 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Emotion Recognition Using Multimodal Deep Learning
Paper and Code
Feb 26, 2016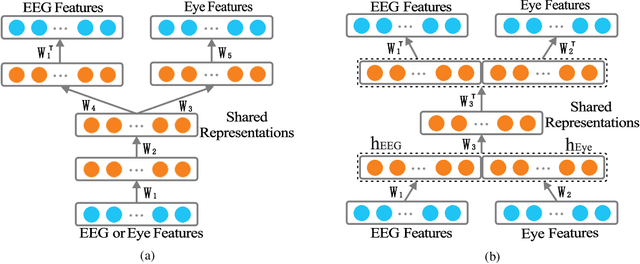
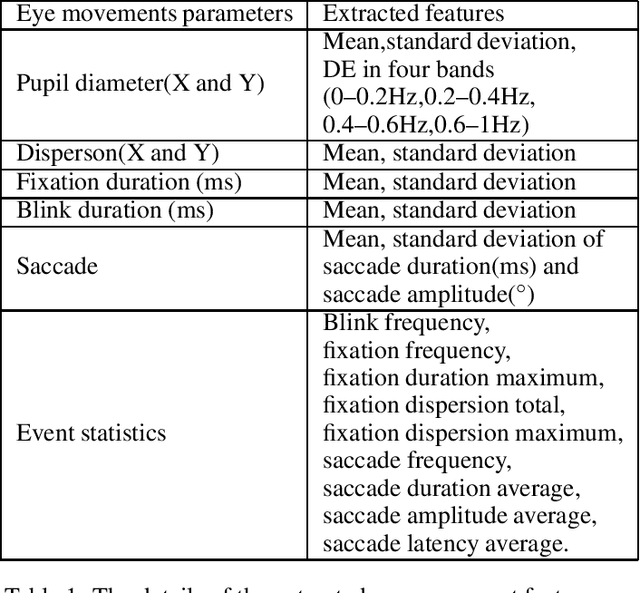
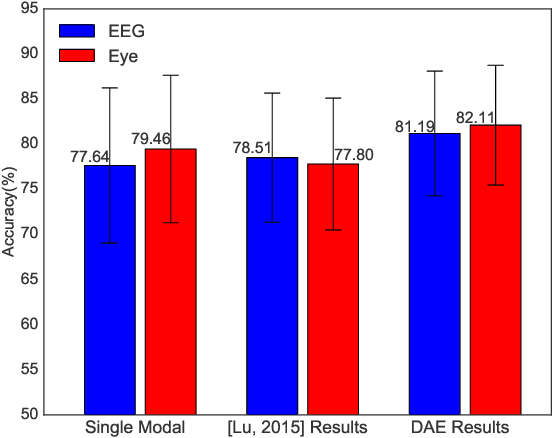
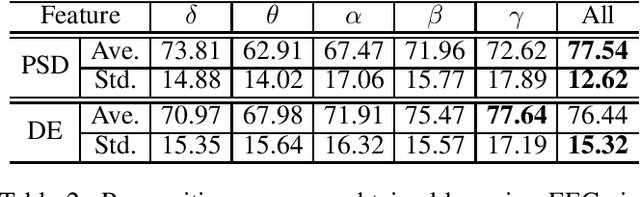
To enhance the performance of affective models and reduce the cost of acquiring physiological signals for real-world applications, we adopt multimodal deep learning approach to construct affective models from multiple physiological signals. For unimodal enhancement task, we indicate that the best recognition accuracy of 82.11% on SEED dataset is achieved with shared representations generated by Deep AutoEncoder (DAE) model. For multimodal facilitation tasks, we demonstrate that the Bimodal Deep AutoEncoder (BDAE) achieves the mean accuracies of 91.01% and 83.25% on SEED and DEAP datasets, respectively, which are much superior to the state-of-the-art approaches. For cross-modal learning task, our experimental results demonstrate that the mean accuracy of 66.34% is achieved on SEED dataset through shared representations generated by EEG-based DAE as training samples and shared representations generated by eye-based DAE as testing sample, and vice versa.