 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiomedical Concept Relatedness -- A large EHR-based benchmark
Oct 30, 2020
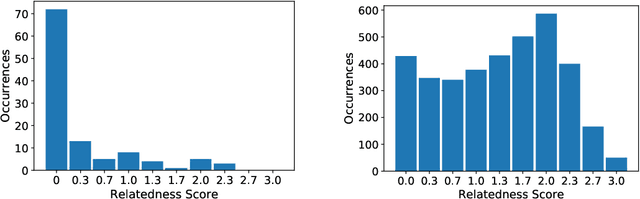
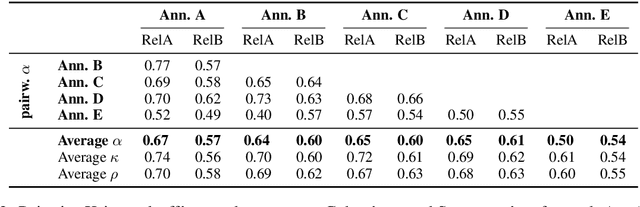
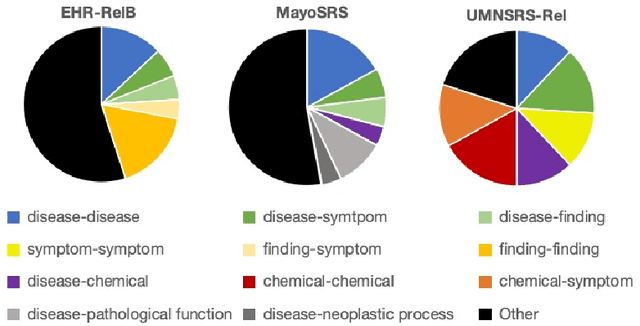
A promising application of AI to healthcare is the retrieval of information from electronic health records (EHRs), e.g. to aid clinicians in finding relevant information for a consultation or to recruit suitable patients for a study. This requires search capabilities far beyond simple string matching, including the retrieval of concepts (diagnoses, symptoms, medications, etc.) related to the one in question. The suitability of AI methods for such applications is tested by predicting the relatedness of concepts with known relatedness scores. However, all existing biomedical concept relatedness datasets are notoriously small and consist of hand-picked concept pairs. We open-source a novel concept relatedness benchmark overcoming these issues: it is six times larger than existing datasets and concept pairs are chosen based on co-occurrence in EHRs, ensuring their relevance for the application of interest. We present an in-depth analysis of our new dataset and compare it to existing ones, highlighting that it is not only larger but also complements existing datasets in terms of the types of concepts included. Initial experiments with state-of-the-art embedding methods show that our dataset is a challenging new benchmark for testing concept relatedness models.