 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Policies for Online Bipartite Matching: A Reinforcement Learning Approach
Paper and Code
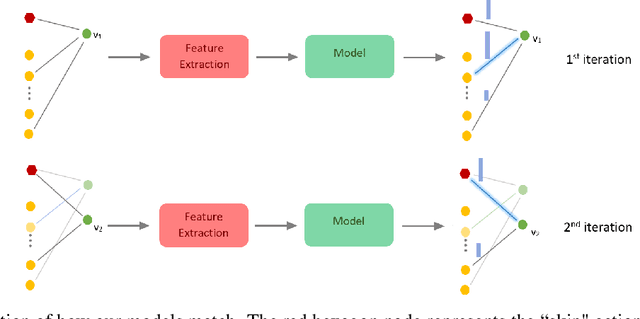
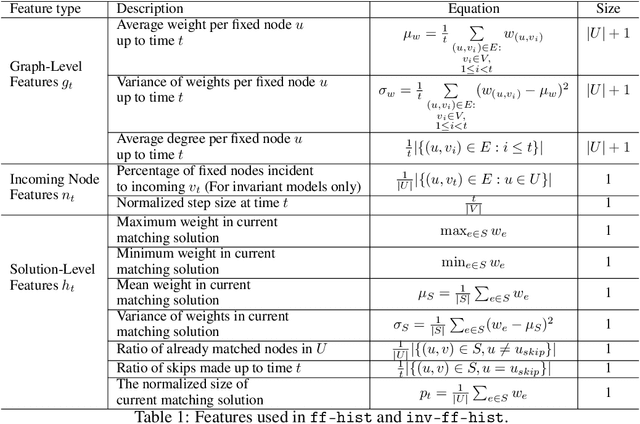
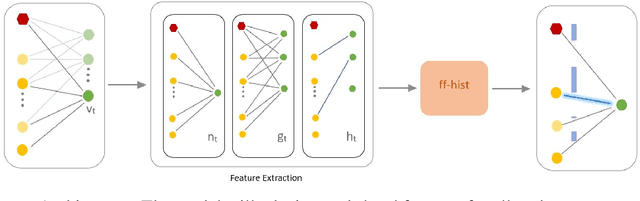
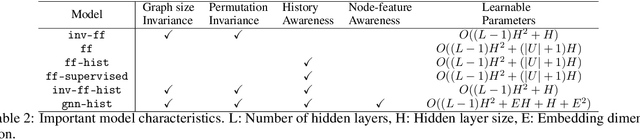
From assigning computing tasks to servers and advertisements to users, sequential online matching problems arise in a wide variety of domains. The challenge in online matching lies in making irrevocable assignments while there is uncertainty about future inputs. In the theoretical computer science literature, most policies are myopic or greedy in nature. In real-world applications where the matching process is repeated on a regular basis, the underlying data distribution can be leveraged for better decision-making. We present an end-to-end Reinforcement Learning framework for deriving better matching policies based on trial-and-error on historical data. We devise a set of neural network architectures, design feature representations, and empirically evaluate them across two online matching problems: Edge-Weighted Online Bipartite Matching and Online Submodular Bipartite Matching. We show that most of the learning approaches perform significantly better than classical greedy algorithms on four synthetic and real-world datasets. Our code is publicly available at https://github.com/lyeskhalil/CORL.git.