 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetinaRegen: A Hybrid Model for Readability and Detail Restoration in Fundus Images
Feb 26, 2025



Fundus image quality is crucial for diagnosing eye diseases, but real-world conditions often result in blurred or unreadable images, increasing diagnostic uncertainty. To address these challenges, this study proposes RetinaRegen, a hybrid model for retinal image restoration that integrates a readability classifi-cation model, a Diffusion Model, and a Variational Autoencoder (VAE). Ex-periments on the SynFundus-1M dataset show that the proposed method achieves a PSNR of 27.4521, an SSIM of 0.9556, and an LPIPS of 0.1911 for the readability labels of the optic disc (RO) region. These results demonstrate superior performance in restoring key regions, offering an effective solution to enhance fundus image quality and support clinical diagnosis.
Joint ANN-SNN Co-training for Object Localization and Image Segmentation
Mar 10, 2023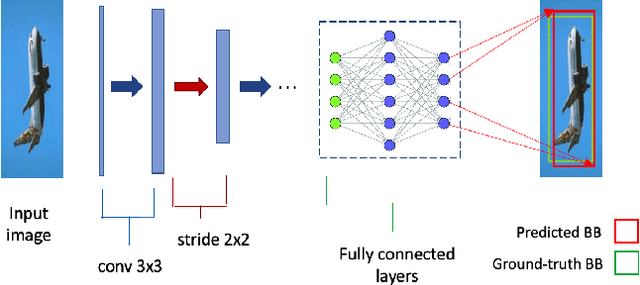
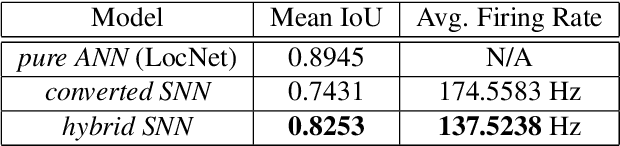
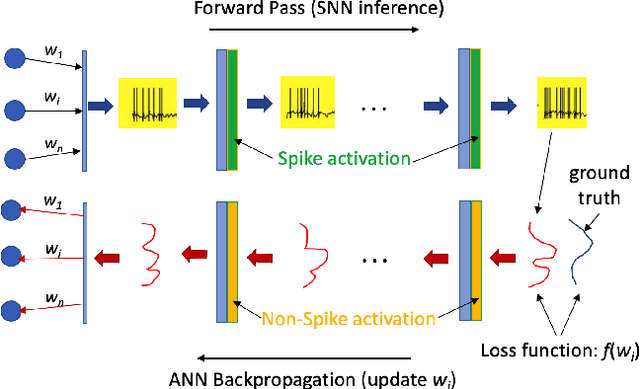
The field of machine learning has been greatly transformed with the advancement of deep artificial neural networks (ANNs) and the increased availability of annotated data. Spiking neural networks (SNNs) have recently emerged as a low-power alternative to ANNs due to their sparsity nature. In this work, we propose a novel hybrid ANN-SNN co-training framework to improve the performance of converted SNNs. Our approach is a fine-tuning scheme, conducted through an alternating, forward-backward training procedure. We apply our framework to object detection and image segmentation tasks. Experiments demonstrate the effectiveness of our approach in achieving the design goals.
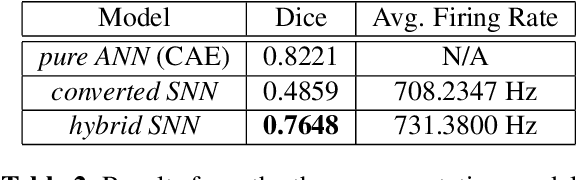
Hybrid Spiking Neural Network Fine-tuning for Hippocampus Segmentation
Feb 14, 2023



Over the past decade, artificial neural networks (ANNs) have made tremendous advances, in part due to the increased availability of annotated data. However, ANNs typically require significant power and memory consumptions to reach their full potential. Spiking neural networks (SNNs) have recently emerged as a low-power alternative to ANNs due to their sparsity nature. SNN, however, are not as easy to train as ANNs. In this work, we propose a hybrid SNN training scheme and apply it to segment human hippocampi from magnetic resonance images. Our approach takes ANN-SNN conversion as an initialization step and relies on spike-based backpropagation to fine-tune the network. Compared with the conversion and direct training solutions, our method has advantages in both segmentation accuracy and training efficiency. Experiments demonstrate the effectiveness of our model in achieving the design goals.
Smooth Trajectory Collision Avoidance through Deep Reinforcement Learning
Oct 12, 2022
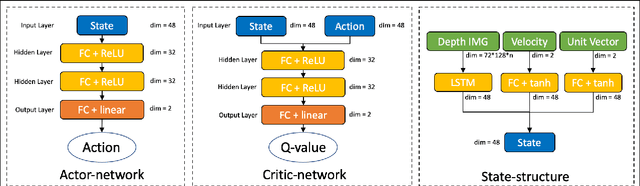
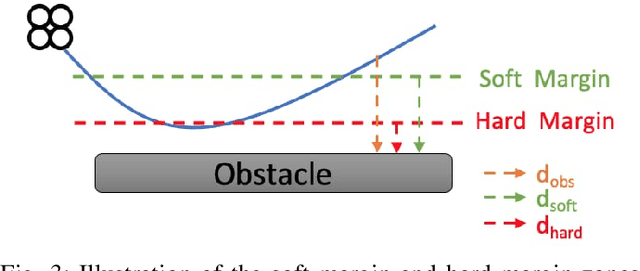
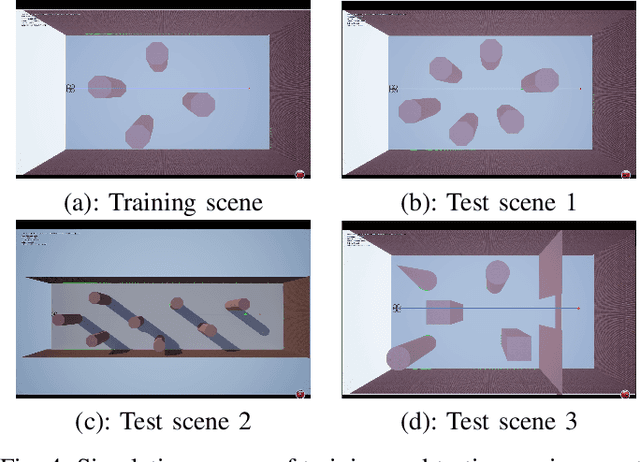
Collision avoidance is a crucial task in vision-guided autonomous navigation. Solutions based on deep reinforcement learning (DRL) has become increasingly popular. In this work, we proposed several novel agent state and reward function designs to tackle two critical issues in DRL-based navigation solutions: 1) smoothness of the trained flight trajectories; and 2) model generalization to handle unseen environments. Formulated under a DRL framework, our model relies on margin reward and smoothness constraints to ensure UAVs fly smoothly while greatly reducing the chance of collision. The proposed smoothness reward minimizes a combination of first-order and second-order derivatives of flight trajectories, which can also drive the points to be evenly distributed, leading to stable flight speed. To enhance the agent's capability of handling new unseen environments, two practical setups are proposed to improve the invariance of both the state and reward function when deploying in different scenes. Experiments demonstrate the effectiveness of our overall design and individual components.