 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollision Avoidance Metric for 3D Camera Evaluation
May 16, 20243D cameras have emerged as a critical source of information for applications in robotics and autonomous driving. These cameras provide robots with the ability to capture and utilize point clouds, enabling them to navigate their surroundings and avoid collisions with other objects. However, current standard camera evaluation metrics often fail to consider the specific application context. These metrics typically focus on measures like Chamfer distance (CD) or Earth Mover's Distance (EMD), which may not directly translate to performance in real-world scenarios. To address this limitation, we propose a novel metric for point cloud evaluation, specifically designed to assess the suitability of 3D cameras for the critical task of collision avoidance. This metric incorporates application-specific considerations and provides a more accurate measure of a camera's effectiveness in ensuring safe robot navigation.
Towards Rotation Invariance in Object Detection
Oct 01, 2021
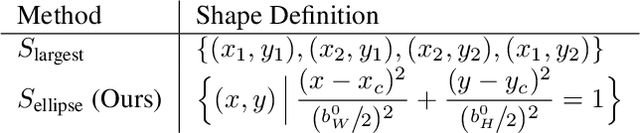
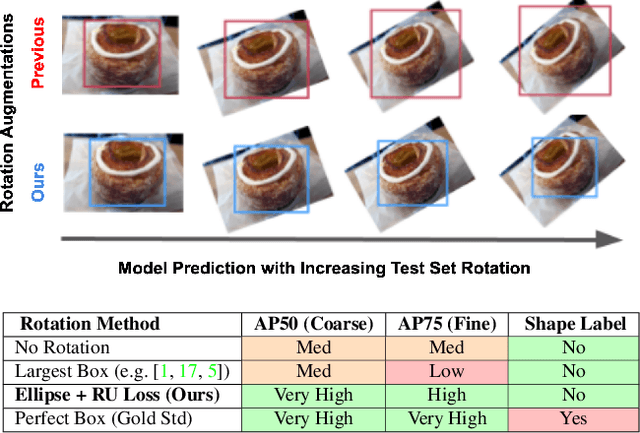
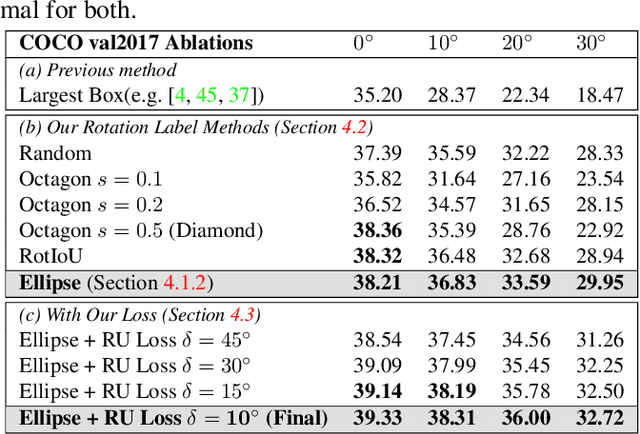
Rotation augmentations generally improve a model's invariance/equivariance to rotation - except in object detection. In object detection the shape is not known, therefore rotation creates a label ambiguity. We show that the de-facto method for bounding box label rotation, the Largest Box Method, creates very large labels, leading to poor performance and in many cases worse performance than using no rotation at all. We propose a new method of rotation augmentation that can be implemented in a few lines of code. First, we create a differentiable approximation of label accuracy and show that axis-aligning the bounding box around an ellipse is optimal. We then introduce Rotation Uncertainty (RU) Loss, allowing the model to adapt to the uncertainty of the labels. On five different datasets (including COCO, PascalVOC, and Transparent Object Bin Picking), this approach improves the rotational invariance of both one-stage and two-stage architectures when measured with AP, AP50, and AP75. The code is available at https://github.com/akasha-imaging/ICCV2021.
MatrixNets: A New Scale and Aspect Ratio Aware Architecture for Object Detection
Jan 09, 2020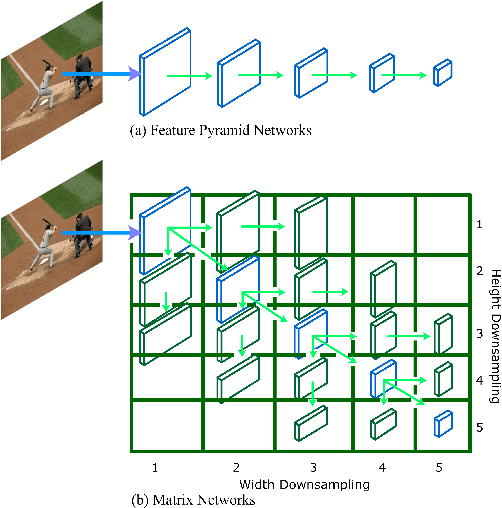
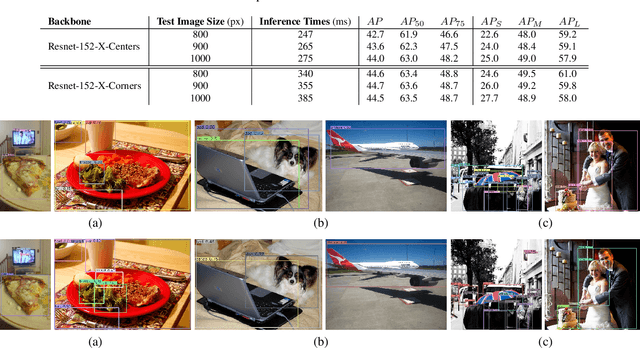
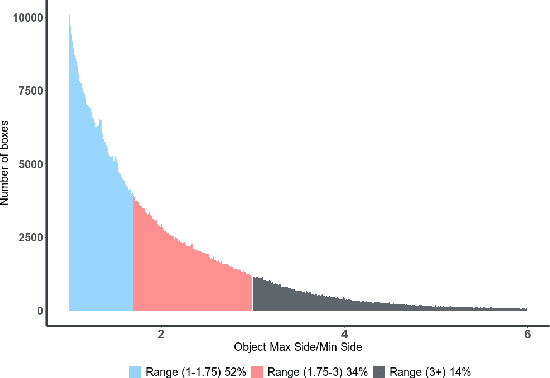
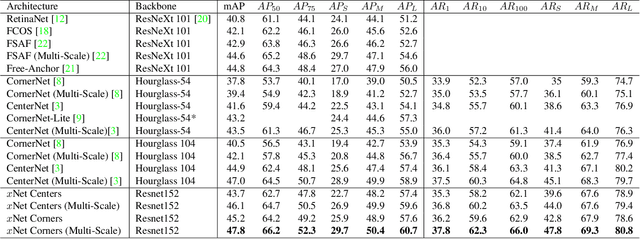
We present MatrixNets (xNets), a new deep architecture for object detection. xNets map objects with similar sizes and aspect ratios into many specialized layers, allowing xNets to provide a scale and aspect ratio aware architecture. We leverage xNets to enhance single-stage object detection frameworks. First, we apply xNets on anchor-based object detection, for which we predict object centers and regress the top-left and bottom-right corners. Second, we use MatrixNets for corner-based object detection by predicting top-left and bottom-right corners. Each corner predicts the center location of the object. We also enhance corner-based detection by replacing the embedding layer with center regression. Our final architecture achieves mAP of 47.8 on MS COCO, which is higher than its CornerNet counterpart by +5.6 mAP while also closing the gap between single-stage and two-stage detectors. The code is available at https://github.com/arashwan/matrixnet.
Matrix Nets: A New Deep Architecture for Object Detection
Aug 14, 2019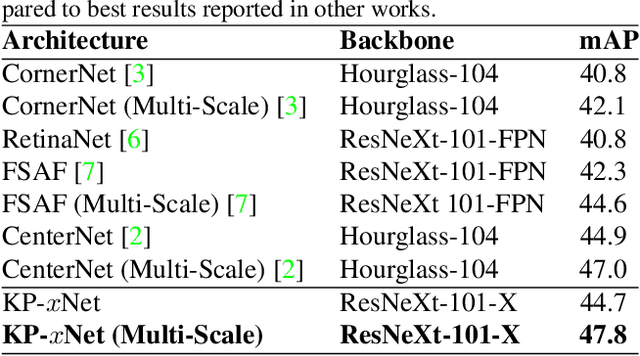
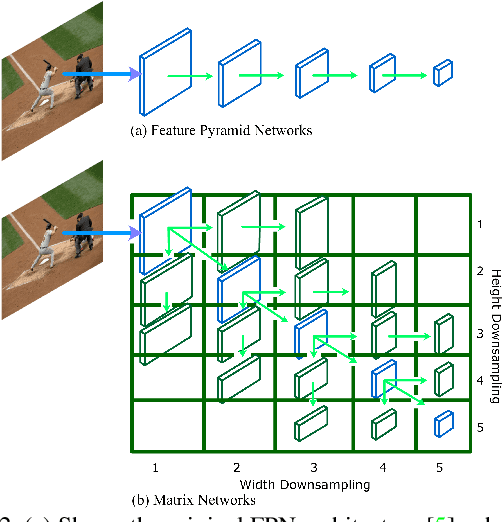
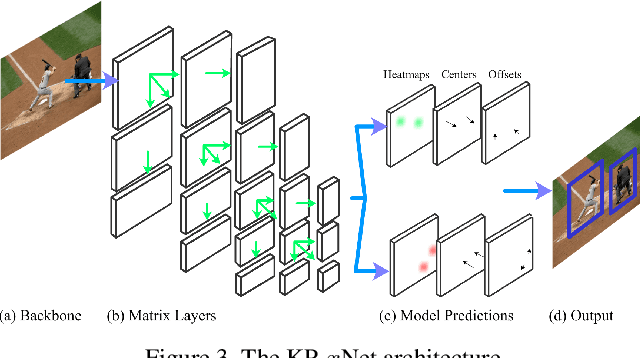
We present Matrix Nets (xNets), a new deep architecture for object detection. xNets map objects with different sizes and aspect ratios into layers where the sizes and the aspect ratios of the objects within their layers are nearly uniform. Hence, xNets provide a scale and aspect ratio aware architecture. We leverage xNets to enhance key-points based object detection. Our architecture achieves mAP of 47.8 on MS COCO, which is higher than any other single-shot detector while using half the number of parameters and training 3x faster than the next best architecture.
Photofeeler-D3: A Neural Network with Voter Modeling for Dating Photo Impression Prediction
May 10, 2019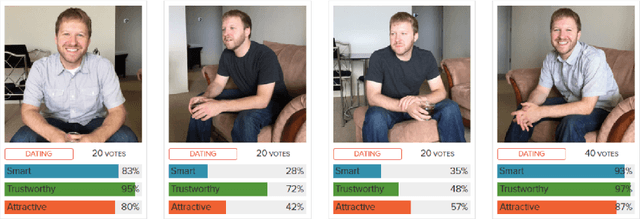

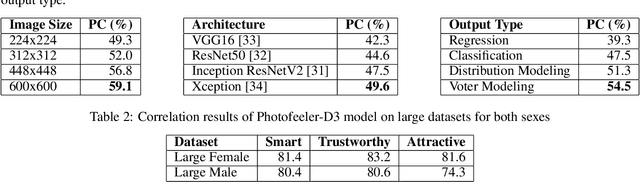

In just a few years, online dating has become the dominant way that young people meet to date, making the deceptively error-prone task of picking good dating profile photos vital to a generation's ability to form romantic connections. Until now, artificial intelligence approaches to Dating Photo Impression Prediction (DPIP) have been very inaccurate, unadaptable to real-world application, and have only taken into account a subject's physical attractiveness. To that effect, we propose Photofeeler-D3 - the first convolutional neural network as accurate as 10 human votes for how smart, trustworthy, and attractive the subject appears in highly variable dating photos. Our "attractive" output is also applicable to Facial Beauty Prediction (FBP), making Photofeeler-D3 state-of-the-art for both DPIP and FBP. We achieve this by leveraging Photofeeler's Dating Dataset (PDD) with over 1 million images and tens of millions of votes, our novel technique of voter modeling, and cutting-edge computer vision techniques.
Online Structure Learning for Sum-Product Networks with Gaussian Leaves
Jan 19, 2017


Sum-product networks have recently emerged as an attractive representation due to their dual view as a special type of deep neural network with clear semantics and a special type of probabilistic graphical model for which inference is always tractable. Those properties follow from some conditions (i.e., completeness and decomposability) that must be respected by the structure of the network. As a result, it is not easy to specify a valid sum-product network by hand and therefore structure learning techniques are typically used in practice. This paper describes the first online structure learning technique for continuous SPNs with Gaussian leaves. We also introduce an accompanying new parameter learning technique.