 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAverage Certified Radius is a Poor Metric for Randomized Smoothing
Paper and Code
Oct 09, 2024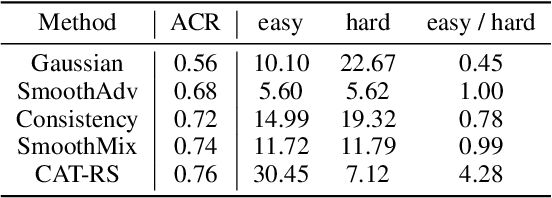
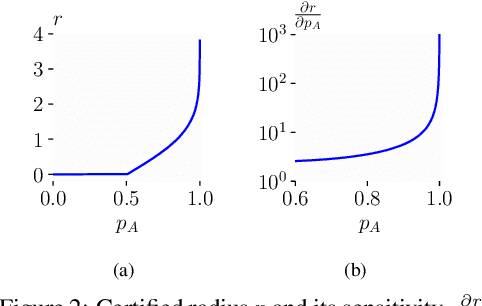
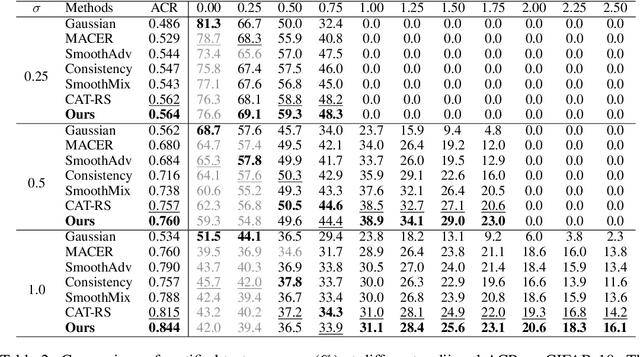
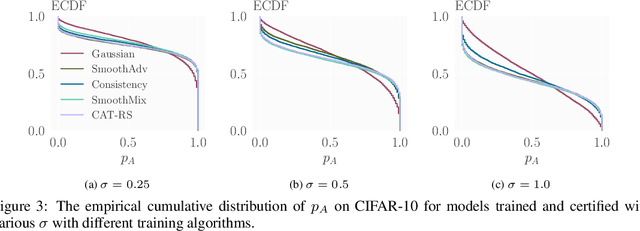
Randomized smoothing is a popular approach for providing certified robustness guarantees against adversarial attacks, and has become a very active area of research. Over the past years, the average certified radius (ACR) has emerged as the single most important metric for comparing methods and tracking progress in the field. However, in this work, we show that ACR is an exceptionally poor metric for evaluating robustness guarantees provided by randomized smoothing. We theoretically show not only that a trivial classifier can have arbitrarily large ACR, but also that ACR is much more sensitive to improvements on easy samples than on hard ones. Empirically, we confirm that existing training strategies that improve ACR reduce the model's robustness on hard samples. Further, we show that by focusing on easy samples, we can effectively replicate the increase in ACR. We develop strategies, including explicitly discarding hard samples, reweighing the dataset with certified radius, and extreme optimization for easy samples, to achieve state-of-the-art ACR, although these strategies ignore robustness for the general data distribution. Overall, our results suggest that ACR has introduced a strong undesired bias to the field, and better metrics are required to holistically evaluate randomized smoothing.