 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the temporal understanding of neural networks on event-based action recognition with DVS-Gesture-Chain
Sep 29, 2022

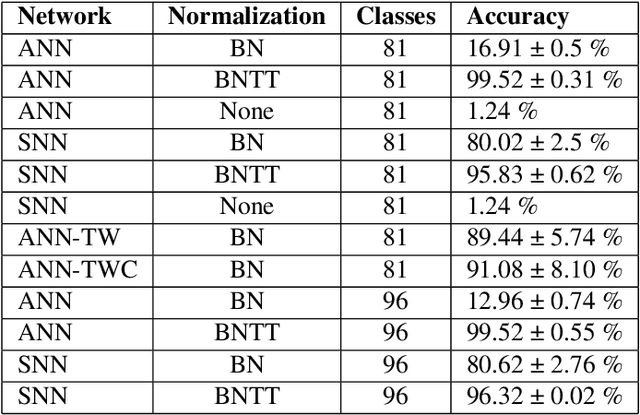

Enabling artificial neural networks (ANNs) to have temporal understanding in visual tasks is an essential requirement in order to achieve complete perception of video sequences. A wide range of benchmark datasets is available to allow for the evaluation of such capabilities when using conventional frame-based video sequences. In contrast, evaluating them for systems targeting neuromorphic data is still a challenge due to the lack of appropriate datasets. In this work we define a new benchmark task for action recognition in event-based video sequences, DVS-Gesture-Chain (DVS-GC), which is based on the temporal combination of multiple gestures from the widely used DVS-Gesture dataset. This methodology allows to create datasets that are arbitrarily complex in the temporal dimension. Using our newly defined task, we evaluate the spatio-temporal understanding of different feed-forward convolutional ANNs and convolutional Spiking Neural Networks (SNNs). Our study proves how the original DVS Gesture benchmark could be solved by networks without temporal understanding, unlike the new DVS-GC which demands an understanding of the ordering of events. From there, we provide a study showing how certain elements such as spiking neurons or time-dependent weights allow for temporal understanding in feed-forward networks without the need for recurrent connections. Code available at: https://github.com/VicenteAlex/DVS-Gesture-Chain
Unsupervised Spiking Instance Segmentation on Event Data using STDP
Nov 12, 2021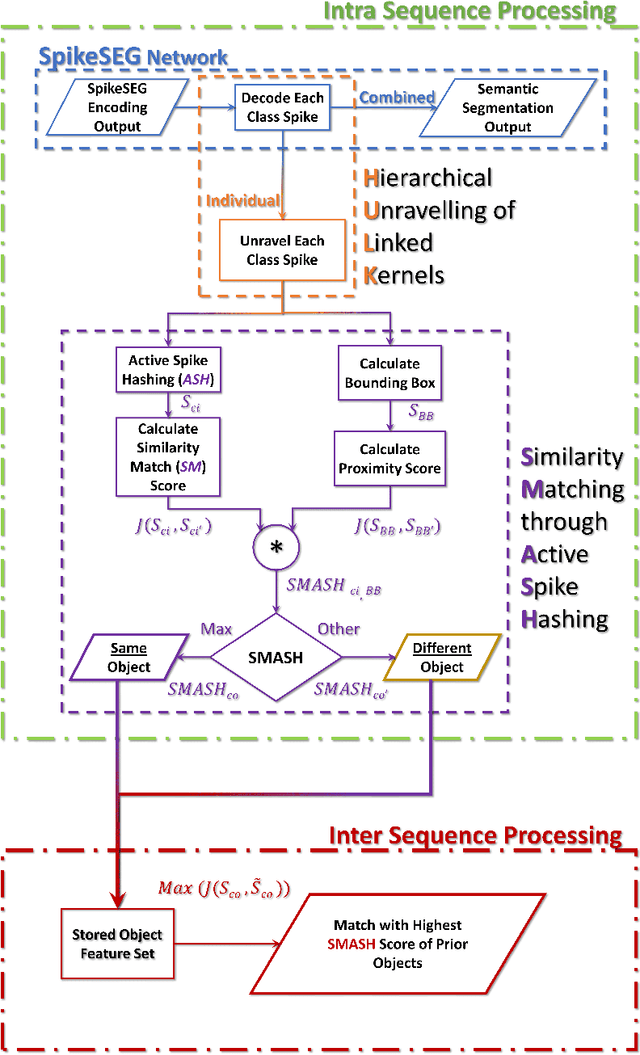
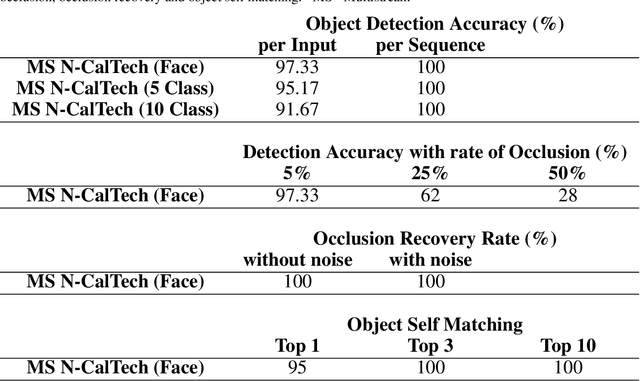
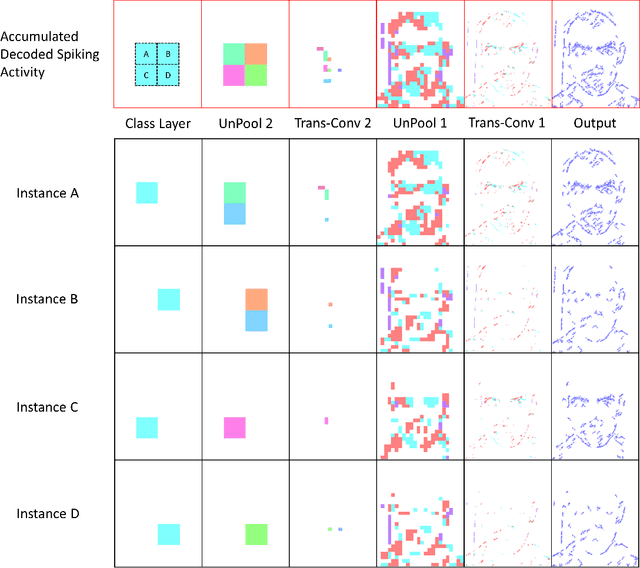
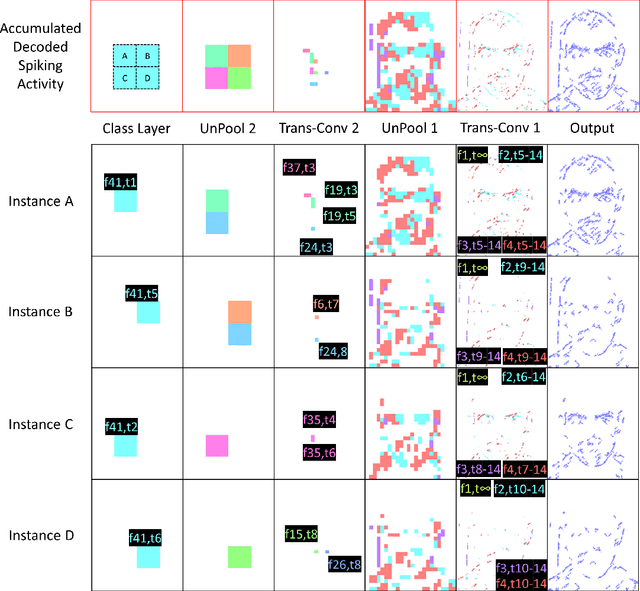
Spiking Neural Networks (SNN) and the field of Neuromorphic Engineering has brought about a paradigm shift in how to approach Machine Learning (ML) and Computer Vision (CV) problem. This paradigm shift comes from the adaption of event-based sensing and processing. An event-based vision sensor allows for sparse and asynchronous events to be produced that are dynamically related to the scene. Allowing not only the spatial information but a high-fidelity of temporal information to be captured. Meanwhile avoiding the extra overhead and redundancy of conventional high frame rate approaches. However, with this change in paradigm, many techniques from traditional CV and ML are not applicable to these event-based spatial-temporal visual streams. As such a limited number of recognition, detection and segmentation approaches exist. In this paper, we present a novel approach that can perform instance segmentation using just the weights of a Spike Time Dependent Plasticity trained Spiking Convolutional Neural Network that was trained for object recognition. This exploits the spatial and temporal aspects of the network's internal feature representations adding this new discriminative capability. We highlight the new capability by successfully transforming a single class unsupervised network for face detection into a multi-person face recognition and instance segmentation network.
Keys to Accurate Feature Extraction Using Residual Spiking Neural Networks
Nov 12, 2021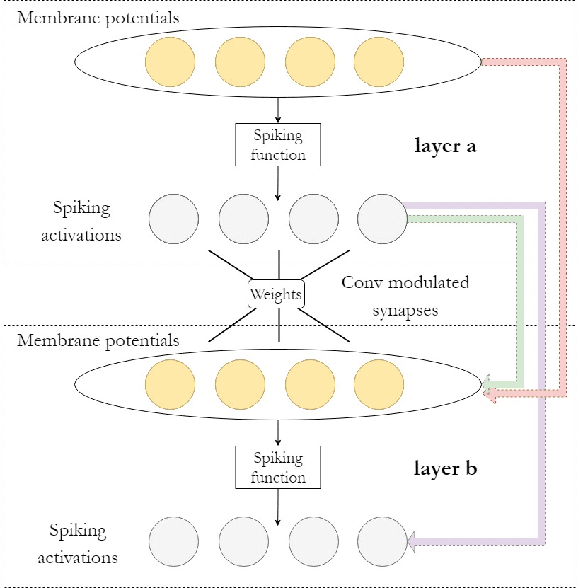
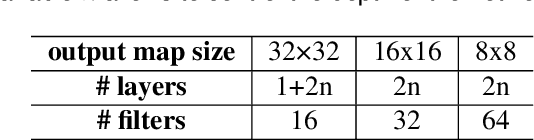
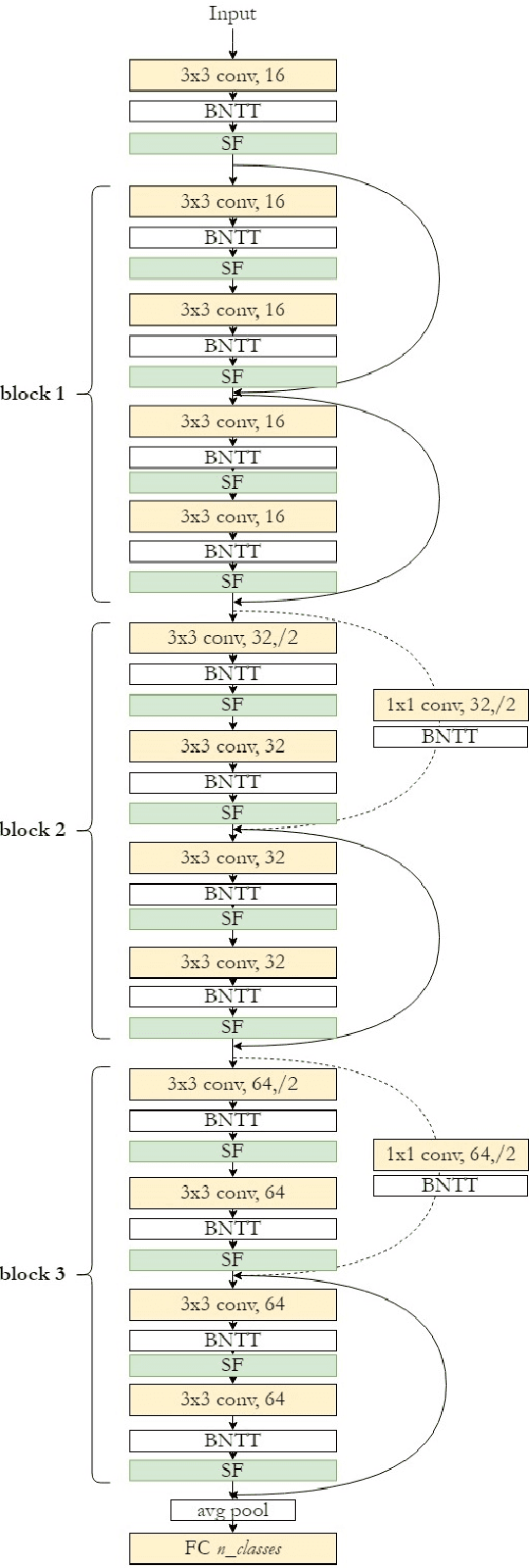

Spiking neural networks (SNNs) have become an interesting alternative to conventional artificial neural networks (ANN) thanks to their temporal processing capabilities and their low-SWaP (Size, Weight, and Power) and energy efficient implementations in neuromorphic hardware. However the challenges involved in training SNNs have limited their performance in terms of accuracy and thus their applications. Improving learning algorithms and neural architectures for a more accurate feature extraction is therefore one of the current priorities in SNN research. In this paper we present a study on the key components of modern spiking architectures. We empirically compare different techniques in image classification datasets taken from the best performing networks. We design a spiking version of the successful residual network (ResNet) architecture and test different components and training strategies on it. Our results provide a state of the art guide to SNN design, which allows to make informed choices when trying to build the optimal visual feature extractor. Finally, our network outperforms previous SNN architectures in CIFAR-10 (94.1%) and CIFAR-100 (74.5%) datasets and matches the state of the art in DVS-CIFAR10 (71.3%), with less parameters than the previous state of the art and without the need for ANN-SNN conversion. Code available at https://github.com/VicenteAlex/Spiking_ResNet.