 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning from Unlabeled Fundus Photographs Improves Segmentation of the Retina
Aug 05, 2021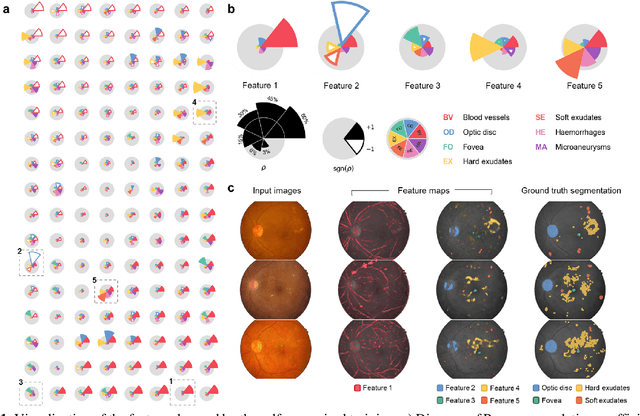
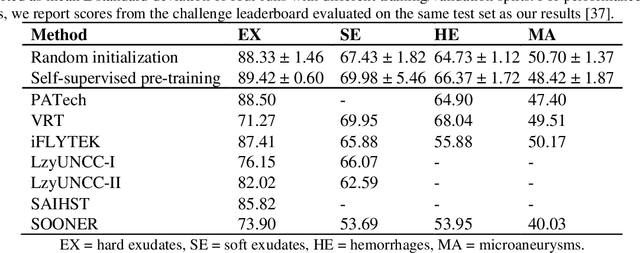
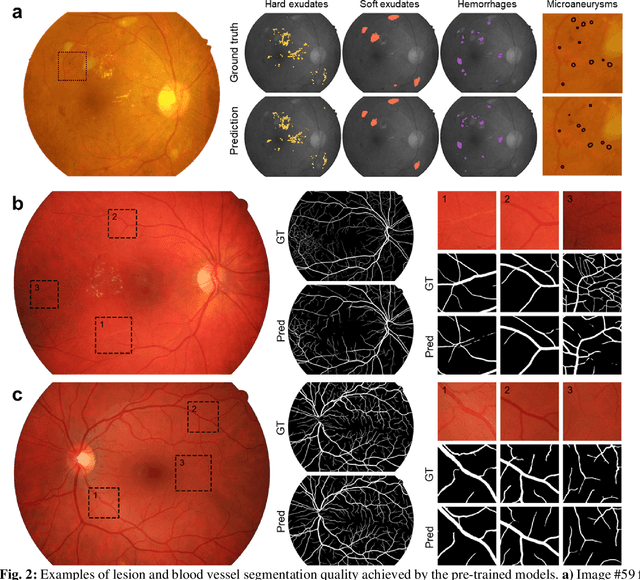
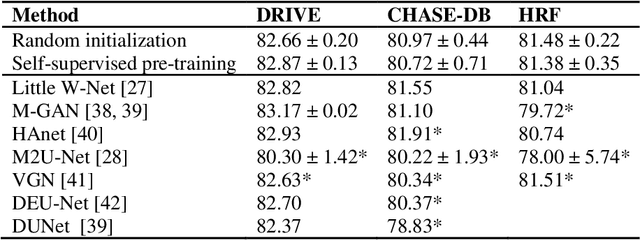
Fundus photography is the primary method for retinal imaging and essential for diabetic retinopathy prevention. Automated segmentation of fundus photographs would improve the quality, capacity, and cost-effectiveness of eye care screening programs. However, current segmentation methods are not robust towards the diversity in imaging conditions and pathologies typical for real-world clinical applications. To overcome these limitations, we utilized contrastive self-supervised learning to exploit the large variety of unlabeled fundus images in the publicly available EyePACS dataset. We pre-trained an encoder of a U-Net, which we later fine-tuned on several retinal vessel and lesion segmentation datasets. We demonstrate for the first time that by using contrastive self-supervised learning, the pre-trained network can recognize blood vessels, optic disc, fovea, and various lesions without being provided any labels. Furthermore, when fine-tuned on a downstream blood vessel segmentation task, such pre-trained networks achieve state-of-the-art performance on images from different datasets. Additionally, the pre-training also leads to shorter training times and an improved few-shot performance on both blood vessel and lesion segmentation tasks. Altogether, our results showcase the benefits of contrastive self-supervised pre-training which can play a crucial role in real-world clinical applications requiring robust models able to adapt to new devices with only a few annotated samples.
VerSe: A Vertebrae Labelling and Segmentation Benchmark
Jan 24, 2020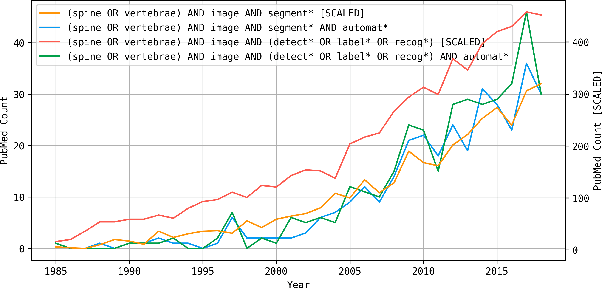
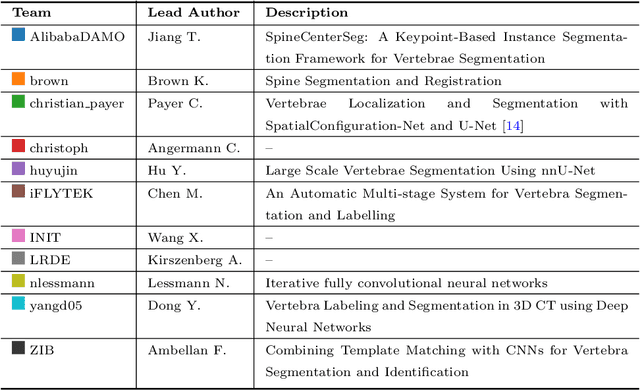
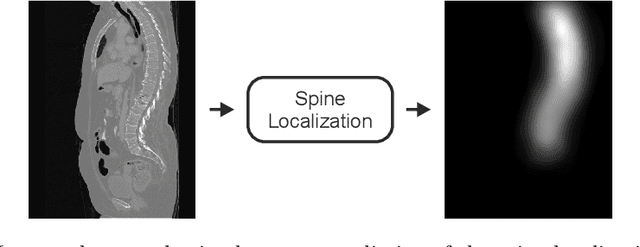
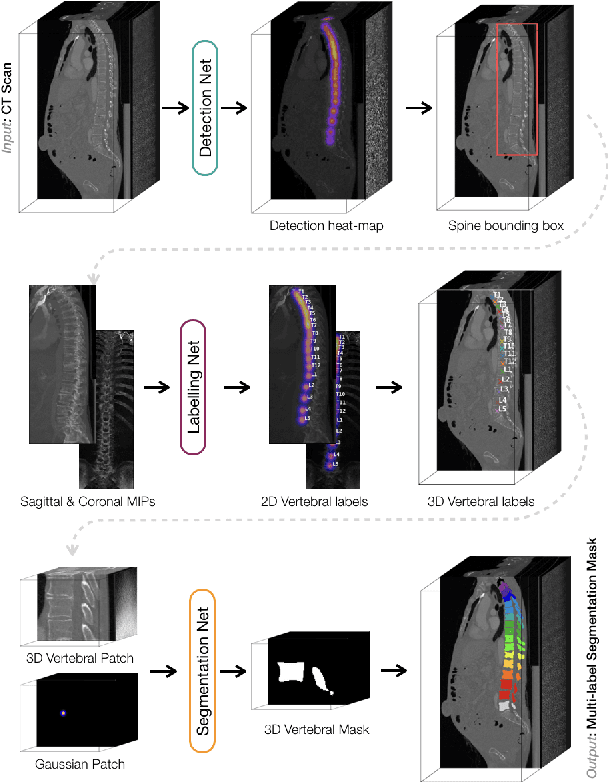
In this paper we report the challenge set-up and results of the Large Scale Vertebrae Segmentation Challenge (VerSe) organized in conjunction with the MICCAI 2019. The challenge consisted of two tasks, vertebrae labelling and vertebrae segmentation. For this a total of 160 multidetector CT scan cohort closely resembling clinical setting was prepared and was annotated at a voxel-level by a human-machine hybrid algorithm. In this paper we also present the annotation protocol and the algorithm that aided the medical experts in the annotation process. Eleven fully automated algorithms were benchmarked on this data with the best performing algorithm achieving a vertebrae identification rate of 95% and a Dice coefficient of 90%. VerSe'19 is an open-call challenge at its image data along with the annotations and evaluation tools will continue to be publicly accessible through its online portal.
Btrfly Net: Vertebrae Labelling with Energy-based Adversarial Learning of Local Spine Prior
Apr 04, 2018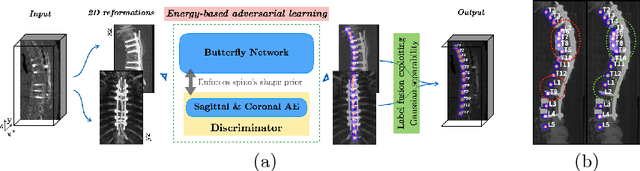
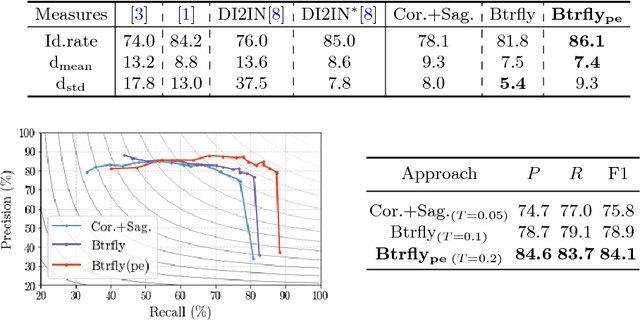
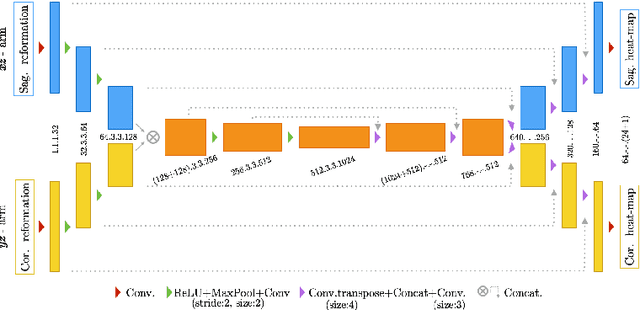
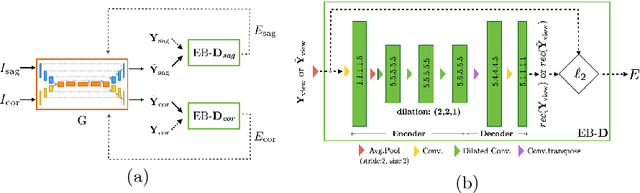
Robust localisation and identification of vertebrae is an essential part of automated spine analysis. The contribution of this work to the task is two-fold: (1) Inspired by the human expert, we hypothesise that a sagittal and coronal reformation of the spine contain sufficient information for labelling the vertebrae. Thereby, we propose a butterfly-shaped network architecture (termed Btrfly Net) that efficiently combines the information across the reformations. (2) Underpinning the Btrfly net, we present an energy-based adversarial training regime that encodes the local spine structure as an anatomical prior into the network, thereby enabling it to achieve state-of-art performance in all standard metrics on a benchmark dataset of 302 scans without any post-processing during inference.
Regularization for Deep Learning: A Taxonomy
Oct 29, 2017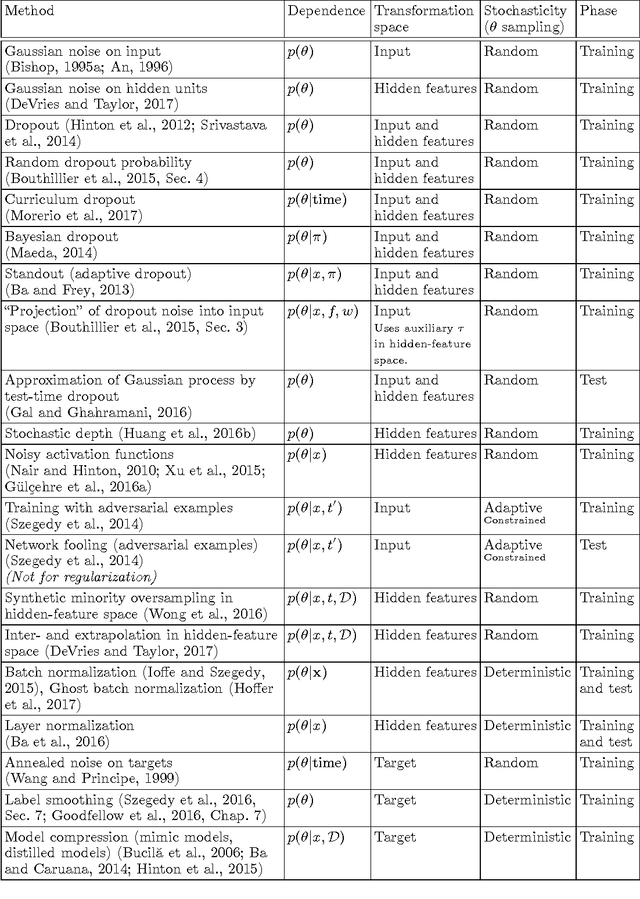
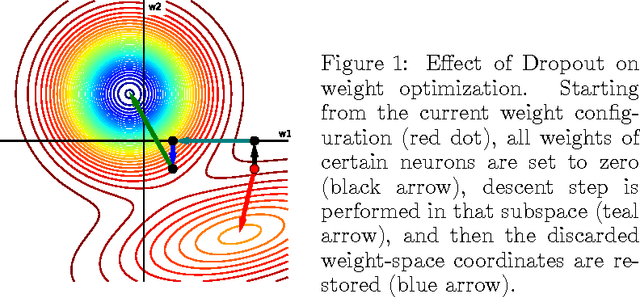
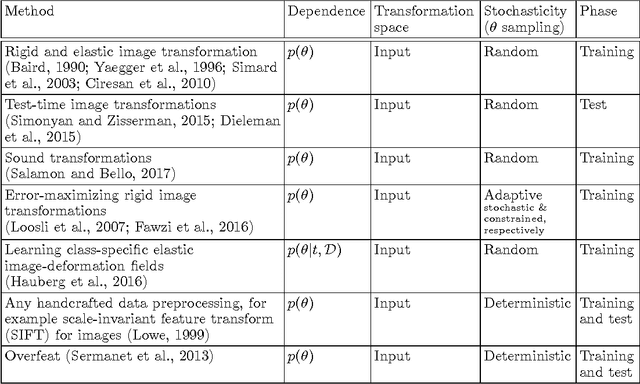
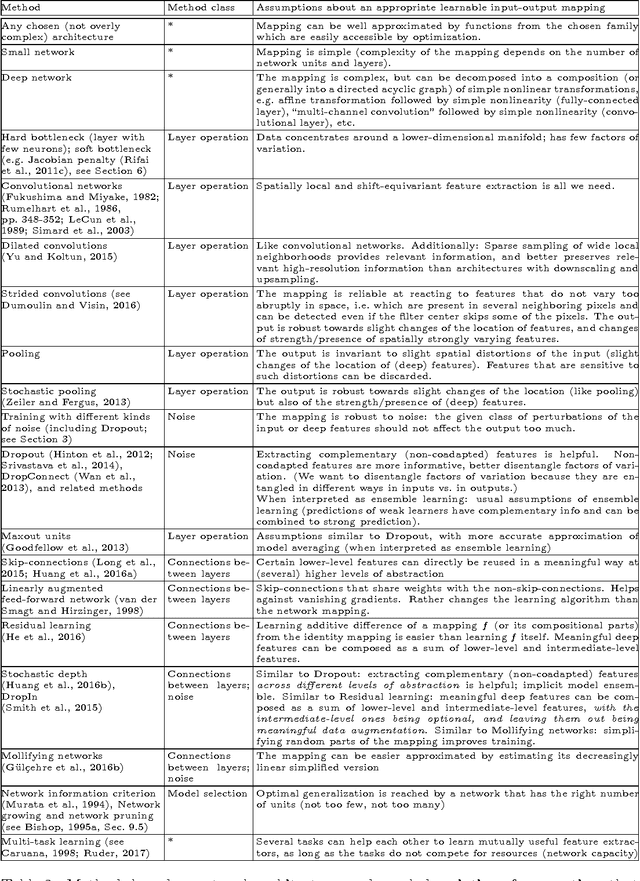
Regularization is one of the crucial ingredients of deep learning, yet the term regularization has various definitions, and regularization methods are often studied separately from each other. In our work we present a systematic, unifying taxonomy to categorize existing methods. We distinguish methods that affect data, network architectures, error terms, regularization terms, and optimization procedures. We do not provide all details about the listed methods; instead, we present an overview of how the methods can be sorted into meaningful categories and sub-categories. This helps revealing links and fundamental similarities between them. Finally, we include practical recommendations both for users and for developers of new regularization methods.