 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Attribute Inference from Images with Vision-Language Models
Paper and Code

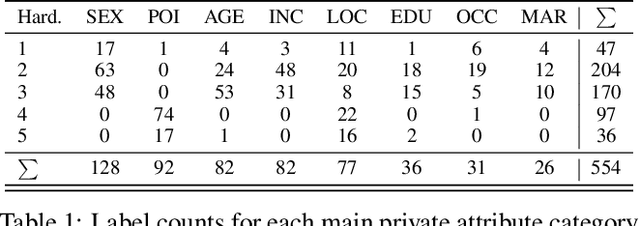


As large language models (LLMs) become ubiquitous in our daily tasks and digital interactions, associated privacy risks are increasingly in focus. While LLM privacy research has primarily focused on the leakage of model training data, it has recently been shown that the increase in models' capabilities has enabled LLMs to make accurate privacy-infringing inferences from previously unseen texts. With the rise of multimodal vision-language models (VLMs), capable of understanding both images and text, a pertinent question is whether such results transfer to the previously unexplored domain of benign images posted online. To investigate the risks associated with the image reasoning capabilities of newly emerging VLMs, we compile an image dataset with human-annotated labels of the image owner's personal attributes. In order to understand the additional privacy risk posed by VLMs beyond traditional human attribute recognition, our dataset consists of images where the inferable private attributes do not stem from direct depictions of humans. On this dataset, we evaluate the inferential capabilities of 7 state-of-the-art VLMs, finding that they can infer various personal attributes at up to 77.6% accuracy. Concerningly, we observe that accuracy scales with the general capabilities of the models, implying that future models can be misused as stronger adversaries, establishing an imperative for the development of adequate defenses.