 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Clues of Spoofed LM Watermarks
Paper and Code
Oct 03, 2024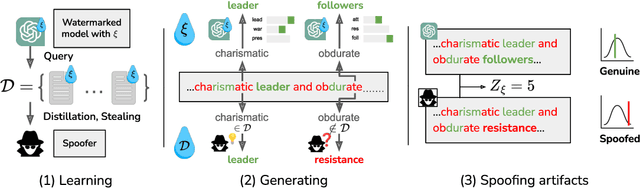
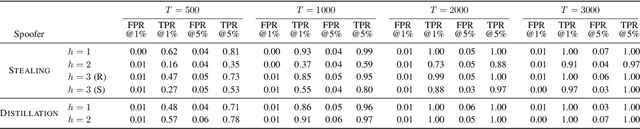
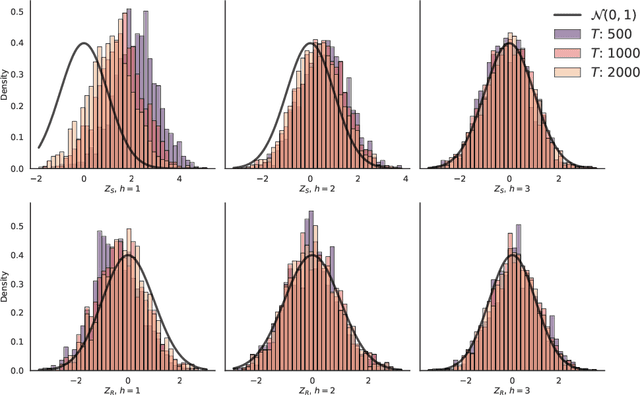
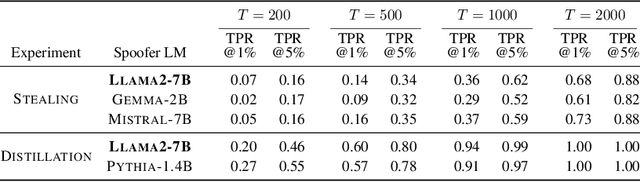
LLM watermarks stand out as a promising way to attribute ownership of LLM-generated text. One threat to watermark credibility comes from spoofing attacks, where an unauthorized third party forges the watermark, enabling it to falsely attribute arbitrary texts to a particular LLM. While recent works have demonstrated that state-of-the-art schemes are in fact vulnerable to spoofing, they lack deeper qualitative analysis of the texts produced by spoofing methods. In this work, we for the first time reveal that there are observable differences between genuine and spoofed watermark texts. Namely, we show that regardless of their underlying approach, all current spoofing methods consistently leave observable artifacts in spoofed texts, indicative of watermark forgery. We build upon these findings to propose rigorous statistical tests that reliably reveal the presence of such artifacts, effectively discovering that a watermark was spoofed. Our experimental evaluation shows high test power across all current spoofing methods, providing insights into their fundamental limitations, and suggesting a way to mitigate this threat.