 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Privacy Onion Effect: Memorization is Relative
Paper and Code
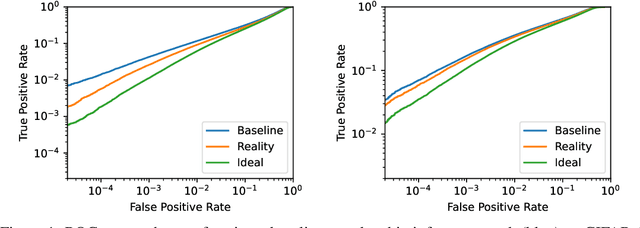
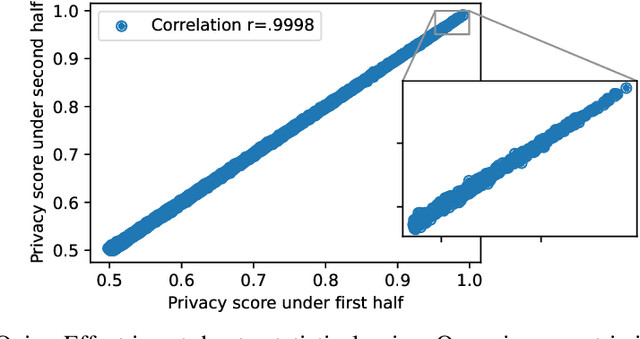
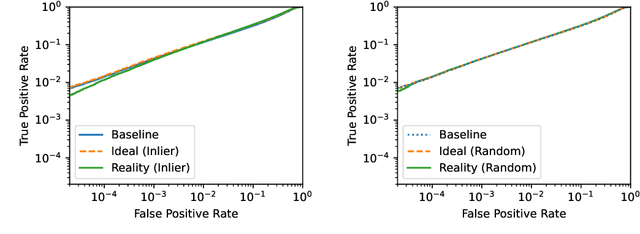
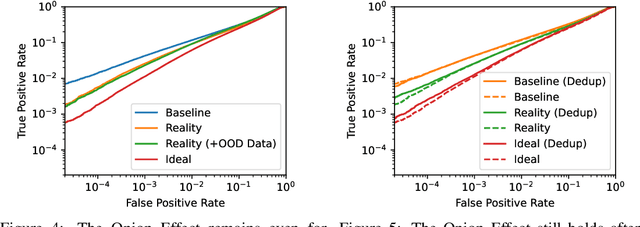
Machine learning models trained on private datasets have been shown to leak their private data. While recent work has found that the average data point is rarely leaked, the outlier samples are frequently subject to memorization and, consequently, privacy leakage. We demonstrate and analyse an Onion Effect of memorization: removing the "layer" of outlier points that are most vulnerable to a privacy attack exposes a new layer of previously-safe points to the same attack. We perform several experiments to study this effect, and understand why it occurs. The existence of this effect has various consequences. For example, it suggests that proposals to defend against memorization without training with rigorous privacy guarantees are unlikely to be effective. Further, it suggests that privacy-enhancing technologies such as machine unlearning could actually harm the privacy of other users.