 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Image Decomposition with Diffusion Models
Jun 27, 2024Given an image of a natural scene, we are able to quickly decompose it into a set of components such as objects, lighting, shadows, and foreground. We can then envision a scene where we combine certain components with those from other images, for instance a set of objects from our bedroom and animals from a zoo under the lighting conditions of a forest, even if we have never encountered such a scene before. In this paper, we present a method to decompose an image into such compositional components. Our approach, Decomp Diffusion, is an unsupervised method which, when given a single image, infers a set of different components in the image, each represented by a diffusion model. We demonstrate how components can capture different factors of the scene, ranging from global scene descriptors like shadows or facial expression to local scene descriptors like constituent objects. We further illustrate how inferred factors can be flexibly composed, even with factors inferred from other models, to generate a variety of scenes sharply different than those seen in training time. Website and code at https://energy-based-model.github.io/decomp-diffusion.
Computationally Efficient Measures of Internal Neuron Importance
Jul 26, 2018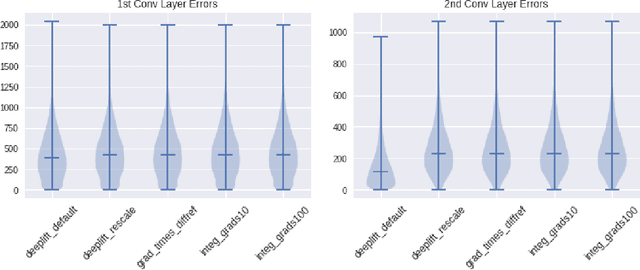
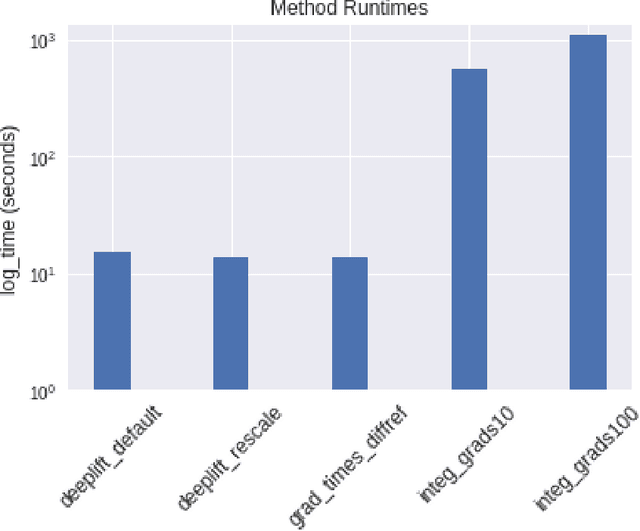
The challenge of assigning importance to individual neurons in a network is of interest when interpreting deep learning models. In recent work, Dhamdhere et al. proposed Total Conductance, a "natural refinement of Integrated Gradients" for attributing importance to internal neurons. Unfortunately, the authors found that calculating conductance in tensorflow required the addition of several custom gradient operators and did not scale well. In this work, we show that the formula for Total Conductance is mathematically equivalent to Path Integrated Gradients computed on a hidden layer in the network. We provide a scalable implementation of Total Conductance using standard tensorflow gradient operators that we call Neuron Integrated Gradients. We compare Neuron Integrated Gradients to DeepLIFT, a pre-existing computationally efficient approach that is applicable to calculating internal neuron importance. We find that DeepLIFT produces strong empirical results and is faster to compute, but because it lacks the theoretical properties of Neuron Integrated Gradients, it may not always be preferred in practice. Colab notebook reproducing results: http://bit.ly/neuronintegratedgradients