 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividualized Conditioning and Negative Distances for Speaker Separation
Paper and Code
Oct 12, 2022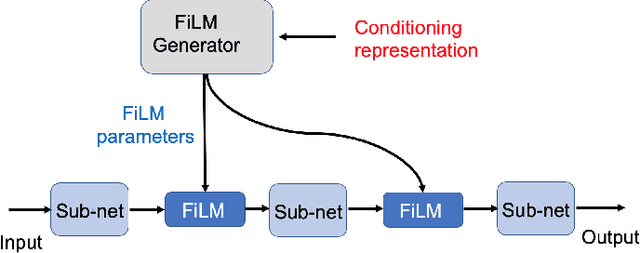


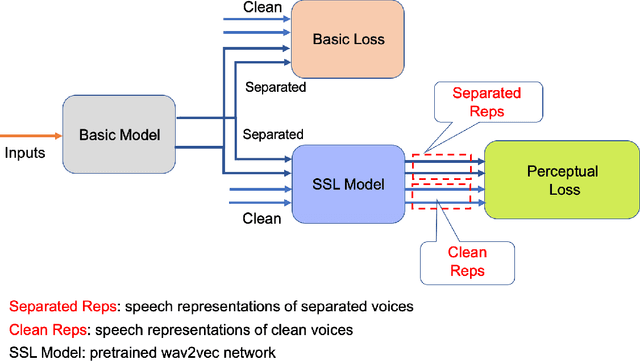
Speaker separation aims to extract multiple voices from a mixed signal. In this paper, we propose two speaker-aware designs to improve the existing speaker separation solutions. The first model is a speaker conditioning network that integrates speech samples to generate individualized speaker conditions, which then provide informed guidance for a separation module to produce well-separated outputs. The second design aims to reduce non-target voices in the separated speech. To this end, we propose negative distances to penalize the appearance of any non-target voice in the channel outputs, and positive distances to drive the separated voices closer to the clean targets. We explore two different setups, weighted-sum and triplet-like, to integrate these two distances to form a combined auxiliary loss for the separation networks. Experiments conducted on LibriMix demonstrate the effectiveness of our proposed models.