 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Molecule Generation from Rigid Motifs via SE(3) Flows
Jan 23, 2026Three-dimensional molecular structure generation is typically performed at the level of individual atoms, yet molecular graph generation techniques often consider fragments as their structural units. Building on the advances in frame-based protein structure generation, we extend these fragmentation ideas to 3D, treating general molecules as sets of rigid-body motifs. Utilising this representation, we employ SE(3)-equivariant generative modelling for de novo 3D molecule generation from rigid motifs. In our evaluations, we observe comparable or superior results to state-of-the-art across benchmarks, surpassing it in atom stability on GEOM-Drugs, while yielding a 2x to 10x reduction in generation steps and offering 3.5x compression in molecular representations compared to the standard atom-based methods.
GeoDiffusion: A Training-Free Framework for Accurate 3D Geometric Conditioning in Image Generation
Oct 25, 2025Precise geometric control in image generation is essential for engineering \& product design and creative industries to control 3D object features accurately in image space. Traditional 3D editing approaches are time-consuming and demand specialized skills, while current image-based generative methods lack accuracy in geometric conditioning. To address these challenges, we propose GeoDiffusion, a training-free framework for accurate and efficient geometric conditioning of 3D features in image generation. GeoDiffusion employs a class-specific 3D object as a geometric prior to define keypoints and parametric correlations in 3D space. We ensure viewpoint consistency through a rendered image of a reference 3D object, followed by style transfer to meet user-defined appearance specifications. At the core of our framework is GeoDrag, improving accuracy and speed of drag-based image editing on geometry guidance tasks and general instructions on DragBench. Our results demonstrate that GeoDiffusion enables precise geometric modifications across various iterative design workflows.
Energy-Weighted Flow Matching: Unlocking Continuous Normalizing Flows for Efficient and Scalable Boltzmann Sampling
Sep 03, 2025

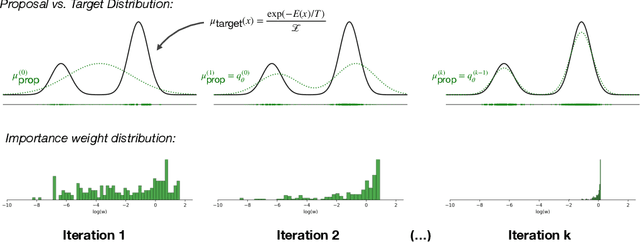

Sampling from unnormalized target distributions, e.g. Boltzmann distributions $\mu_{\text{target}}(x) \propto \exp(-E(x)/T)$, is fundamental to many scientific applications yet computationally challenging due to complex, high-dimensional energy landscapes. Existing approaches applying modern generative models to Boltzmann distributions either require large datasets of samples drawn from the target distribution or, when using only energy evaluations for training, cannot efficiently leverage the expressivity of advanced architectures like continuous normalizing flows that have shown promise for molecular sampling. To address these shortcomings, we introduce Energy-Weighted Flow Matching (EWFM), a novel training objective enabling continuous normalizing flows to model Boltzmann distributions using only energy function evaluations. Our objective reformulates conditional flow matching via importance sampling, allowing training with samples from arbitrary proposal distributions. Based on this objective, we develop two algorithms: iterative EWFM (iEWFM), which progressively refines proposals through iterative training, and annealed EWFM (aEWFM), which additionally incorporates temperature annealing for challenging energy landscapes. On benchmark systems, including challenging 55-particle Lennard-Jones clusters, our algorithms demonstrate sample quality competitive with state-of-the-art energy-only methods while requiring up to three orders of magnitude fewer energy evaluations.
Byte Pair Encoding for Efficient Time Series Forecasting
May 20, 2025Existing time series tokenization methods predominantly encode a constant number of samples into individual tokens. This inflexible approach can generate excessive tokens for even simple patterns like extended constant values, resulting in substantial computational overhead. Inspired by the success of byte pair encoding, we propose the first pattern-centric tokenization scheme for time series analysis. Based on a discrete vocabulary of frequent motifs, our method merges samples with underlying patterns into tokens, compressing time series adaptively. Exploiting our finite set of motifs and the continuous properties of time series, we further introduce conditional decoding as a lightweight yet powerful post-hoc optimization method, which requires no gradient computation and adds no computational overhead. On recent time series foundation models, our motif-based tokenization improves forecasting performance by 36% and boosts efficiency by 1990% on average. Conditional decoding further reduces MSE by up to 44%. In an extensive analysis, we demonstrate the adaptiveness of our tokenization to diverse temporal patterns, its generalization to unseen data, and its meaningful token representations capturing distinct time series properties, including statistical moments and trends.
Generative Modeling with Bayesian Sample Inference
Feb 11, 2025We derive a novel generative model from the simple act of Gaussian posterior inference. Treating the generated sample as an unknown variable to infer lets us formulate the sampling process in the language of Bayesian probability. Our model uses a sequence of prediction and posterior update steps to narrow down the unknown sample from a broad initial belief. In addition to a rigorous theoretical analysis, we establish a connection between our model and diffusion models and show that it includes Bayesian Flow Networks (BFNs) as a special case. In our experiments, we demonstrate improved performance over both BFNs and Variational Diffusion Models, achieving competitive likelihood scores on CIFAR10 and ImageNet.
Unlocking Point Processes through Point Set Diffusion
Oct 29, 2024



Point processes model the distribution of random point sets in mathematical spaces, such as spatial and temporal domains, with applications in fields like seismology, neuroscience, and economics. Existing statistical and machine learning models for point processes are predominantly constrained by their reliance on the characteristic intensity function, introducing an inherent trade-off between efficiency and flexibility. In this paper, we introduce Point Set Diffusion, a diffusion-based latent variable model that can represent arbitrary point processes on general metric spaces without relying on the intensity function. By directly learning to stochastically interpolate between noise and data point sets, our approach enables efficient, parallel sampling and flexible generation for complex conditional tasks defined on the metric space. Experiments on synthetic and real-world datasets demonstrate that Point Set Diffusion achieves state-of-the-art performance in unconditional and conditional generation of spatial and spatiotemporal point processes while providing up to orders of magnitude faster sampling than autoregressive baselines.
Flow Matching with Gaussian Process Priors for Probabilistic Time Series Forecasting
Oct 03, 2024Recent advancements in generative modeling, particularly diffusion models, have opened new directions for time series modeling, achieving state-of-the-art performance in forecasting and synthesis. However, the reliance of diffusion-based models on a simple, fixed prior complicates the generative process since the data and prior distributions differ significantly. We introduce TSFlow, a conditional flow matching (CFM) model for time series that simplifies the generative problem by combining Gaussian processes, optimal transport paths, and data-dependent prior distributions. By incorporating (conditional) Gaussian processes, TSFlow aligns the prior distribution more closely with the temporal structure of the data, enhancing both unconditional and conditional generation. Furthermore, we propose conditional prior sampling to enable probabilistic forecasting with an unconditionally trained model. In our experimental evaluation on eight real-world datasets, we demonstrate the generative capabilities of TSFlow, producing high-quality unconditional samples. Finally, we show that both conditionally and unconditionally trained models achieve competitive results in forecasting benchmarks, surpassing other methods on 6 out of 8 datasets.
Efficient Time Series Processing for Transformers and State-Space Models through Token Merging
May 28, 2024Transformer architectures have shown promising results in time series processing. However, despite recent advances in subquadratic attention mechanisms or state-space models, processing very long sequences still imposes significant computational requirements. Token merging, which involves replacing multiple tokens with a single one calculated as their linear combination, has shown to considerably improve the throughput of vision transformer architectures while maintaining accuracy. In this work, we go beyond computer vision and perform the first investigations of token merging in time series analysis on both time series transformers and state-space models. To effectively scale token merging to long sequences, we introduce local merging, a domain-specific token merging algorithm that selectively combines tokens within a local neighborhood, adjusting the computational complexity from linear to quadratic based on the neighborhood size. Our comprehensive empirical evaluation demonstrates that token merging offers substantial computational benefits with minimal impact on accuracy across various models and datasets. On the recently proposed Chronos foundation model, we achieve accelerations up to 5400% with only minor accuracy degradations.
Assessing Robustness via Score-Based Adversarial Image Generation
Oct 06, 2023

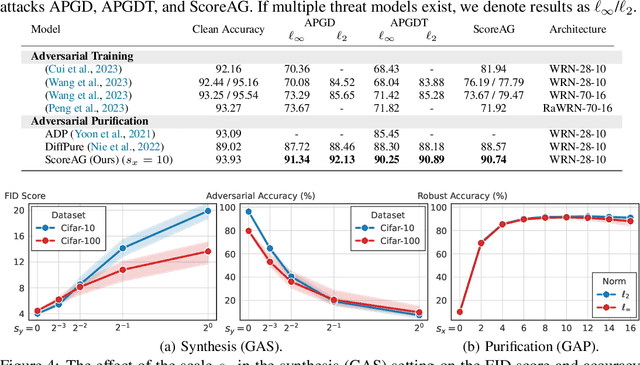
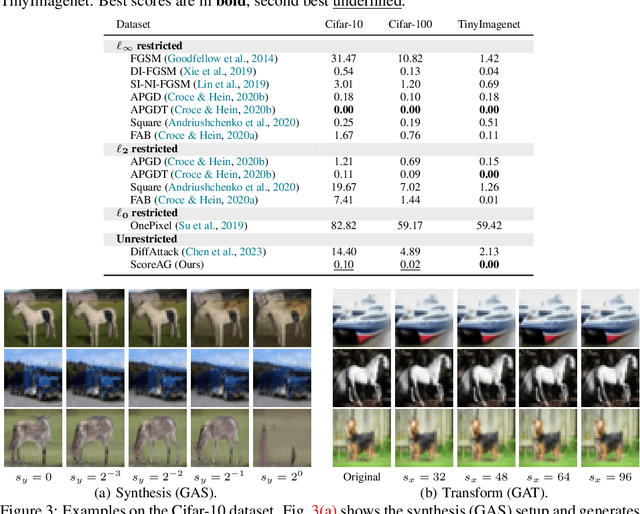
Most adversarial attacks and defenses focus on perturbations within small $\ell_p$-norm constraints. However, $\ell_p$ threat models cannot capture all relevant semantic-preserving perturbations, and hence, the scope of robustness evaluations is limited. In this work, we introduce Score-Based Adversarial Generation (ScoreAG), a novel framework that leverages the advancements in score-based generative models to generate adversarial examples beyond $\ell_p$-norm constraints, so-called unrestricted adversarial examples, overcoming their limitations. Unlike traditional methods, ScoreAG maintains the core semantics of images while generating realistic adversarial examples, either by transforming existing images or synthesizing new ones entirely from scratch. We further exploit the generative capability of ScoreAG to purify images, empirically enhancing the robustness of classifiers. Our extensive empirical evaluation demonstrates that ScoreAG matches the performance of state-of-the-art attacks and defenses across multiple benchmarks. This work highlights the importance of investigating adversarial examples bounded by semantics rather than $\ell_p$-norm constraints. ScoreAG represents an important step towards more encompassing robustness assessments.
Predict, Refine, Synthesize: Self-Guiding Diffusion Models for Probabilistic Time Series Forecasting
Jul 21, 2023Diffusion models have achieved state-of-the-art performance in generative modeling tasks across various domains. Prior works on time series diffusion models have primarily focused on developing conditional models tailored to specific forecasting or imputation tasks. In this work, we explore the potential of task-agnostic, unconditional diffusion models for several time series applications. We propose TSDiff, an unconditionally trained diffusion model for time series. Our proposed self-guidance mechanism enables conditioning TSDiff for downstream tasks during inference, without requiring auxiliary networks or altering the training procedure. We demonstrate the effectiveness of our method on three different time series tasks: forecasting, refinement, and synthetic data generation. First, we show that TSDiff is competitive with several task-specific conditional forecasting methods (predict). Second, we leverage the learned implicit probability density of TSDiff to iteratively refine the predictions of base forecasters with reduced computational overhead over reverse diffusion (refine). Notably, the generative performance of the model remains intact -- downstream forecasters trained on synthetic samples from TSDiff outperform forecasters that are trained on samples from other state-of-the-art generative time series models, occasionally even outperforming models trained on real data (synthesize).