 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Predictive Risk Models for Emergency Departments with Large Public Electronic Health Records
Nov 22, 2021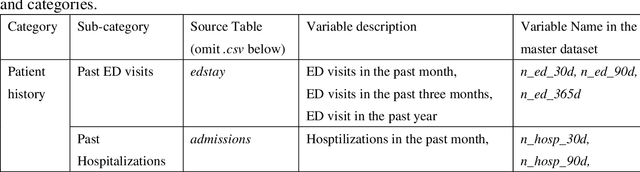
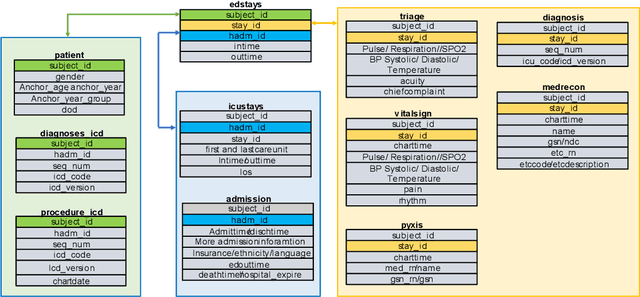
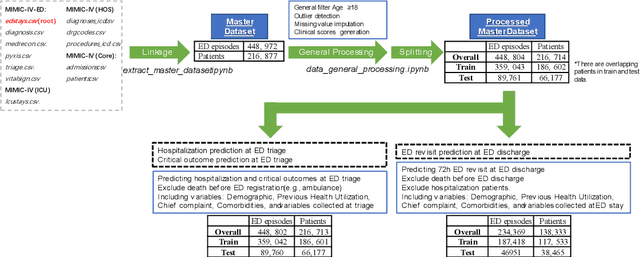
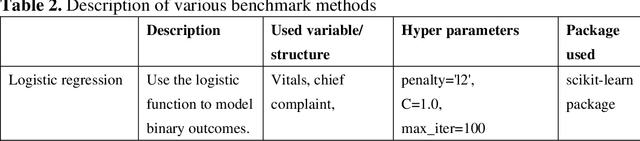
There is a continuously growing demand for emergency department (ED) services across the world, especially under the COVID-19 pandemic. Risk triaging plays a crucial role in prioritizing limited medical resources for patients who need them most. Recently the pervasive use of Electronic Health Records (EHR) has generated a large volume of stored data, accompanied by vast opportunities for the development of predictive models which could improve emergency care. However, there is an absence of widely accepted ED benchmarks based on large-scale public EHR, which new researchers could easily access. Success in filling in this gap could enable researchers to start studies on ED more quickly and conveniently without verbose data preprocessing and facilitate comparisons among different studies and methodologies. In this paper, based on the Medical Information Mart for Intensive Care IV Emergency Department (MIMIC-IV-ED) database, we proposed a public ED benchmark suite and obtained a benchmark dataset containing over 500,000 ED visits episodes from 2011 to 2019. Three ED-based prediction tasks (hospitalization, critical outcomes, and 72-hour ED revisit) were introduced, where various popular methodologies, from machine learning methods to clinical scoring systems, were implemented. The results of their performance were evaluated and compared. Our codes are open-source so that anyone with access to MIMIC-IV-ED could follow the same steps of data processing, build the benchmarks, and reproduce the experiments. This study provided insights, suggestions, as well as protocols for future researchers to process the raw data and quickly build up models for emergency care.
AutoScore-Imbalance: An interpretable machine learning tool for development of clinical scores with rare events data
Jul 13, 2021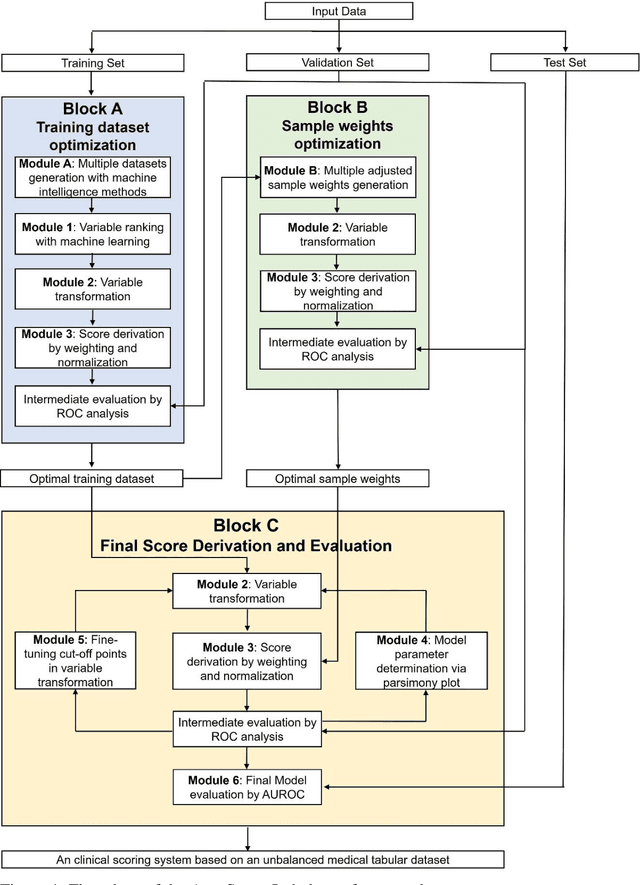
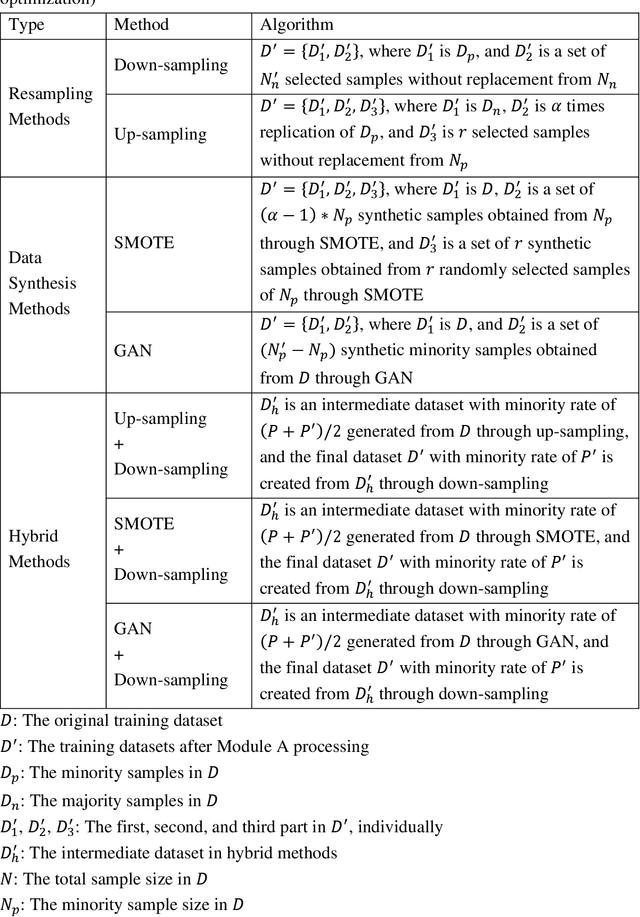
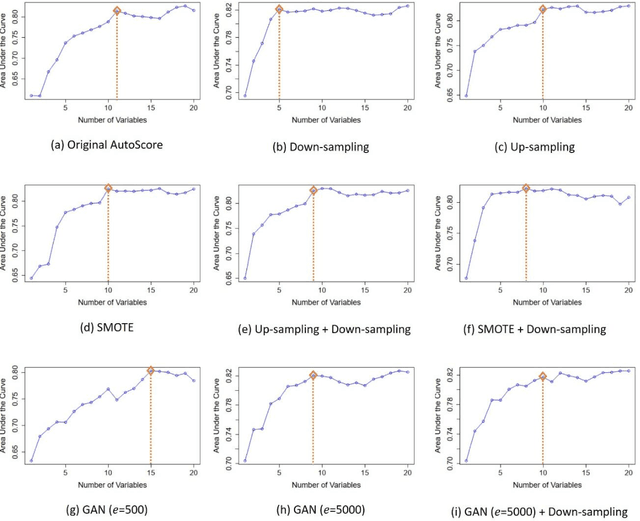
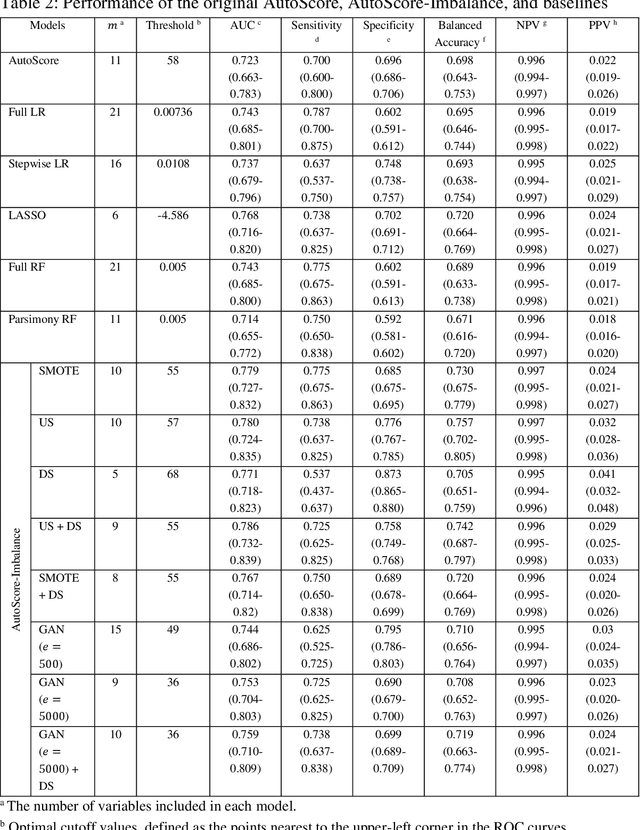
Background: Medical decision-making impacts both individual and public health. Clinical scores are commonly used among a wide variety of decision-making models for determining the degree of disease deterioration at the bedside. AutoScore was proposed as a useful clinical score generator based on machine learning and a generalized linear model. Its current framework, however, still leaves room for improvement when addressing unbalanced data of rare events. Methods: Using machine intelligence approaches, we developed AutoScore-Imbalance, which comprises three components: training dataset optimization, sample weight optimization, and adjusted AutoScore. All scoring models were evaluated on the basis of their area under the curve (AUC) in the receiver operating characteristic analysis and balanced accuracy (i.e., mean value of sensitivity and specificity). By utilizing a publicly accessible dataset from Beth Israel Deaconess Medical Center, we assessed the proposed model and baseline approaches in the prediction of inpatient mortality. Results: AutoScore-Imbalance outperformed baselines in terms of AUC and balanced accuracy. The nine-variable AutoScore-Imbalance sub-model achieved the highest AUC of 0.786 (0.732-0.839) while the eleven-variable original AutoScore obtained an AUC of 0.723 (0.663-0.783), and the logistic regression with 21 variables obtained an AUC of 0.743 (0.685-0.800). The AutoScore-Imbalance sub-model (using down-sampling algorithm) yielded an AUC of 0. 0.771 (0.718-0.823) with only five variables, demonstrating a good balance between performance and variable sparsity. Conclusions: The AutoScore-Imbalance tool has the potential to be applied to highly unbalanced datasets to gain further insight into rare medical events and to facilitate real-world clinical decision-making.