 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Balanced Neuro-Symbolic Approach for Commonsense Abductive Logic
Jan 26, 2026Although Large Language Models (LLMs) have demonstrated impressive formal reasoning abilities, they often break down when problems require complex proof planning. One promising approach for improving LLM reasoning abilities involves translating problems into formal logic and using a logic solver. Although off-the-shelf logic solvers are in principle substantially more efficient than LLMs at logical reasoning, they assume that all relevant facts are provided in a question and are unable to deal with missing commonsense relations. In this work, we propose a novel method that uses feedback from the logic solver to augment a logic problem with commonsense relations provided by the LLM, in an iterative manner. This involves a search procedure through potential commonsense assumptions to maximize the chance of finding useful facts while keeping cost tractable. On a collection of pure-logical reasoning datasets, from which some commonsense information has been removed, our method consistently achieves considerable improvements over existing techniques, demonstrating the value in balancing neural and symbolic elements when working in human contexts.
The Graph's Apprentice: Teaching an LLM Low Level Knowledge for Circuit Quality Estimation
Oct 30, 2024Logic synthesis is a crucial phase in the circuit design process, responsible for transforming hardware description language (HDL) designs into optimized netlists. However, traditional logic synthesis methods are computationally intensive, restricting their iterative use in refining chip designs. Recent advancements in large language models (LLMs), particularly those fine-tuned on programming languages, present a promising alternative. In this paper, we introduce VeriDistill, the first end-to-end machine learning model that directly processes raw Verilog code to predict circuit quality-of-result metrics. Our model employs a novel knowledge distillation method, transferring low-level circuit insights via graphs into the predictor based on LLM. Experiments show VeriDistill outperforms state-of-the-art baselines on large-scale Verilog datasets and demonstrates robust performance when evaluated on out-of-distribution datasets.
GraSS: Combining Graph Neural Networks with Expert Knowledge for SAT Solver Selection
May 17, 2024

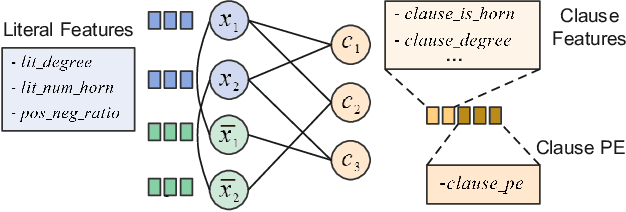

Boolean satisfiability (SAT) problems are routinely solved by SAT solvers in real-life applications, yet solving time can vary drastically between solvers for the same instance. This has motivated research into machine learning models that can predict, for a given SAT instance, which solver to select among several options. Existing SAT solver selection methods all rely on some hand-picked instance features, which are costly to compute and ignore the structural information in SAT graphs. In this paper we present GraSS, a novel approach for automatic SAT solver selection based on tripartite graph representations of instances and a heterogeneous graph neural network (GNN) model. While GNNs have been previously adopted in other SAT-related tasks, they do not incorporate any domain-specific knowledge and ignore the runtime variation introduced by different clause orders. We enrich the graph representation with domain-specific decisions, such as novel node feature design, positional encodings for clauses in the graph, a GNN architecture tailored to our tripartite graphs and a runtime-sensitive loss function. Through extensive experiments, we demonstrate that this combination of raw representations and domain-specific choices leads to improvements in runtime for a pool of seven state-of-the-art solvers on both an industrial circuit design benchmark, and on instances from the 20-year Anniversary Track of the 2022 SAT Competition.