 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning from Unlabeled Fundus Photographs Improves Segmentation of the Retina
Aug 05, 2021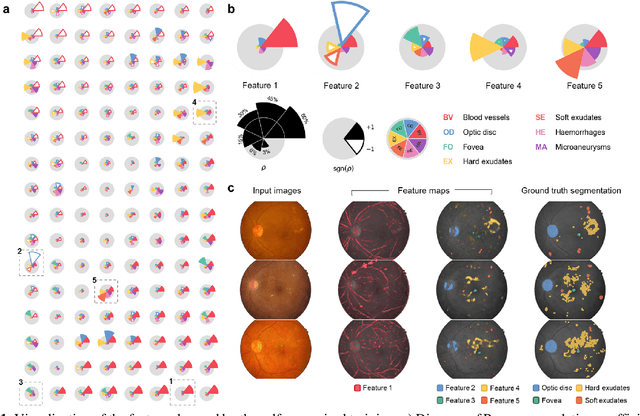
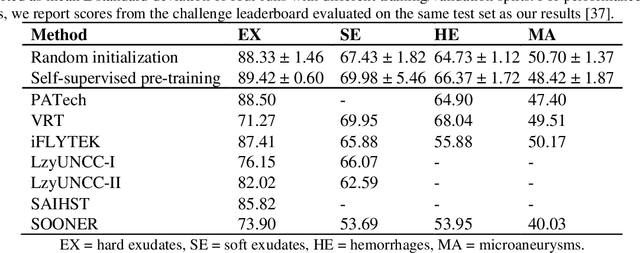
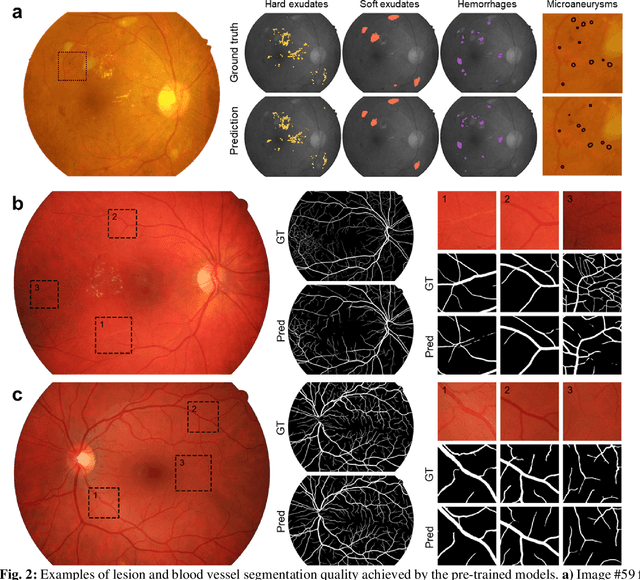
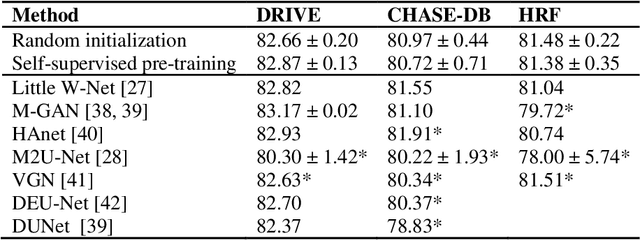
Fundus photography is the primary method for retinal imaging and essential for diabetic retinopathy prevention. Automated segmentation of fundus photographs would improve the quality, capacity, and cost-effectiveness of eye care screening programs. However, current segmentation methods are not robust towards the diversity in imaging conditions and pathologies typical for real-world clinical applications. To overcome these limitations, we utilized contrastive self-supervised learning to exploit the large variety of unlabeled fundus images in the publicly available EyePACS dataset. We pre-trained an encoder of a U-Net, which we later fine-tuned on several retinal vessel and lesion segmentation datasets. We demonstrate for the first time that by using contrastive self-supervised learning, the pre-trained network can recognize blood vessels, optic disc, fovea, and various lesions without being provided any labels. Furthermore, when fine-tuned on a downstream blood vessel segmentation task, such pre-trained networks achieve state-of-the-art performance on images from different datasets. Additionally, the pre-training also leads to shorter training times and an improved few-shot performance on both blood vessel and lesion segmentation tasks. Altogether, our results showcase the benefits of contrastive self-supervised pre-training which can play a crucial role in real-world clinical applications requiring robust models able to adapt to new devices with only a few annotated samples.