 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Graph's Apprentice: Teaching an LLM Low Level Knowledge for Circuit Quality Estimation
Oct 30, 2024Logic synthesis is a crucial phase in the circuit design process, responsible for transforming hardware description language (HDL) designs into optimized netlists. However, traditional logic synthesis methods are computationally intensive, restricting their iterative use in refining chip designs. Recent advancements in large language models (LLMs), particularly those fine-tuned on programming languages, present a promising alternative. In this paper, we introduce VeriDistill, the first end-to-end machine learning model that directly processes raw Verilog code to predict circuit quality-of-result metrics. Our model employs a novel knowledge distillation method, transferring low-level circuit insights via graphs into the predictor based on LLM. Experiments show VeriDistill outperforms state-of-the-art baselines on large-scale Verilog datasets and demonstrates robust performance when evaluated on out-of-distribution datasets.
WERank: Towards Rank Degradation Prevention for Self-Supervised Learning Using Weight Regularization
Feb 14, 2024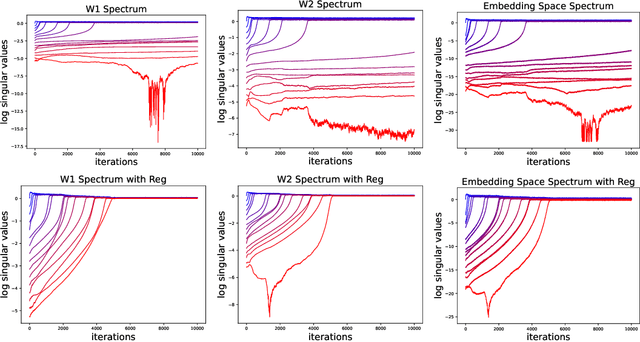
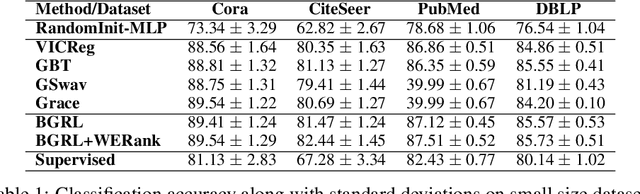
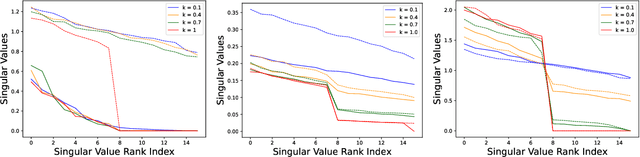
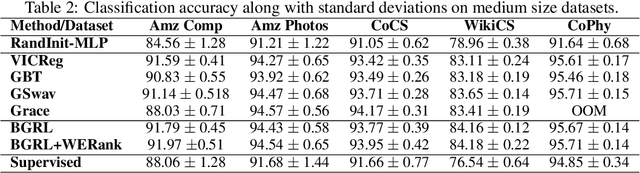
A common phenomena confining the representation quality in Self-Supervised Learning (SSL) is dimensional collapse (also known as rank degeneration), where the learned representations are mapped to a low dimensional subspace of the representation space. The State-of-the-Art SSL methods have shown to suffer from dimensional collapse and fall behind maintaining full rank. Recent approaches to prevent this problem have proposed using contrastive losses, regularization techniques, or architectural tricks. We propose WERank, a new regularizer on the weight parameters of the network to prevent rank degeneration at different layers of the network. We provide empirical evidence and mathematical justification to demonstrate the effectiveness of the proposed regularization method in preventing dimensional collapse. We verify the impact of WERank on graph SSL where dimensional collapse is more pronounced due to the lack of proper data augmentation. We empirically demonstrate that WERank is effective in helping BYOL to achieve higher rank during SSL pre-training and consequently downstream accuracy during evaluation probing. Ablation studies and experimental analysis shed lights on the underlying factors behind the performance gains of the proposed approach.
Scalable Graph Self-Supervised Learning
Feb 14, 2024



In regularization Self-Supervised Learning (SSL) methods for graphs, computational complexity increases with the number of nodes in graphs and embedding dimensions. To mitigate the scalability of non-contrastive graph SSL, we propose a novel approach to reduce the cost of computing the covariance matrix for the pre-training loss function with volume-maximization terms. Our work focuses on reducing the cost associated with the loss computation via graph node or dimension sampling. We provide theoretical insight into why dimension sampling would result in accurate loss computations and support it with mathematical derivation of the novel approach. We develop our experimental setup on the node-level graph prediction tasks, where SSL pre-training has shown to be difficult due to the large size of real world graphs. Our experiments demonstrate that the cost associated with the loss computation can be reduced via node or dimension sampling without lowering the downstream performance. Our results demonstrate that sampling mostly results in improved downstream performance. Ablation studies and experimental analysis are provided to untangle the role of the different factors in the experimental setup.
Deep Policies for Online Bipartite Matching: A Reinforcement Learning Approach
Sep 21, 2021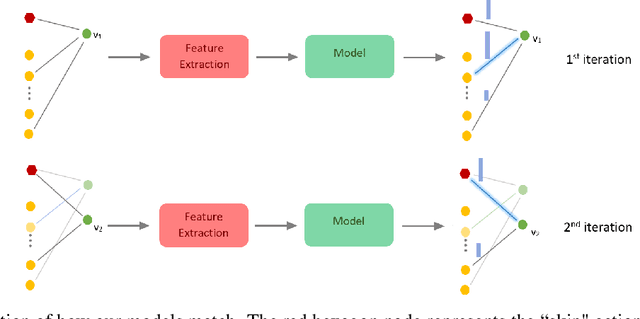
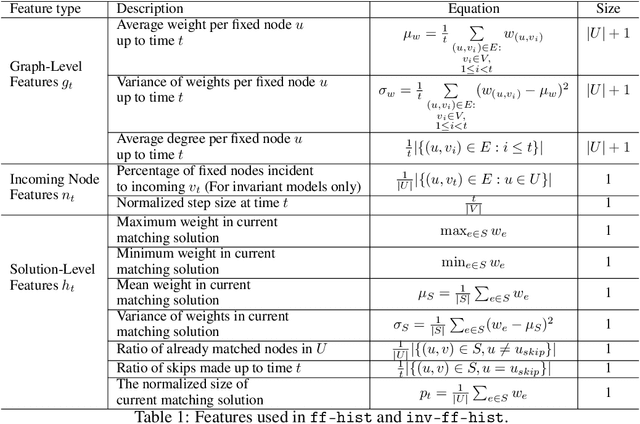
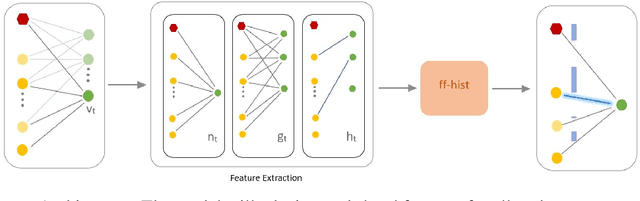
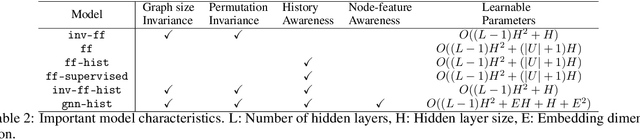
From assigning computing tasks to servers and advertisements to users, sequential online matching problems arise in a wide variety of domains. The challenge in online matching lies in making irrevocable assignments while there is uncertainty about future inputs. In the theoretical computer science literature, most policies are myopic or greedy in nature. In real-world applications where the matching process is repeated on a regular basis, the underlying data distribution can be leveraged for better decision-making. We present an end-to-end Reinforcement Learning framework for deriving better matching policies based on trial-and-error on historical data. We devise a set of neural network architectures, design feature representations, and empirically evaluate them across two online matching problems: Edge-Weighted Online Bipartite Matching and Online Submodular Bipartite Matching. We show that most of the learning approaches perform significantly better than classical greedy algorithms on four synthetic and real-world datasets. Our code is publicly available at https://github.com/lyeskhalil/CORL.git.