difficult to fully learn core features from adversarial examples when adversarial noise and clean examples cannot be disentangled. In this paper, we disentangle the adversarial examples into natural and perturbed patterns by bit-plane slicing. We assume the higher bit-planes represent natural patterns and the lower bit-planes represent perturbed patterns, respectively. We propose a Feature-Focusing Adversarial Training (F$^2$AT), which differs from previous work in that it enforces the model to focus on the core features from natural patterns and reduce the impact of spurious features from perturbed patterns. The experimental results demonstrated that F$^2$AT outperforms state-of-the-art methods in clean accuracy and adversarial robustness.