 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoing Experiments and Revising Rules with Natural Language and Probabilistic Reasoning
Feb 19, 2024We build a computational model of how humans actively infer hidden rules by doing experiments. The basic principles behind the model is that, even if the rule is deterministic, the learner considers a broader space of fuzzy probabilistic rules, which it represents in natural language, and updates its hypotheses online after each experiment according to approximately Bayesian principles. In the same framework we also model experiment design according to information-theoretic criteria. We find that the combination of these three principles -- explicit hypotheses, probabilistic rules, and online updates -- can explain human performance on a Zendo-style task, and that removing any of these components leaves the model unable to account for the data.
Diffusion Variational Inference: Diffusion Models as Expressive Variational Posteriors
Jan 05, 2024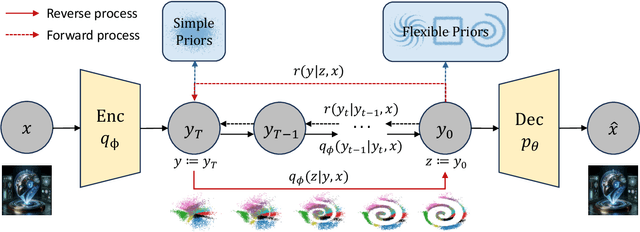

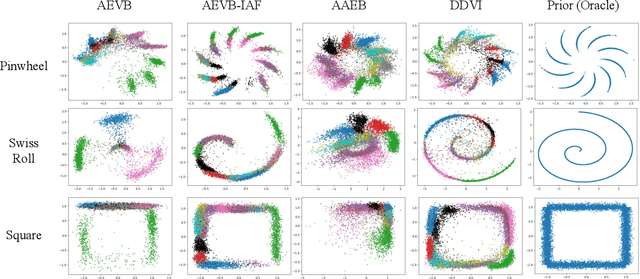

We propose denoising diffusion variational inference (DDVI), an approximate inference algorithm for latent variable models which relies on diffusion models as expressive variational posteriors. Our method augments variational posteriors with auxiliary latents, which yields an expressive class of models that perform diffusion in latent space by reversing a user-specified noising process. We fit these models by optimizing a novel lower bound on the marginal likelihood inspired by the wake-sleep algorithm. Our method is easy to implement (it fits a regularized extension of the ELBO), is compatible with black-box variational inference, and outperforms alternative classes of approximate posteriors based on normalizing flows or adversarial networks. When applied to deep latent variable models, our method yields the denoising diffusion VAE (DD-VAE) algorithm. We use this algorithm on a motivating task in biology -- inferring latent ancestry from human genomes -- outperforming strong baselines on the Thousand Genomes dataset.
Active Preference Inference using Language Models and Probabilistic Reasoning
Dec 19, 2023



Actively inferring user preferences, for example by asking good questions, is important for any human-facing decision-making system. Active inference allows such systems to adapt and personalize themselves to nuanced individual preferences. To enable this ability for instruction-tuned large language models (LLMs), one may prompt them to ask users questions to infer their preferences, transforming the language models into more robust, interactive systems. However, out of the box, these models are not efficient at extracting preferences: the questions they generate are not informative, requiring a high number of user interactions and impeding the usability of the downstream system. In this work, we introduce an inference-time algorithm that helps LLMs quickly infer preferences by using more informative questions. Our algorithm uses a probabilistic model whose conditional distributions are defined by prompting an LLM, and returns questions that optimize expected entropy and expected model change. Results in a simplified interactive web shopping setting with real product items show that an LLM equipped with our entropy reduction algorithm outperforms baselines with the same underlying LLM on task performance while using fewer user interactions.