 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness-Aware Interpretable Modeling (FAIM) for Trustworthy Machine Learning in Healthcare
Mar 08, 2024
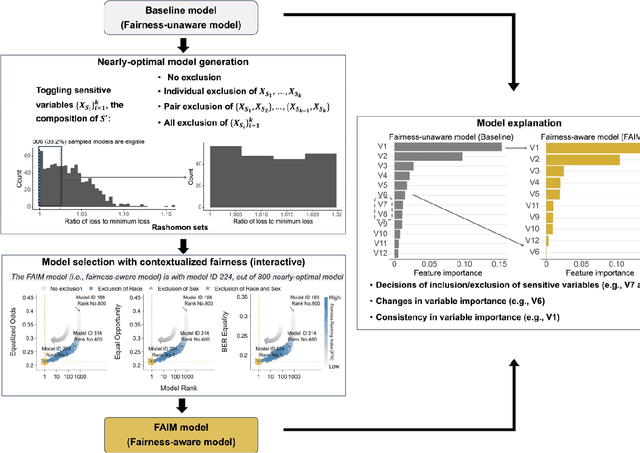


The escalating integration of machine learning in high-stakes fields such as healthcare raises substantial concerns about model fairness. We propose an interpretable framework - Fairness-Aware Interpretable Modeling (FAIM), to improve model fairness without compromising performance, featuring an interactive interface to identify a "fairer" model from a set of high-performing models and promoting the integration of data-driven evidence and clinical expertise to enhance contextualized fairness. We demonstrated FAIM's value in reducing sex and race biases by predicting hospital admission with two real-world databases, MIMIC-IV-ED and SGH-ED. We show that for both datasets, FAIM models not only exhibited satisfactory discriminatory performance but also significantly mitigated biases as measured by well-established fairness metrics, outperforming commonly used bias-mitigation methods. Our approach demonstrates the feasibility of improving fairness without sacrificing performance and provides an a modeling mode that invites domain experts to engage, fostering a multidisciplinary effort toward tailored AI fairness.
Generative Artificial Intelligence in Healthcare: Ethical Considerations and Assessment Checklist
Nov 02, 2023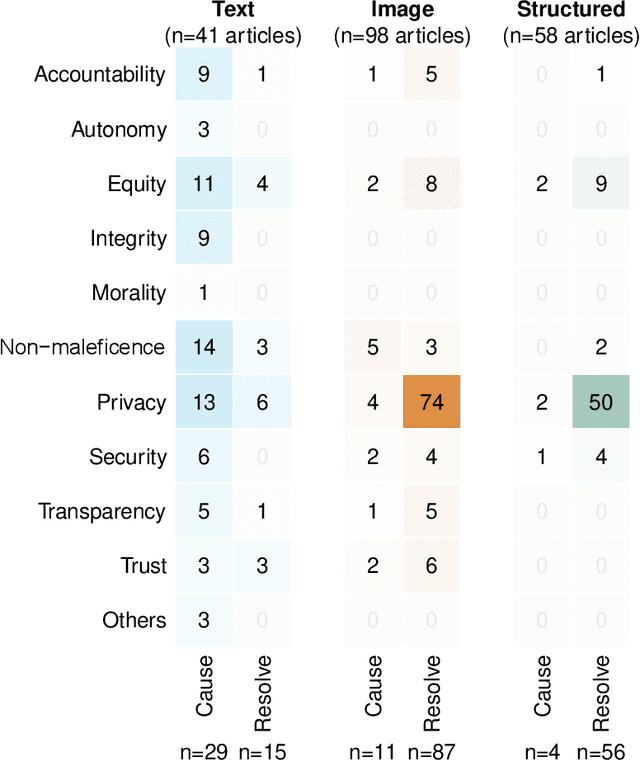
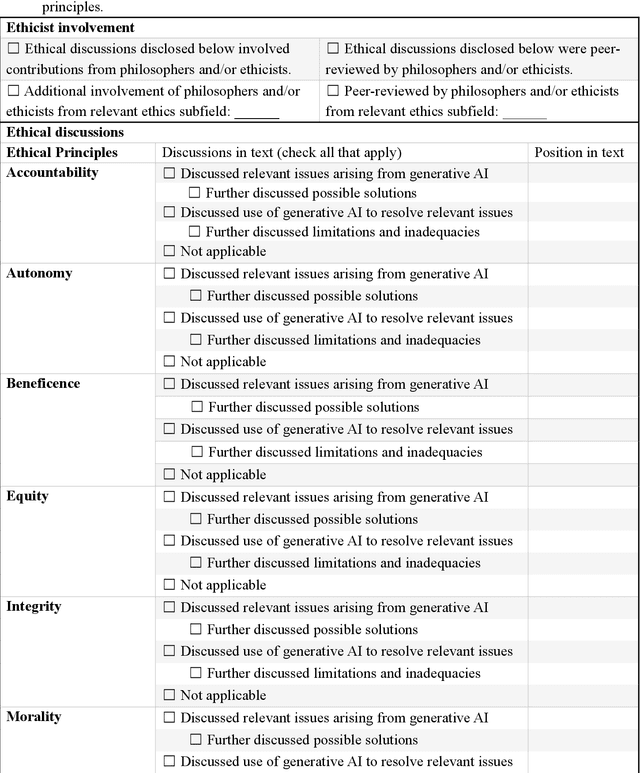
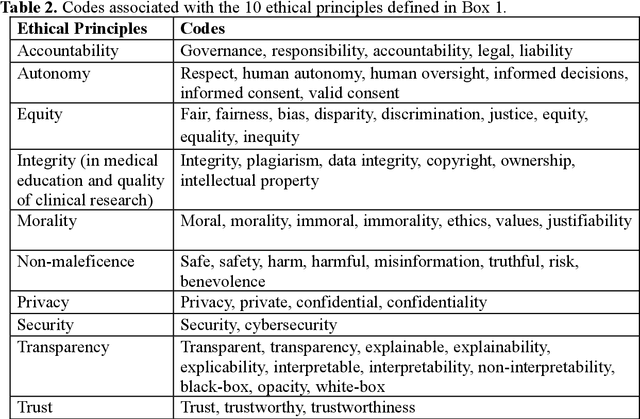
The widespread use of ChatGPT and other emerging technology powered by generative artificial intelligence (AI) has drawn much attention to potential ethical issues, especially in high-stakes applications such as healthcare. However, less clear is how to resolve such issues beyond following guidelines and regulations that are still under discussion and development. On the other hand, other types of generative AI have been used to synthesize images and other types of data for research and practical purposes, which have resolved some ethical issues and exposed other ethical issues, but such technology is less often the focus of ongoing ethical discussions. Here we highlight gaps in current ethical discussions of generative AI via a systematic scoping review of relevant existing research in healthcare, and reduce the gaps by proposing an ethics checklist for comprehensive assessment and transparent documentation of ethical discussions in generative AI development. While the checklist can be readily integrated into the current peer review and publication system to enhance generative AI research, it may also be used in broader settings to disclose ethics-related considerations in generative AI-powered products (or real-life applications of such products) to help users establish reasonable trust in their capabilities.
AutoScore-Ordinal: An interpretable machine learning framework for generating scoring models for ordinal outcomes
Feb 17, 2022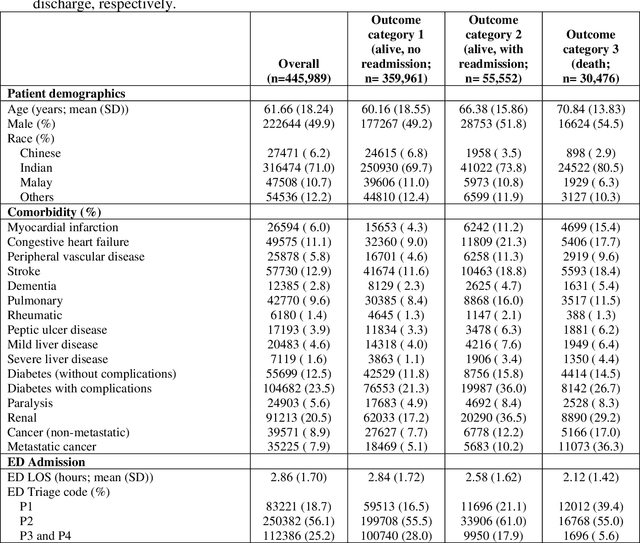
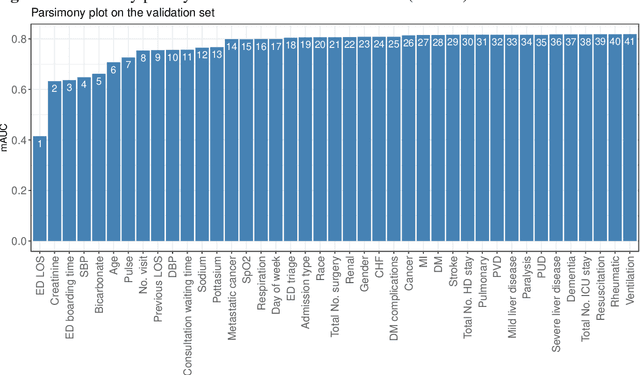
Background: Risk prediction models are useful tools in clinical decision-making which help with risk stratification and resource allocations and may lead to a better health care for patients. AutoScore is a machine learning-based automatic clinical score generator for binary outcomes. This study aims to expand the AutoScore framework to provide a tool for interpretable risk prediction for ordinal outcomes. Methods: The AutoScore-Ordinal framework is generated using the same 6 modules of the original AutoScore algorithm including variable ranking, variable transformation, score derivation (from proportional odds models), model selection, score fine-tuning, and model evaluation. To illustrate the AutoScore-Ordinal performance, the method was conducted on electronic health records data from the emergency department at Singapore General Hospital over 2008 to 2017. The model was trained on 70% of the data, validated on 10% and tested on the remaining 20%. Results: This study included 445,989 inpatient cases, where the distribution of the ordinal outcome was 80.7% alive without 30-day readmission, 12.5% alive with 30-day readmission, and 6.8% died inpatient or by day 30 post discharge. Two point-based risk prediction models were developed using two sets of 8 predictor variables identified by the flexible variable selection procedure. The two models indicated reasonably good performance measured by mean area under the receiver operating characteristic curve (0.785 and 0.793) and generalized c-index (0.737 and 0.760), which were comparable to alternative models. Conclusion: AutoScore-Ordinal provides an automated and easy-to-use framework for development and validation of risk prediction models for ordinal outcomes, which can systematically identify potential predictors from high-dimensional data.
Shapley variable importance clouds for interpretable machine learning
Oct 06, 2021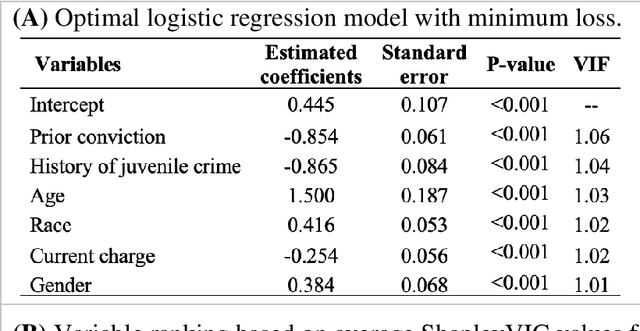
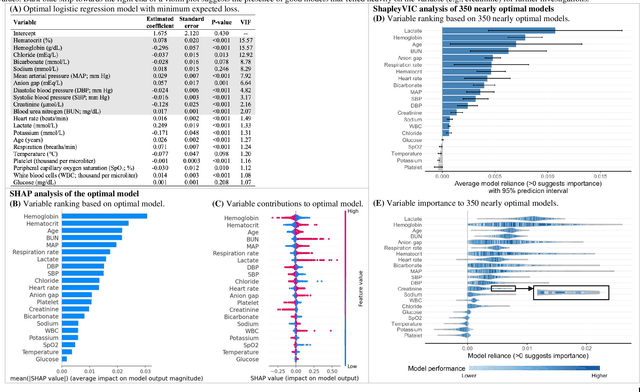
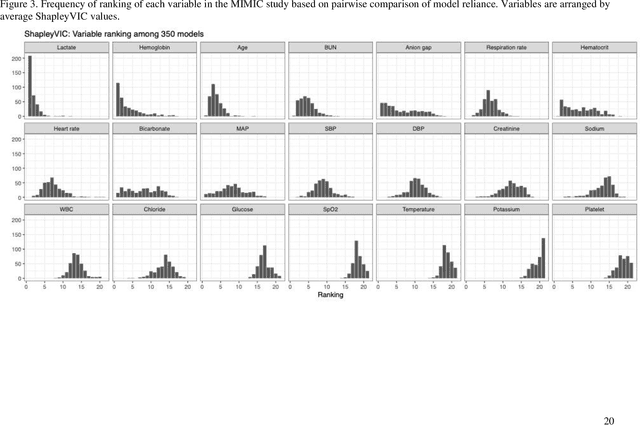
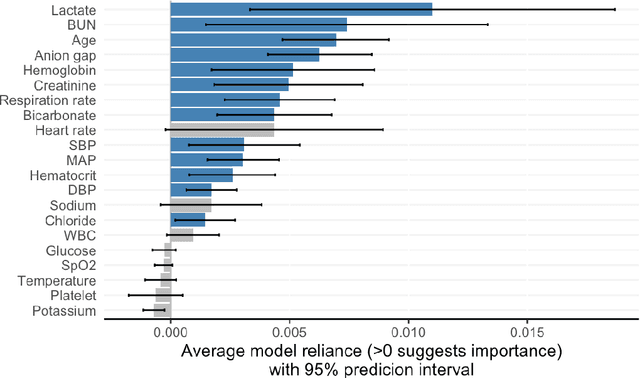
Interpretable machine learning has been focusing on explaining final models that optimize performance. The current state-of-the-art is the Shapley additive explanations (SHAP) that locally explains variable impact on individual predictions, and it is recently extended for a global assessment across the dataset. Recently, Dong and Rudin proposed to extend the investigation to models from the same class as the final model that are "good enough", and identified a previous overclaim of variable importance based on a single model. However, this method does not directly integrate with existing Shapley-based interpretations. We close this gap by proposing a Shapley variable importance cloud that pools information across good models to avoid biased assessments in SHAP analyses of final models, and communicate the findings via novel visualizations. We demonstrate the additional insights gain compared to conventional explanations and Dong and Rudin's method using criminal justice and electronic medical records data.