 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Rotation Invariance in Object Detection
Oct 01, 2021
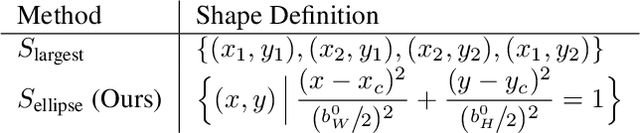
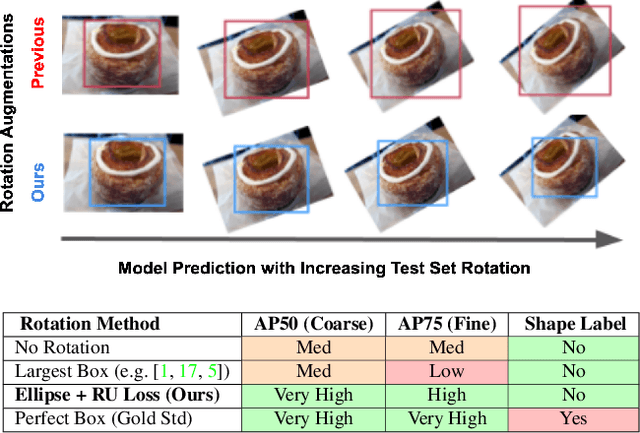
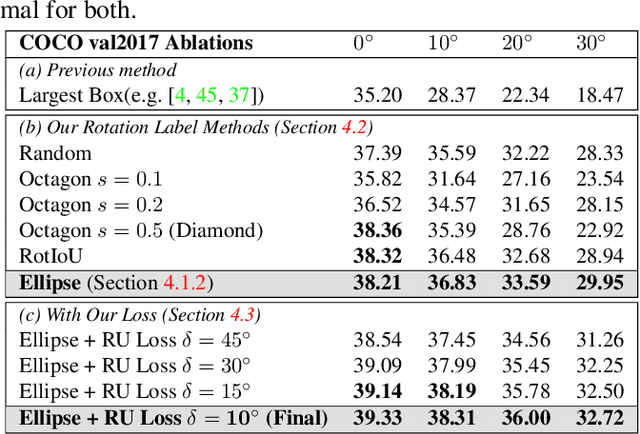
Rotation augmentations generally improve a model's invariance/equivariance to rotation - except in object detection. In object detection the shape is not known, therefore rotation creates a label ambiguity. We show that the de-facto method for bounding box label rotation, the Largest Box Method, creates very large labels, leading to poor performance and in many cases worse performance than using no rotation at all. We propose a new method of rotation augmentation that can be implemented in a few lines of code. First, we create a differentiable approximation of label accuracy and show that axis-aligning the bounding box around an ellipse is optimal. We then introduce Rotation Uncertainty (RU) Loss, allowing the model to adapt to the uncertainty of the labels. On five different datasets (including COCO, PascalVOC, and Transparent Object Bin Picking), this approach improves the rotational invariance of both one-stage and two-stage architectures when measured with AP, AP50, and AP75. The code is available at https://github.com/akasha-imaging/ICCV2021.
MatrixNets: A New Scale and Aspect Ratio Aware Architecture for Object Detection
Jan 09, 2020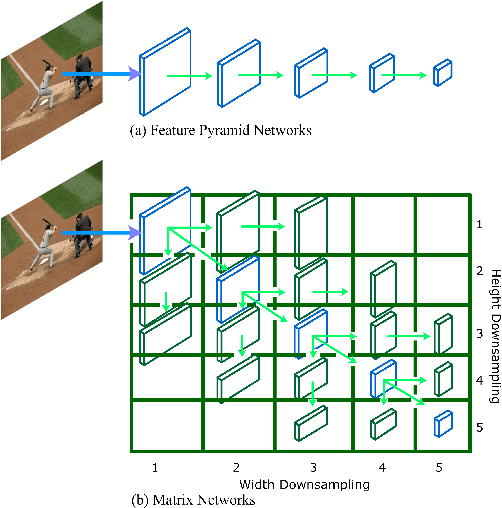
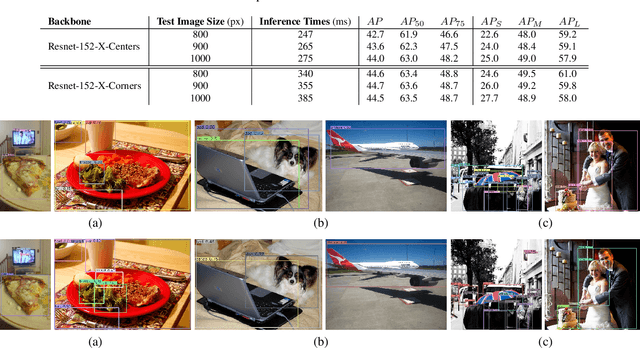
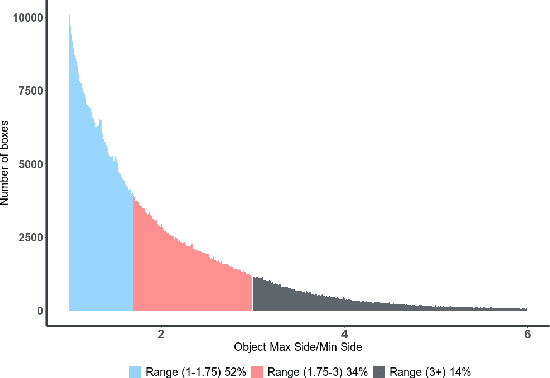
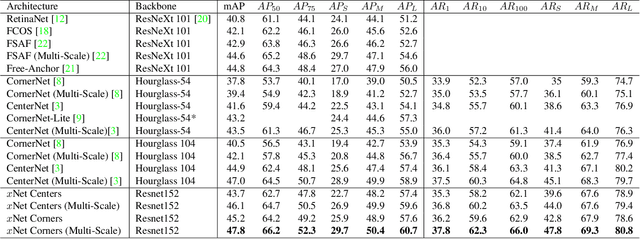
We present MatrixNets (xNets), a new deep architecture for object detection. xNets map objects with similar sizes and aspect ratios into many specialized layers, allowing xNets to provide a scale and aspect ratio aware architecture. We leverage xNets to enhance single-stage object detection frameworks. First, we apply xNets on anchor-based object detection, for which we predict object centers and regress the top-left and bottom-right corners. Second, we use MatrixNets for corner-based object detection by predicting top-left and bottom-right corners. Each corner predicts the center location of the object. We also enhance corner-based detection by replacing the embedding layer with center regression. Our final architecture achieves mAP of 47.8 on MS COCO, which is higher than its CornerNet counterpart by +5.6 mAP while also closing the gap between single-stage and two-stage detectors. The code is available at https://github.com/arashwan/matrixnet.