 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the temporal understanding of neural networks on event-based action recognition with DVS-Gesture-Chain
Paper and Code


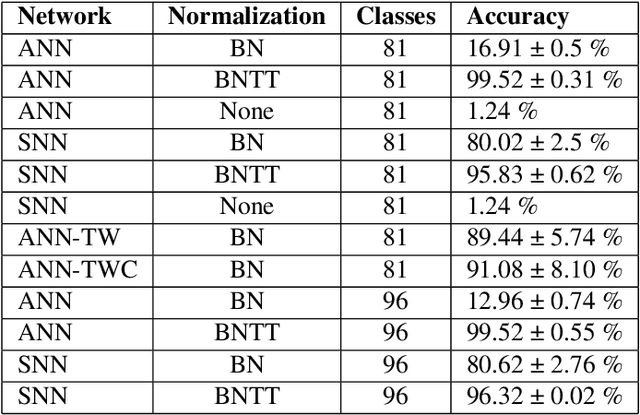

Enabling artificial neural networks (ANNs) to have temporal understanding in visual tasks is an essential requirement in order to achieve complete perception of video sequences. A wide range of benchmark datasets is available to allow for the evaluation of such capabilities when using conventional frame-based video sequences. In contrast, evaluating them for systems targeting neuromorphic data is still a challenge due to the lack of appropriate datasets. In this work we define a new benchmark task for action recognition in event-based video sequences, DVS-Gesture-Chain (DVS-GC), which is based on the temporal combination of multiple gestures from the widely used DVS-Gesture dataset. This methodology allows to create datasets that are arbitrarily complex in the temporal dimension. Using our newly defined task, we evaluate the spatio-temporal understanding of different feed-forward convolutional ANNs and convolutional Spiking Neural Networks (SNNs). Our study proves how the original DVS Gesture benchmark could be solved by networks without temporal understanding, unlike the new DVS-GC which demands an understanding of the ordering of events. From there, we provide a study showing how certain elements such as spiking neurons or time-dependent weights allow for temporal understanding in feed-forward networks without the need for recurrent connections. Code available at: https://github.com/VicenteAlex/DVS-Gesture-Chain