 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvival modeling using deep learning, machine learning and statistical methods: A comparative analysis for predicting mortality after hospital admission
Mar 04, 2024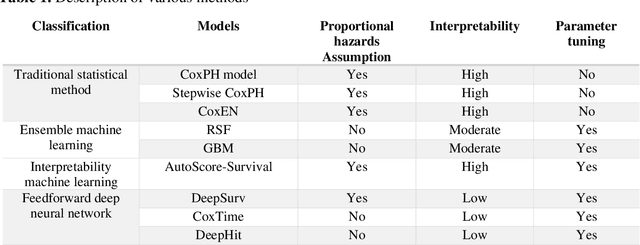
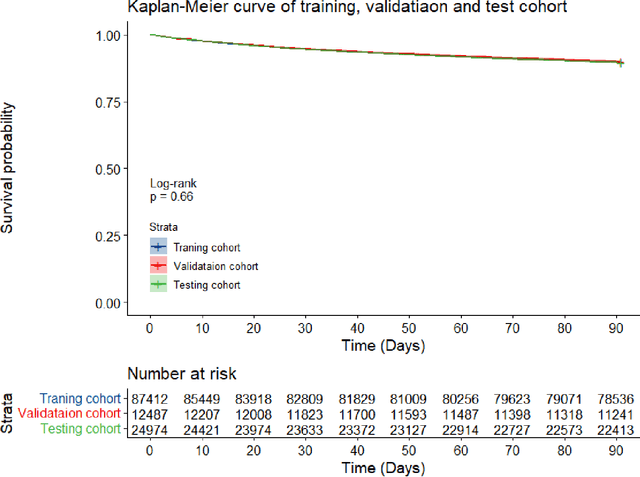
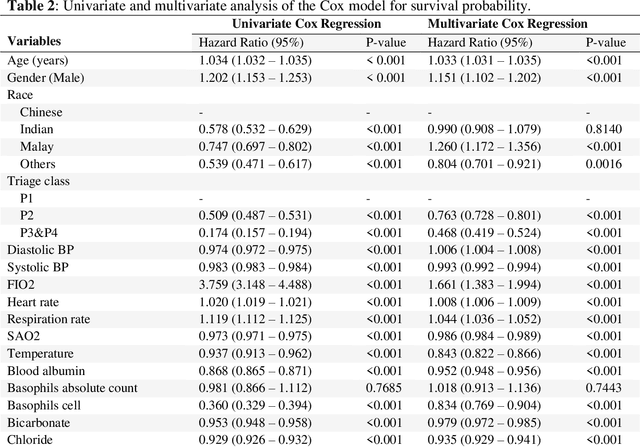
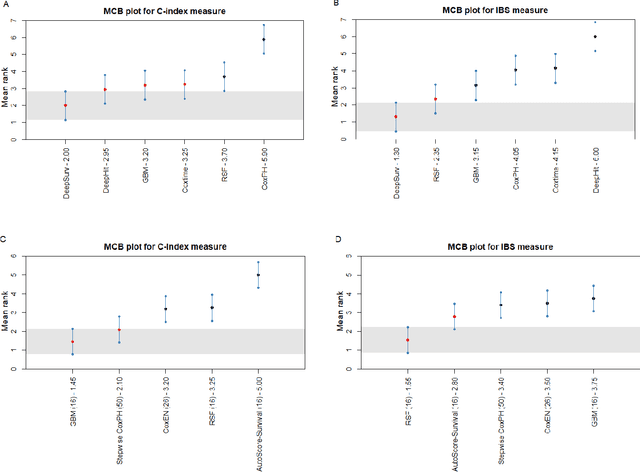
Survival analysis is essential for studying time-to-event outcomes and providing a dynamic understanding of the probability of an event occurring over time. Various survival analysis techniques, from traditional statistical models to state-of-the-art machine learning algorithms, support healthcare intervention and policy decisions. However, there remains ongoing discussion about their comparative performance. We conducted a comparative study of several survival analysis methods, including Cox proportional hazards (CoxPH), stepwise CoxPH, elastic net penalized Cox model, Random Survival Forests (RSF), Gradient Boosting machine (GBM) learning, AutoScore-Survival, DeepSurv, time-dependent Cox model based on neural network (CoxTime), and DeepHit survival neural network. We applied the concordance index (C-index) for model goodness-of-fit, and integral Brier scores (IBS) for calibration, and considered the model interpretability. As a case study, we performed a retrospective analysis of patients admitted through the emergency department of a tertiary hospital from 2017 to 2019, predicting 90-day all-cause mortality based on patient demographics, clinicopathological features, and historical data. The results of the C-index indicate that deep learning achieved comparable performance, with DeepSurv producing the best discrimination (DeepSurv: 0.893; CoxTime: 0.892; DeepHit: 0.891). The calibration of DeepSurv (IBS: 0.041) performed the best, followed by RSF (IBS: 0.042) and GBM (IBS: 0.0421), all using the full variables. Moreover, AutoScore-Survival, using a minimal variable subset, is easy to interpret, and can achieve good discrimination and calibration (C-index: 0.867; IBS: 0.044). While all models were satisfactory, DeepSurv exhibited the best discrimination and calibration. In addition, AutoScore-Survival offers a more parsimonious model and excellent interpretability.
Benchmarking Predictive Risk Models for Emergency Departments with Large Public Electronic Health Records
Nov 22, 2021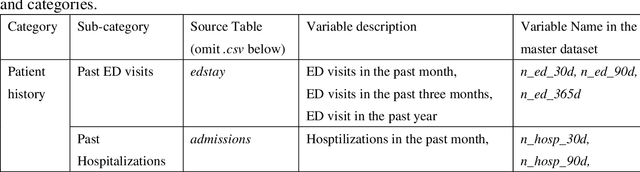
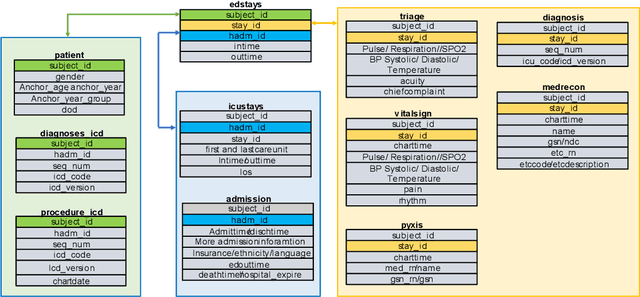
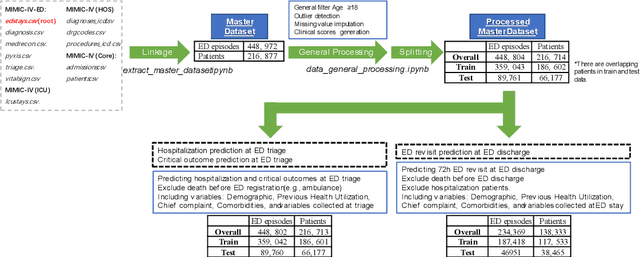
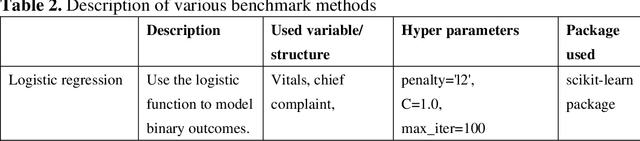
There is a continuously growing demand for emergency department (ED) services across the world, especially under the COVID-19 pandemic. Risk triaging plays a crucial role in prioritizing limited medical resources for patients who need them most. Recently the pervasive use of Electronic Health Records (EHR) has generated a large volume of stored data, accompanied by vast opportunities for the development of predictive models which could improve emergency care. However, there is an absence of widely accepted ED benchmarks based on large-scale public EHR, which new researchers could easily access. Success in filling in this gap could enable researchers to start studies on ED more quickly and conveniently without verbose data preprocessing and facilitate comparisons among different studies and methodologies. In this paper, based on the Medical Information Mart for Intensive Care IV Emergency Department (MIMIC-IV-ED) database, we proposed a public ED benchmark suite and obtained a benchmark dataset containing over 500,000 ED visits episodes from 2011 to 2019. Three ED-based prediction tasks (hospitalization, critical outcomes, and 72-hour ED revisit) were introduced, where various popular methodologies, from machine learning methods to clinical scoring systems, were implemented. The results of their performance were evaluated and compared. Our codes are open-source so that anyone with access to MIMIC-IV-ED could follow the same steps of data processing, build the benchmarks, and reproduce the experiments. This study provided insights, suggestions, as well as protocols for future researchers to process the raw data and quickly build up models for emergency care.