 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental Survey on Neuromorphic Based Audio Classification
Feb 20, 2025Audio classification is paramount in a variety of applications including surveillance, healthcare monitoring, and environmental analysis. Traditional methods frequently depend on intricate signal processing algorithms and manually crafted features, which may fall short in fully capturing the complexities of audio patterns. Neuromorphic computing, inspired by the architecture and functioning of the human brain, presents a promising alternative for audio classification tasks. This survey provides an exhaustive examination of the current state-of-the-art in neuromorphic-based audio classification. It delves into the crucial components of neuromorphic systems, such as Spiking Neural Networks (SNNs), memristors, and neuromorphic hardware platforms, highlighting their advantages in audio classification. Furthermore, the survey explores various methodologies and strategies employed in neuromorphic audio classification, including event-based processing, spike-based learning, and bio-inspired feature extraction. It examines how these approaches address the limitations of traditional audio classification methods, particularly in terms of energy efficiency, real-time processing, and robustness to environmental noise. Additionally, the paper conducts a comparative analysis of different neuromorphic audio classification models and benchmarks, evaluating their performance metrics, computational efficiency, and scalability. By providing a comprehensive guide for researchers, engineers and practitioners, this survey aims to stimulate further innovation and advancements in the evolving field of neuromorphic audio classification.
Frameworks for SNNs: a Review of Data Science-oriented Software and an Expansion of SpykeTorch
Feb 15, 2023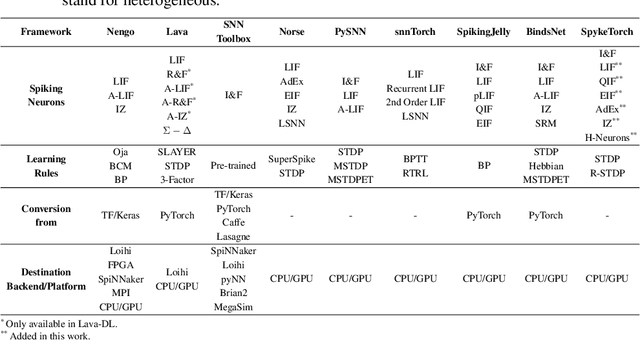
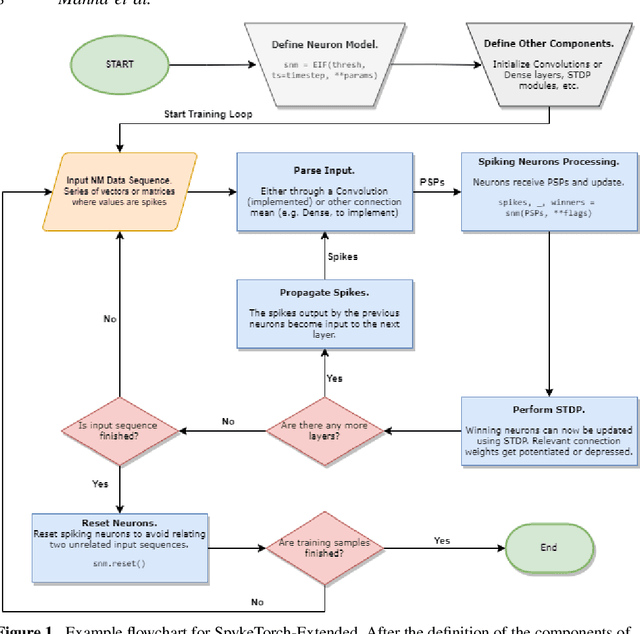
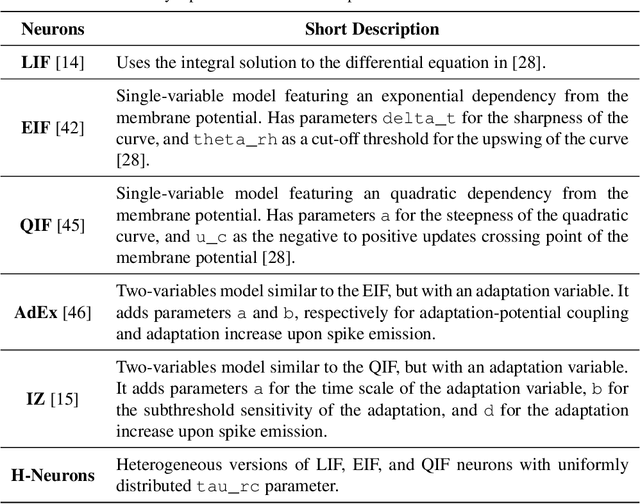
Developing effective learning systems for Machine Learning (ML) applications in the Neuromorphic (NM) field requires extensive experimentation and simulation. Software frameworks aid and ease this process by providing a set of ready-to-use tools that researchers can leverage. The recent interest in NM technology has seen the development of several new frameworks that do this, and that add up to the panorama of already existing libraries that belong to neuroscience fields. This work reviews 9 frameworks for the development of Spiking Neural Networks (SNNs) that are specifically oriented towards data science applications. We emphasize the availability of spiking neuron models and learning rules to more easily direct decisions on the most suitable frameworks to carry out different types of research. Furthermore, we present an extension to the SpykeTorch framework that gives users access to a much broader choice of neuron models to embed in SNNs and make the code publicly available.
Evaluating the temporal understanding of neural networks on event-based action recognition with DVS-Gesture-Chain
Sep 29, 2022

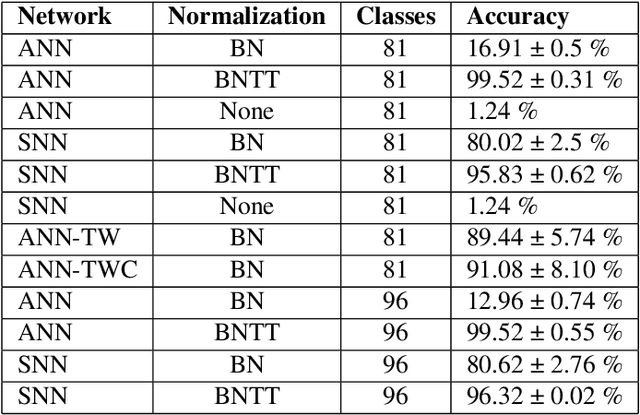

Enabling artificial neural networks (ANNs) to have temporal understanding in visual tasks is an essential requirement in order to achieve complete perception of video sequences. A wide range of benchmark datasets is available to allow for the evaluation of such capabilities when using conventional frame-based video sequences. In contrast, evaluating them for systems targeting neuromorphic data is still a challenge due to the lack of appropriate datasets. In this work we define a new benchmark task for action recognition in event-based video sequences, DVS-Gesture-Chain (DVS-GC), which is based on the temporal combination of multiple gestures from the widely used DVS-Gesture dataset. This methodology allows to create datasets that are arbitrarily complex in the temporal dimension. Using our newly defined task, we evaluate the spatio-temporal understanding of different feed-forward convolutional ANNs and convolutional Spiking Neural Networks (SNNs). Our study proves how the original DVS Gesture benchmark could be solved by networks without temporal understanding, unlike the new DVS-GC which demands an understanding of the ordering of events. From there, we provide a study showing how certain elements such as spiking neurons or time-dependent weights allow for temporal understanding in feed-forward networks without the need for recurrent connections. Code available at: https://github.com/VicenteAlex/DVS-Gesture-Chain
Unsupervised Spiking Instance Segmentation on Event Data using STDP
Nov 12, 2021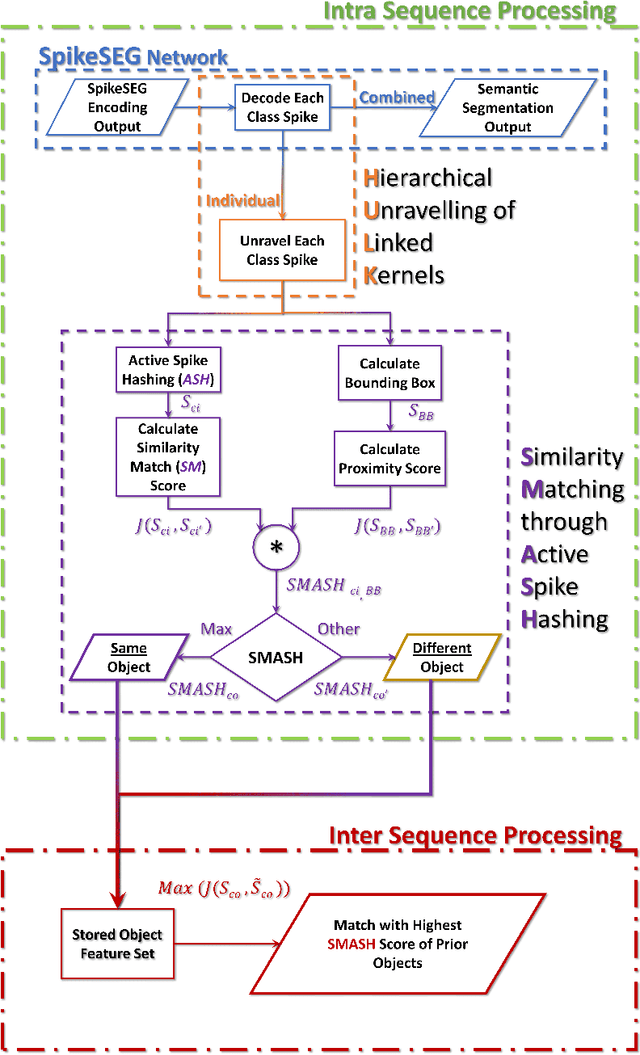
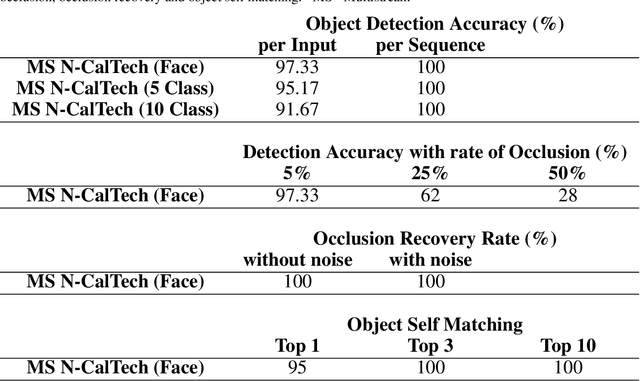
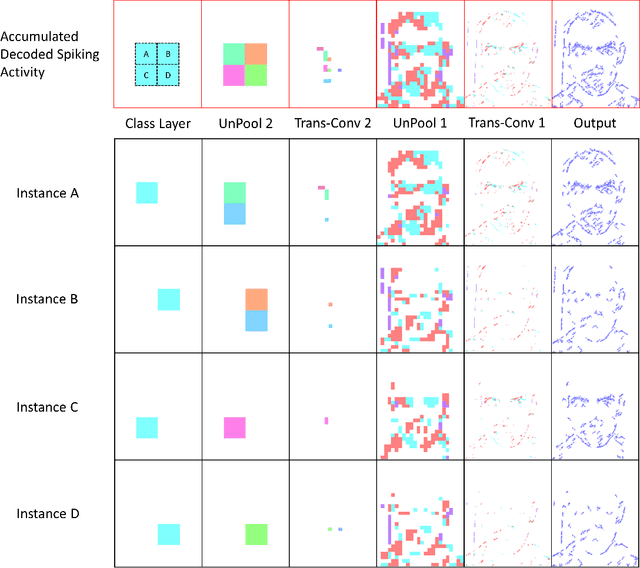
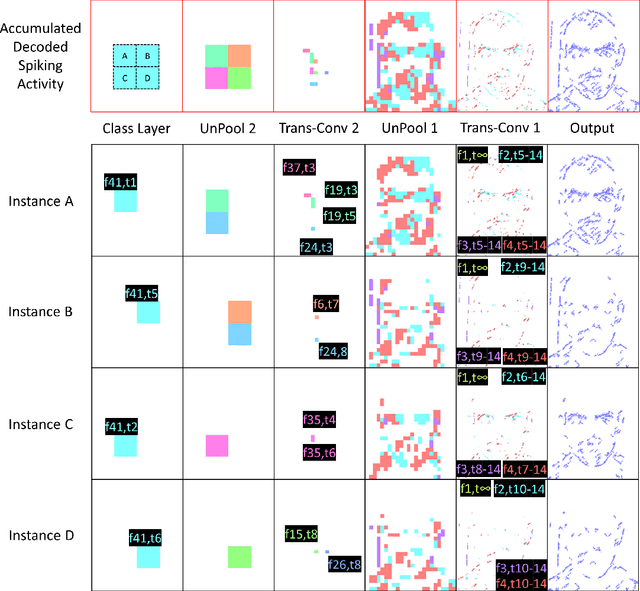
Spiking Neural Networks (SNN) and the field of Neuromorphic Engineering has brought about a paradigm shift in how to approach Machine Learning (ML) and Computer Vision (CV) problem. This paradigm shift comes from the adaption of event-based sensing and processing. An event-based vision sensor allows for sparse and asynchronous events to be produced that are dynamically related to the scene. Allowing not only the spatial information but a high-fidelity of temporal information to be captured. Meanwhile avoiding the extra overhead and redundancy of conventional high frame rate approaches. However, with this change in paradigm, many techniques from traditional CV and ML are not applicable to these event-based spatial-temporal visual streams. As such a limited number of recognition, detection and segmentation approaches exist. In this paper, we present a novel approach that can perform instance segmentation using just the weights of a Spike Time Dependent Plasticity trained Spiking Convolutional Neural Network that was trained for object recognition. This exploits the spatial and temporal aspects of the network's internal feature representations adding this new discriminative capability. We highlight the new capability by successfully transforming a single class unsupervised network for face detection into a multi-person face recognition and instance segmentation network.
Keys to Accurate Feature Extraction Using Residual Spiking Neural Networks
Nov 12, 2021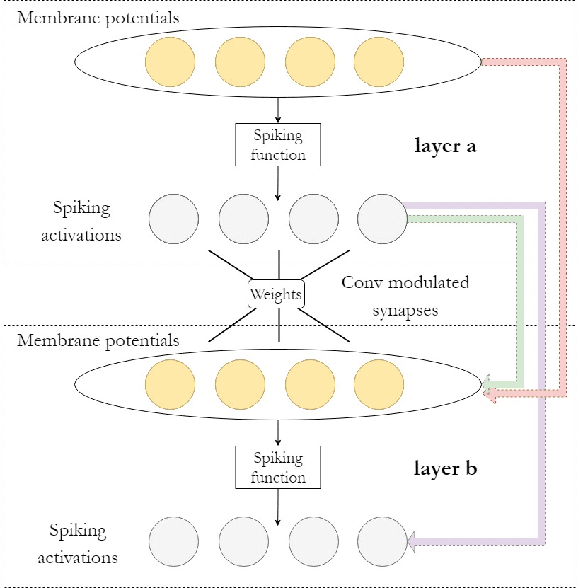
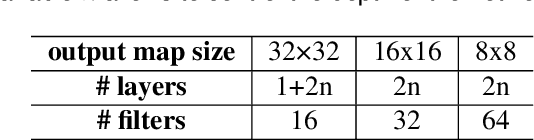
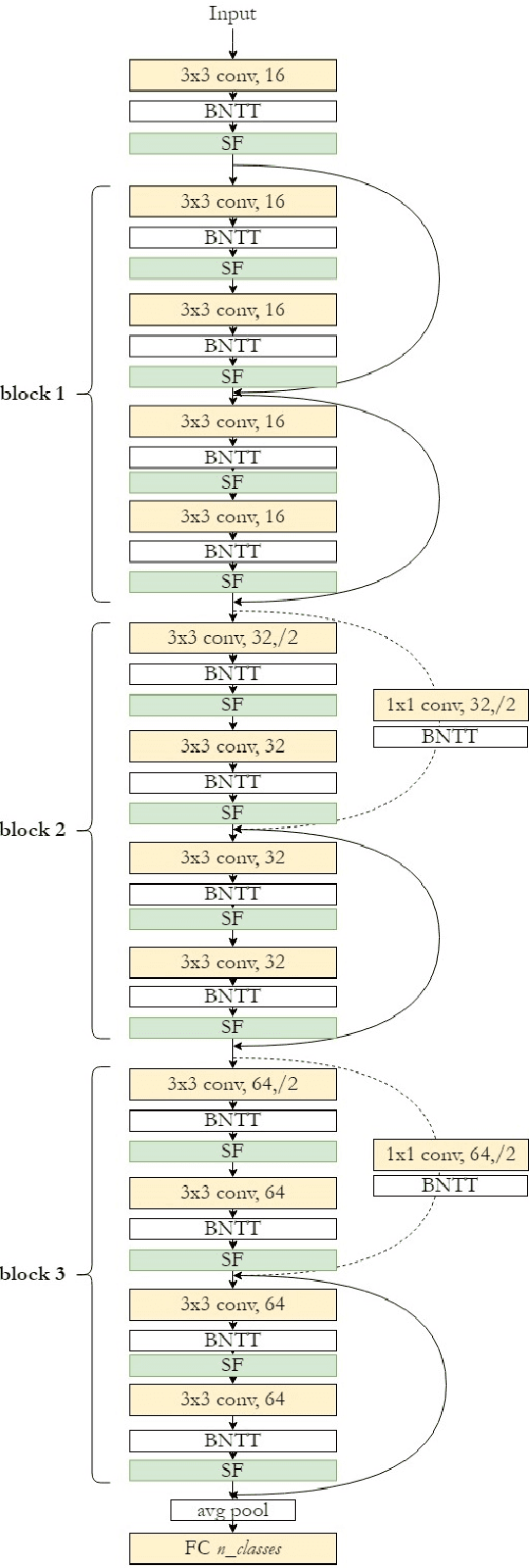

Spiking neural networks (SNNs) have become an interesting alternative to conventional artificial neural networks (ANN) thanks to their temporal processing capabilities and their low-SWaP (Size, Weight, and Power) and energy efficient implementations in neuromorphic hardware. However the challenges involved in training SNNs have limited their performance in terms of accuracy and thus their applications. Improving learning algorithms and neural architectures for a more accurate feature extraction is therefore one of the current priorities in SNN research. In this paper we present a study on the key components of modern spiking architectures. We empirically compare different techniques in image classification datasets taken from the best performing networks. We design a spiking version of the successful residual network (ResNet) architecture and test different components and training strategies on it. Our results provide a state of the art guide to SNN design, which allows to make informed choices when trying to build the optimal visual feature extractor. Finally, our network outperforms previous SNN architectures in CIFAR-10 (94.1%) and CIFAR-100 (74.5%) datasets and matches the state of the art in DVS-CIFAR10 (71.3%), with less parameters than the previous state of the art and without the need for ANN-SNN conversion. Code available at https://github.com/VicenteAlex/Spiking_ResNet.
Pseudo-label refinement using superpixels for semi-supervised brain tumour segmentation
Oct 16, 2021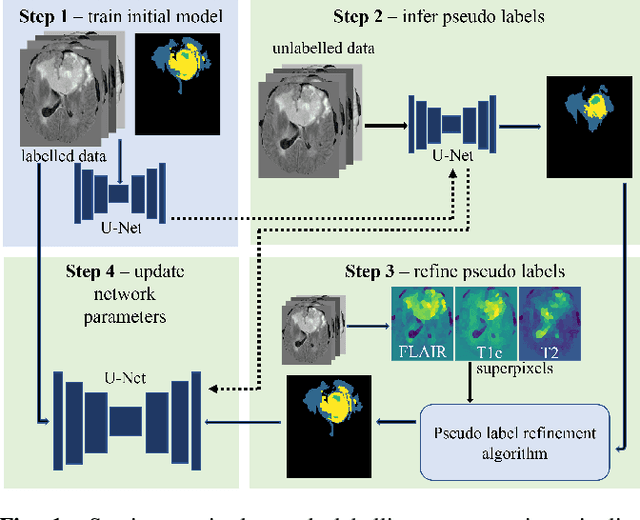
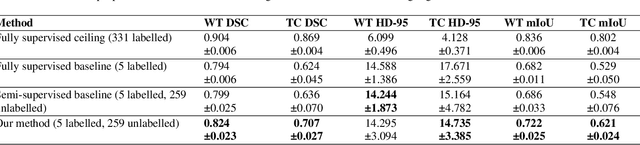
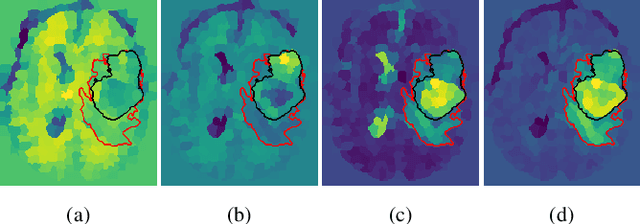
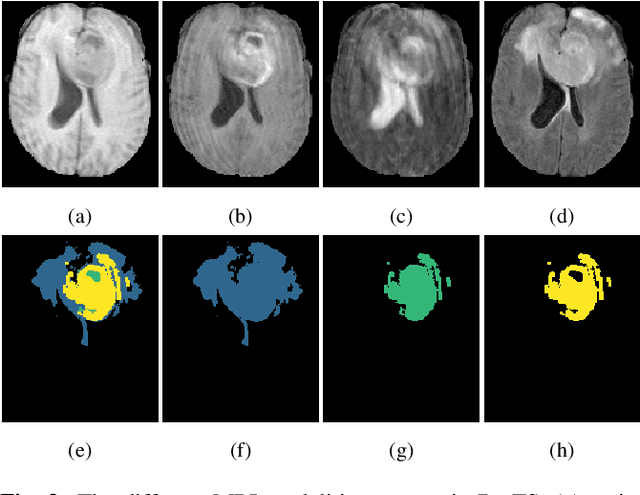
Training neural networks using limited annotations is an important problem in the medical domain. Deep Neural Networks (DNNs) typically require large, annotated datasets to achieve acceptable performance which, in the medical domain, are especially difficult to obtain as they require significant time from expert radiologists. Semi-supervised learning aims to overcome this problem by learning segmentations with very little annotated data, whilst exploiting large amounts of unlabelled data. However, the best-known technique, which utilises inferred pseudo-labels, is vulnerable to inaccurate pseudo-labels degrading the performance. We propose a framework based on superpixels - meaningful clusters of adjacent pixels - to improve the accuracy of the pseudo labels and address this issue. Our framework combines superpixels with semi-supervised learning, refining the pseudo-labels during training using the features and edges of the superpixel maps. This method is evaluated on a multimodal magnetic resonance imaging (MRI) dataset for the task of brain tumour region segmentation. Our method demonstrates improved performance over the standard semi-supervised pseudo-labelling baseline when there is a reduced annotator burden and only 5 annotated patients are available. We report DSC=0.824 and DSC=0.707 for the test set whole tumour and tumour core regions respectively.