 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapley variable importance clouds for interpretable machine learning
Paper and Code
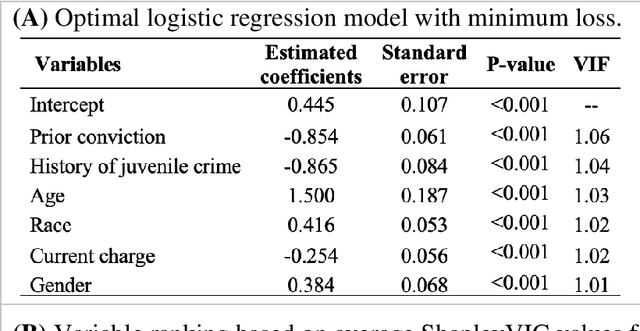
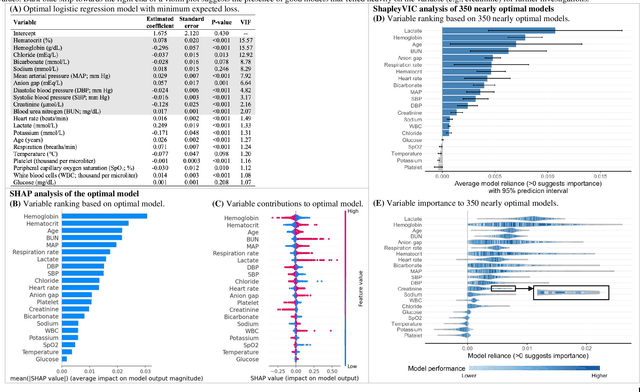
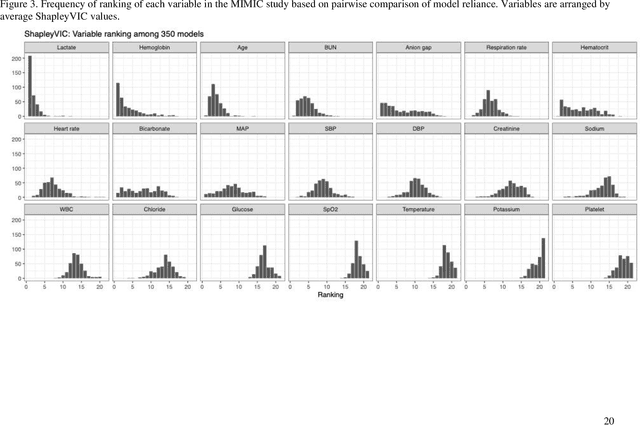
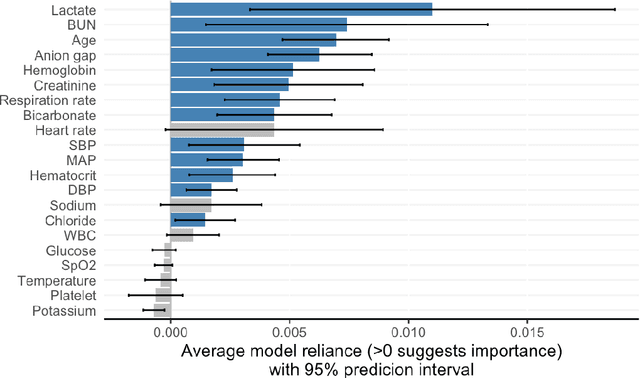
Interpretable machine learning has been focusing on explaining final models that optimize performance. The current state-of-the-art is the Shapley additive explanations (SHAP) that locally explains variable impact on individual predictions, and it is recently extended for a global assessment across the dataset. Recently, Dong and Rudin proposed to extend the investigation to models from the same class as the final model that are "good enough", and identified a previous overclaim of variable importance based on a single model. However, this method does not directly integrate with existing Shapley-based interpretations. We close this gap by proposing a Shapley variable importance cloud that pools information across good models to avoid biased assessments in SHAP analyses of final models, and communicate the findings via novel visualizations. We demonstrate the additional insights gain compared to conventional explanations and Dong and Rudin's method using criminal justice and electronic medical records data.