 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically Controllable Scene Generation with Guidance of Explicit Knowledge
Jun 08, 2021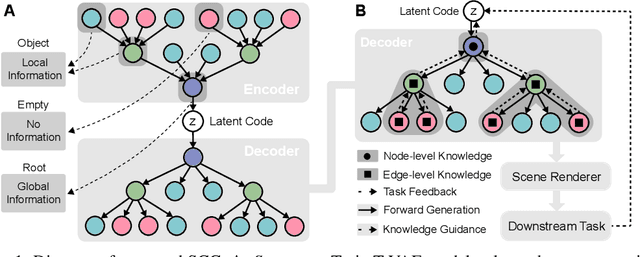

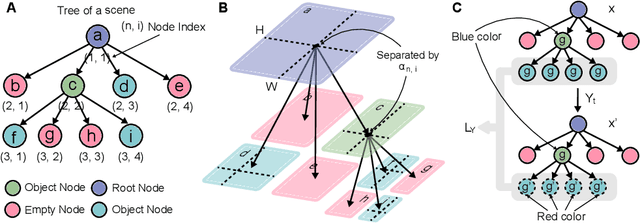

Deep Generative Models (DGMs) are known for their superior capability in generating realistic data. Extending purely data-driven approaches, recent specialized DGMs may satisfy additional controllable requirements such as embedding a traffic sign in a driving scene, by manipulating patterns \textit{implicitly} in the neuron or feature level. In this paper, we introduce a novel method to incorporate domain knowledge \textit{explicitly} in the generation process to achieve semantically controllable scene generation. We categorize our knowledge into two types to be consistent with the composition of natural scenes, where the first type represents the property of objects and the second type represents the relationship among objects. We then propose a tree-structured generative model to learn complex scene representation, whose nodes and edges are naturally corresponding to the two types of knowledge respectively. Knowledge can be explicitly integrated to enable semantically controllable scene generation by imposing semantic rules on properties of nodes and edges in the tree structure. We construct a synthetic example to illustrate the controllability and explainability of our method in a clean setting. We further extend the synthetic example to realistic autonomous vehicle driving environments and conduct extensive experiments to show that our method efficiently identifies adversarial traffic scenes against different state-of-the-art 3D point cloud segmentation models satisfying the traffic rules specified as the explicit knowledge.
Multimodal Safety-Critical Scenarios Generation for Decision-Making Algorithms Evaluation
Sep 25, 2020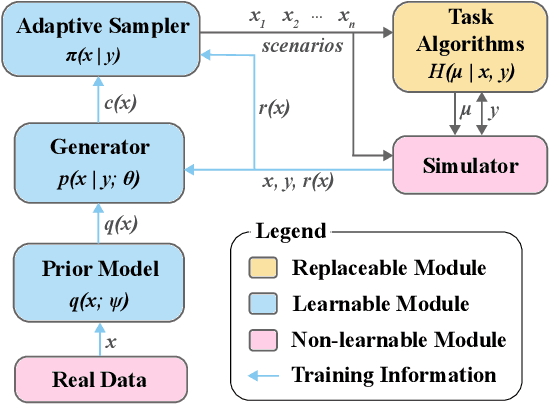

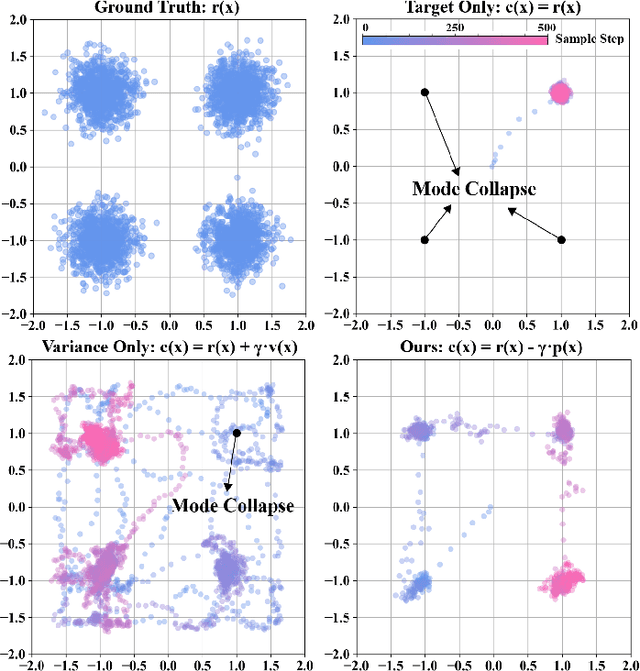
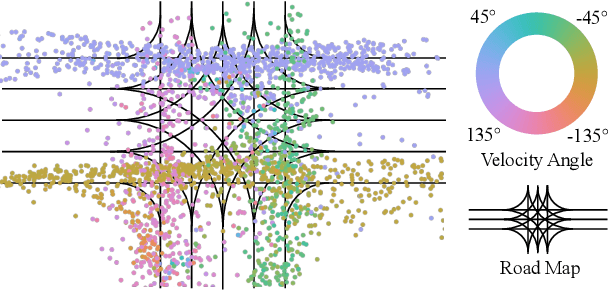
Existing neural network-based autonomous systems are shown to be vulnerable against adversarial attacks, therefore sophisticated evaluation on their robustness is of great importance. However, evaluating the robustness only under the worst-case scenarios based on known attacks is not comprehensive, not to mention that some of them even rarely occur in the real world. In addition, the distribution of safety-critical data is usually multimodal, while most traditional attacks and evaluation methods focus on a single modality. To solve the above challenges, we propose a flow-based multimodal safety-critical scenario generator for evaluating decisionmaking algorithms. The proposed generative model is optimized with weighted likelihood maximization and a gradient-based sampling procedure is integrated to improve the sampling efficiency. The safety-critical scenarios are generated by querying the task algorithms and the log-likelihood of the generated scenarios is in proportion to the risk level. Experiments on a self-driving task demonstrate our advantages in terms of testing efficiency and multimodal modeling capability. We evaluate six Reinforcement Learning algorithms with our generated traffic scenarios and provide empirical conclusions about their robustness.