 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVertex-based Networks to Accelerate Path Planning Algorithms
Jul 13, 2023Path planning plays a crucial role in various autonomy applications, and RRT* is one of the leading solutions in this field. In this paper, we propose the utilization of vertex-based networks to enhance the sampling process of RRT*, leading to more efficient path planning. Our approach focuses on critical vertices along the optimal paths, which provide essential yet sparser abstractions of the paths. We employ focal loss to address the associated data imbalance issue, and explore different masking configurations to determine practical tradeoffs in system performance. Through experiments conducted on randomly generated floor maps, our solutions demonstrate significant speed improvements, achieving over a 400% enhancement compared to the baseline model.
Joint ANN-SNN Co-training for Object Localization and Image Segmentation
Mar 10, 2023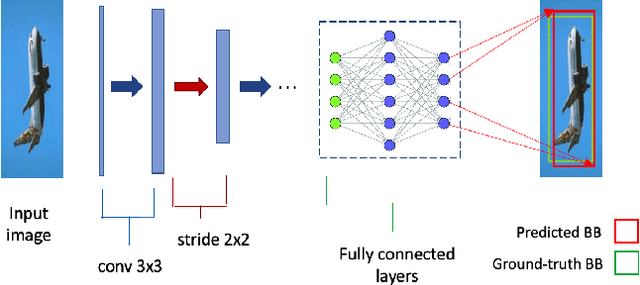
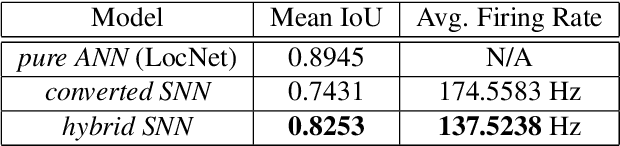
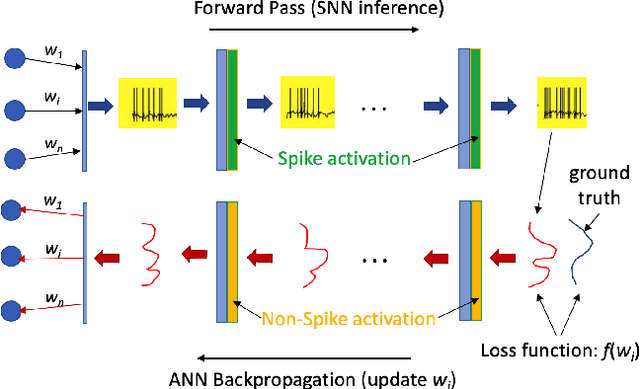
The field of machine learning has been greatly transformed with the advancement of deep artificial neural networks (ANNs) and the increased availability of annotated data. Spiking neural networks (SNNs) have recently emerged as a low-power alternative to ANNs due to their sparsity nature. In this work, we propose a novel hybrid ANN-SNN co-training framework to improve the performance of converted SNNs. Our approach is a fine-tuning scheme, conducted through an alternating, forward-backward training procedure. We apply our framework to object detection and image segmentation tasks. Experiments demonstrate the effectiveness of our approach in achieving the design goals.
Hybrid Spiking Neural Network Fine-tuning for Hippocampus Segmentation
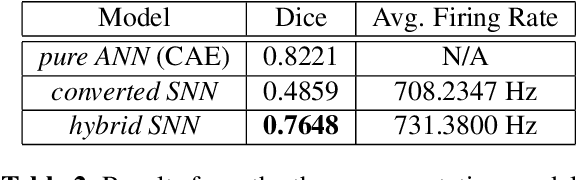
Feb 14, 2023



Over the past decade, artificial neural networks (ANNs) have made tremendous advances, in part due to the increased availability of annotated data. However, ANNs typically require significant power and memory consumptions to reach their full potential. Spiking neural networks (SNNs) have recently emerged as a low-power alternative to ANNs due to their sparsity nature. SNN, however, are not as easy to train as ANNs. In this work, we propose a hybrid SNN training scheme and apply it to segment human hippocampi from magnetic resonance images. Our approach takes ANN-SNN conversion as an initialization step and relies on spike-based backpropagation to fine-tune the network. Compared with the conversion and direct training solutions, our method has advantages in both segmentation accuracy and training efficiency. Experiments demonstrate the effectiveness of our model in achieving the design goals.
Individualized Conditioning and Negative Distances for Speaker Separation
Oct 12, 2022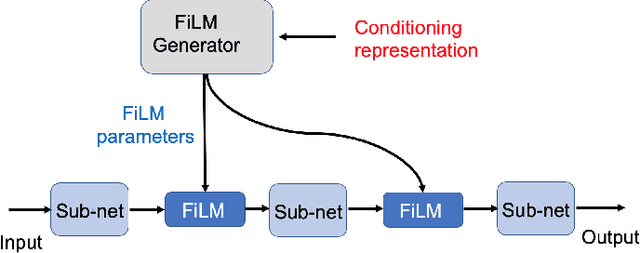


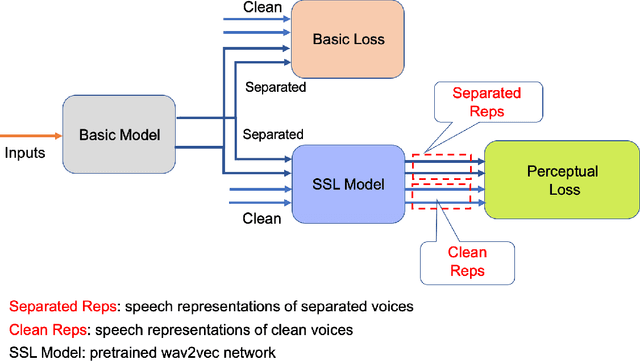
Speaker separation aims to extract multiple voices from a mixed signal. In this paper, we propose two speaker-aware designs to improve the existing speaker separation solutions. The first model is a speaker conditioning network that integrates speech samples to generate individualized speaker conditions, which then provide informed guidance for a separation module to produce well-separated outputs. The second design aims to reduce non-target voices in the separated speech. To this end, we propose negative distances to penalize the appearance of any non-target voice in the channel outputs, and positive distances to drive the separated voices closer to the clean targets. We explore two different setups, weighted-sum and triplet-like, to integrate these two distances to form a combined auxiliary loss for the separation networks. Experiments conducted on LibriMix demonstrate the effectiveness of our proposed models.
A Comparative Study on 1.5T-3T MRI Conversion through Deep Neural Network Models
Oct 12, 2022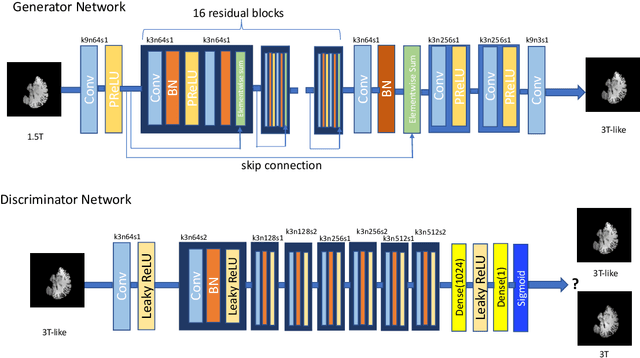
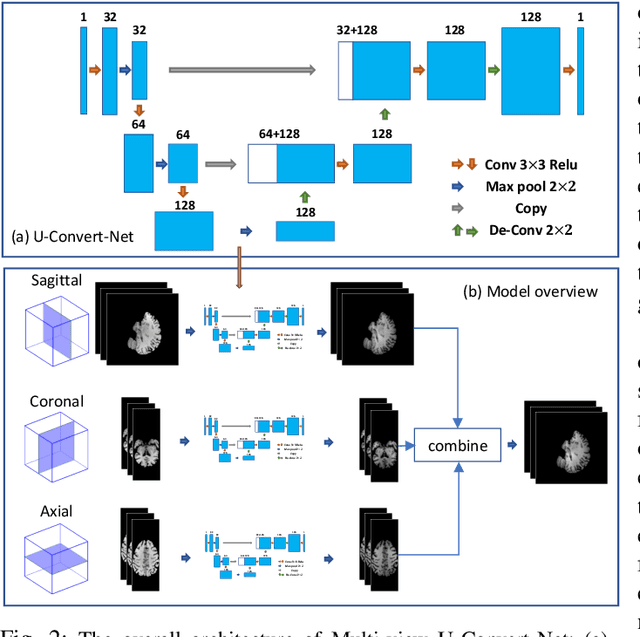
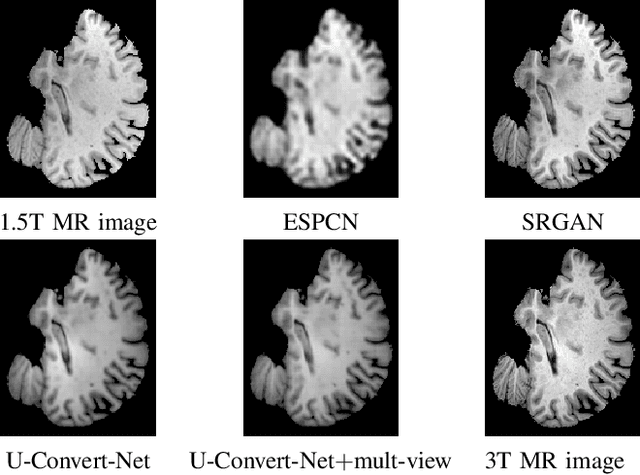
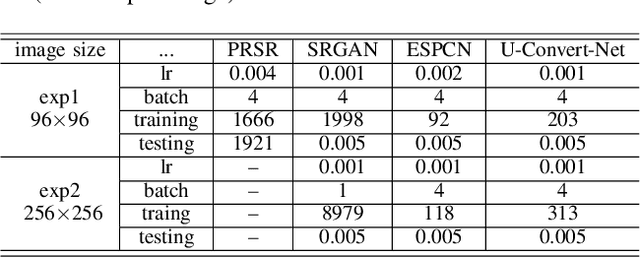
In this paper, we explore the capabilities of a number of deep neural network models in generating whole-brain 3T-like MR images from clinical 1.5T MRIs. The models include a fully convolutional network (FCN) method and three state-of-the-art super-resolution solutions, ESPCN [26], SRGAN [17] and PRSR [7]. The FCN solution, U-Convert-Net, carries out mapping of 1.5T-to-3T slices through a U-Net-like architecture, with 3D neighborhood information integrated through a multi-view ensemble. The pros and cons of the models, as well the associated evaluation metrics, are measured with experiments and discussed in depth. To the best of our knowledge, this study is the first work to evaluate multiple deep learning solutions for whole-brain MRI conversion, as well as the first attempt to utilize FCN/U-Net-like structure for this purpose.
Smooth Trajectory Collision Avoidance through Deep Reinforcement Learning
Oct 12, 2022
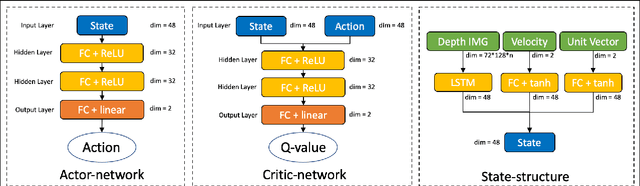
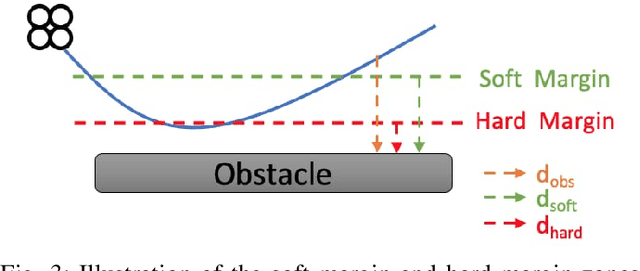
Collision avoidance is a crucial task in vision-guided autonomous navigation. Solutions based on deep reinforcement learning (DRL) has become increasingly popular. In this work, we proposed several novel agent state and reward function designs to tackle two critical issues in DRL-based navigation solutions: 1) smoothness of the trained flight trajectories; and 2) model generalization to handle unseen environments. Formulated under a DRL framework, our model relies on margin reward and smoothness constraints to ensure UAVs fly smoothly while greatly reducing the chance of collision. The proposed smoothness reward minimizes a combination of first-order and second-order derivatives of flight trajectories, which can also drive the points to be evenly distributed, leading to stable flight speed. To enhance the agent's capability of handling new unseen environments, two practical setups are proposed to improve the invariance of both the state and reward function when deploying in different scenes. Experiments demonstrate the effectiveness of our overall design and individual components.
Identifying Autism Spectrum Disorder Based on Individual-Aware Down-Sampling and Multi-Modal Learning
Sep 27, 2021
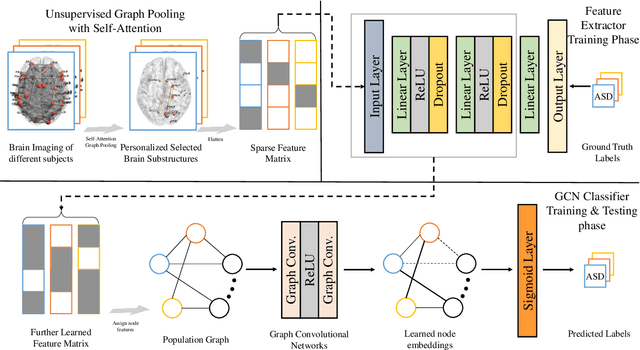
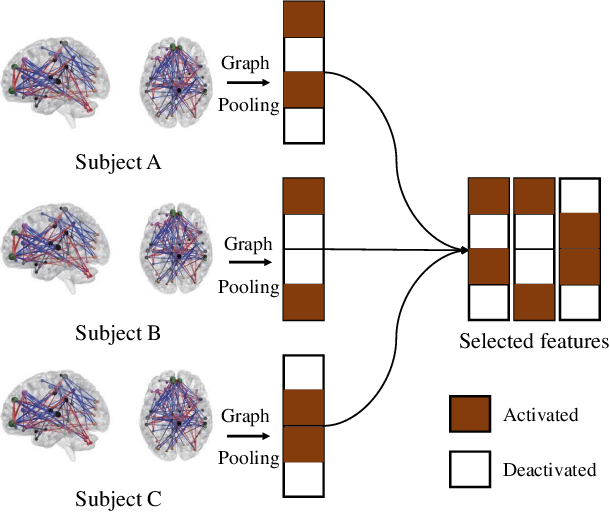
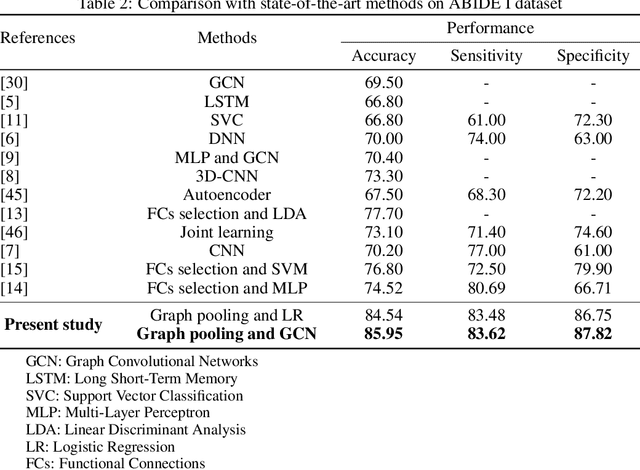
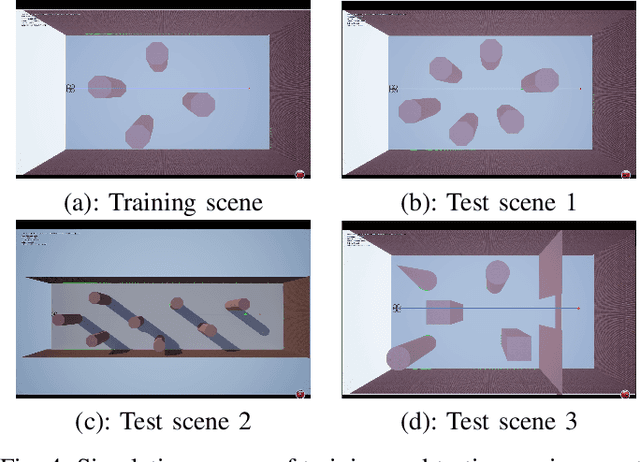
Autism Spectrum Disorder(ASD) is a set of neurodevelopmental conditions that affect patients' social abilities. In recent years, many studies have employed deep learning to diagnose this brain dysfunction through functional MRI (fMRI). However, existing approaches solely focused on the abnormal brain functional connections but ignored the impact of regional activities. Due to this biased prior knowledge, previous diagnosis models suffered from inter-site heterogeneity and inter-individual phenotypic differences. To address this issue, we propose a novel feature extraction method for fMRI that can learn a personalized lower-resolution representation of the entire brain networking regarding both the functional connections and regional activities. Specifically, we abstract the brain imaging as a graph structure and straightforwardly downsample it to sparse substructures by hierarchical graph pooling. The down-scaled feature vectors are embedded into a population graph where the hidden inter-subject heterogeneity and homogeneity are explicitly expressed as inter- and intra-community connectivity differences. Subsequently, we fuse the imaging and non-imaging information by graph convolutional networks (GCN), which recalibrates features to node embeddings under phenotypic statistics. By these means, our framework can extract features directly and efficiently from the entire fMRI and be aware of implicit inter-individual variance. We have evaluated our framework on the ABIDE-I dataset with 10-fold cross-validation. The present model has achieved a mean classification accuracy of 85.95\% and a mean AUC of 0.92, better than the state-of-the-art methods.
Residual Pyramid FCN for Robust Follicle Segmentation
Jan 11, 2019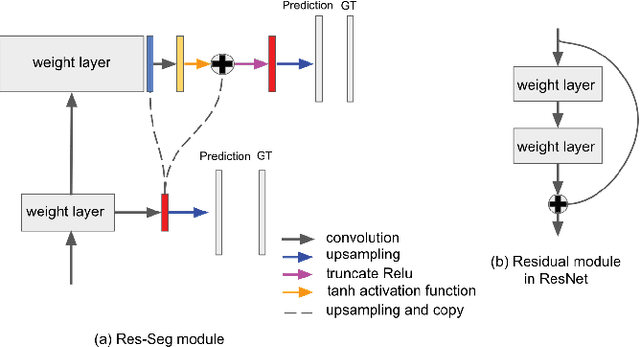
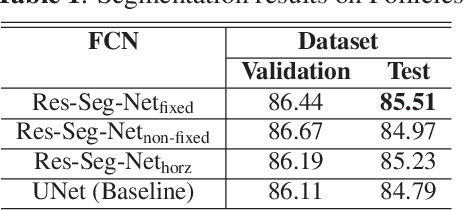
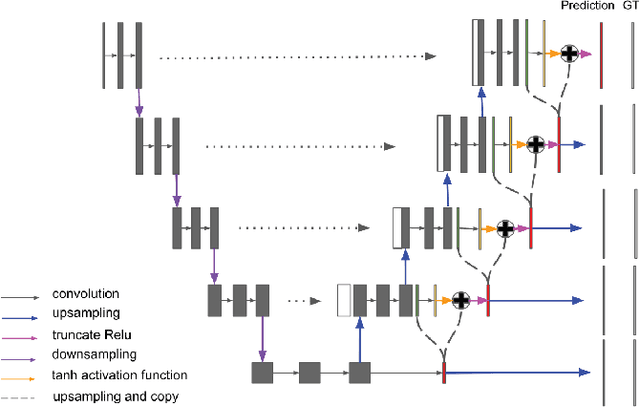
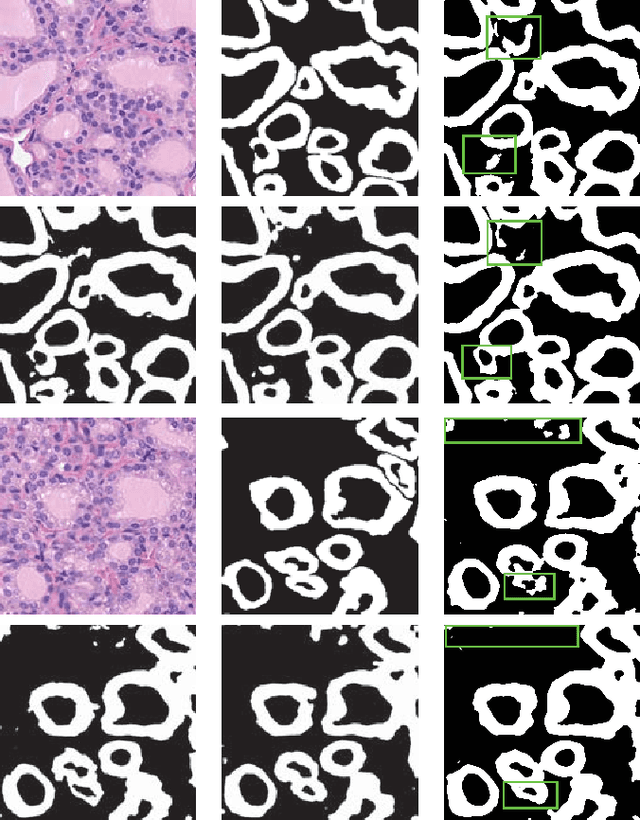
In this paper, we propose a pyramid network structure to improve the FCN-based segmentation solutions and apply it to label thyroid follicles in histology images. Our design is based on the notion that a hierarchical updating scheme, if properly implemented, can help FCNs capture the major objects, as well as structure details in an image. To this end, we devise a residual module to be mounted on consecutive network layers, through which pixel labels would be propagated from the coarsest layer towards the finest layer in a bottom-up fashion. We add five residual units along the decoding path of a modified U-Net to make our segmentation network, Res-Seg-Net. Experiments demonstrate that the multi-resolution set-up in our model is effective in producing segmentations with improved accuracy and robustness.
Trace-back Along Capsules and Its Application on Semantic Segmentation
Jan 09, 2019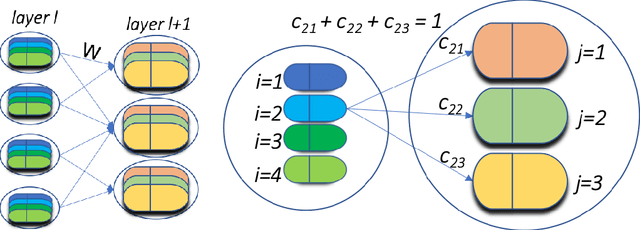
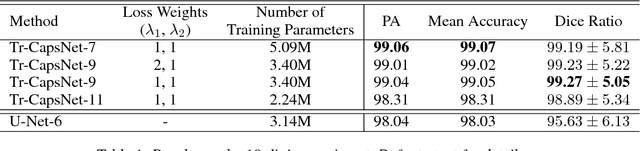
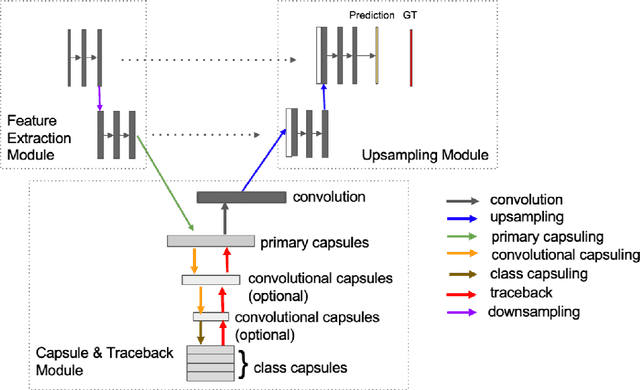

In this paper, we propose a capsule-based neural network model to solve the semantic segmentation problem. By taking advantage of the extractable part-whole dependencies available in capsule layers, we derive the probabilities of the class labels for individual capsules through a recursive, layer-by-layer procedure. We model this procedure as a traceback pipeline and take it as a central piece to build an end-to-end segmentation network. Under the proposed framework, image-level class labels and object boundaries are jointly sought in an explicit manner, which poses a significant advantage over the state-of-the-art fully convolutional network (FCN) solutions. Experiments conducted on modified MNIST and neuroimages demonstrate that our model considerably enhance the segmentation performance compared to the leading FCN variant.
Ensemble of Multi-sized FCNs to Improve White Matter Lesion Segmentation
Jul 24, 2018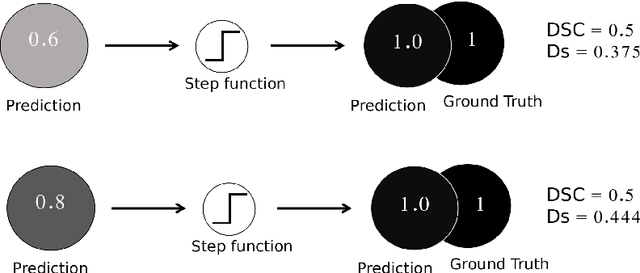
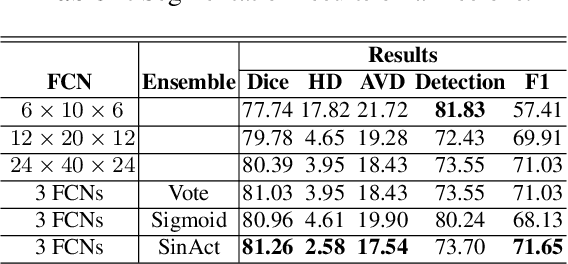
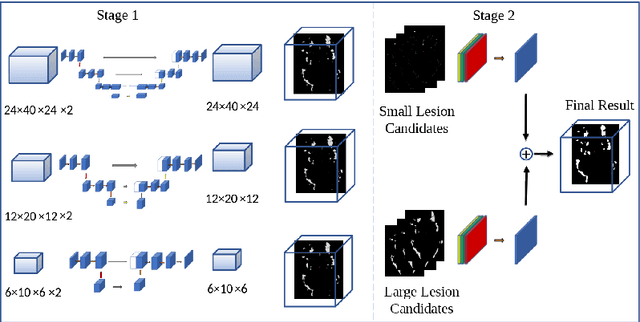
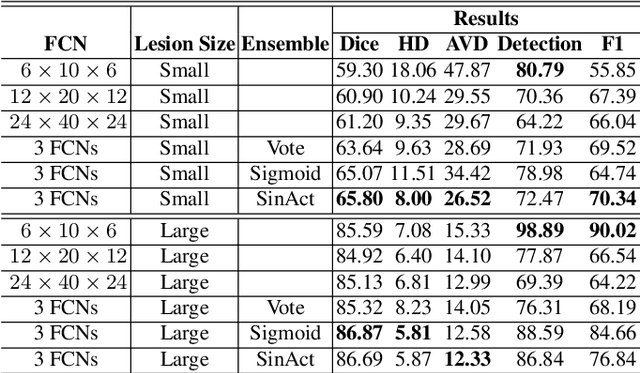
In this paper, we develop a two-stage neural network solution for the challenging task of white-matter lesion segmentation. To cope with the vast vari- ability in lesion sizes, we sample brain MR scans with patches at three differ- ent dimensions and feed them into separate fully convolutional neural networks (FCNs). In the second stage, we process large and small lesion separately, and use ensemble-nets to combine the segmentation results generated from the FCNs. A novel activation function is adopted in the ensemble-nets to improve the segmen- tation accuracy measured by Dice Similarity Coefficient. Experiments on MICCAI 2017 White Matter Hyperintensities (WMH) Segmentation Challenge data demonstrate that our two-stage-multi-sized FCN approach, as well as the new activation function, are effective in capturing white-matter lesions in MR images.