 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeopleSansPeople: A Synthetic Data Generator for Human-Centric Computer Vision
Dec 17, 2021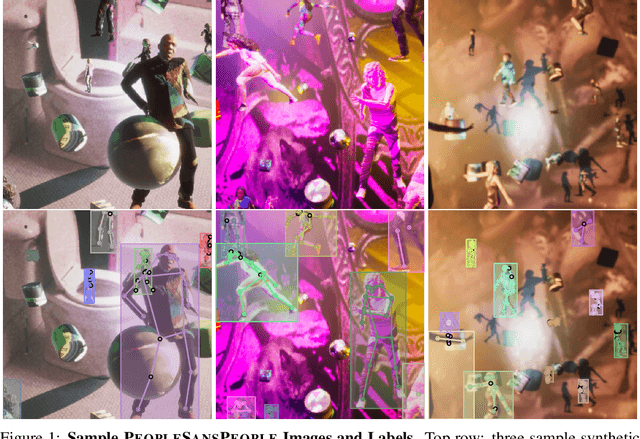



In recent years, person detection and human pose estimation have made great strides, helped by large-scale labeled datasets. However, these datasets had no guarantees or analysis of human activities, poses, or context diversity. Additionally, privacy, legal, safety, and ethical concerns may limit the ability to collect more human data. An emerging alternative to real-world data that alleviates some of these issues is synthetic data. However, creation of synthetic data generators is incredibly challenging and prevents researchers from exploring their usefulness. Therefore, we release a human-centric synthetic data generator PeopleSansPeople which contains simulation-ready 3D human assets, a parameterized lighting and camera system, and generates 2D and 3D bounding box, instance and semantic segmentation, and COCO pose labels. Using PeopleSansPeople, we performed benchmark synthetic data training using a Detectron2 Keypoint R-CNN variant [1]. We found that pre-training a network using synthetic data and fine-tuning on target real-world data (few-shot transfer to limited subsets of COCO-person train [2]) resulted in a keypoint AP of $60.37 \pm 0.48$ (COCO test-dev2017) outperforming models trained with the same real data alone (keypoint AP of $55.80$) and pre-trained with ImageNet (keypoint AP of $57.50$). This freely-available data generator should enable a wide range of research into the emerging field of simulation to real transfer learning in the critical area of human-centric computer vision.
Unity Perception: Generate Synthetic Data for Computer Vision
Jul 19, 2021


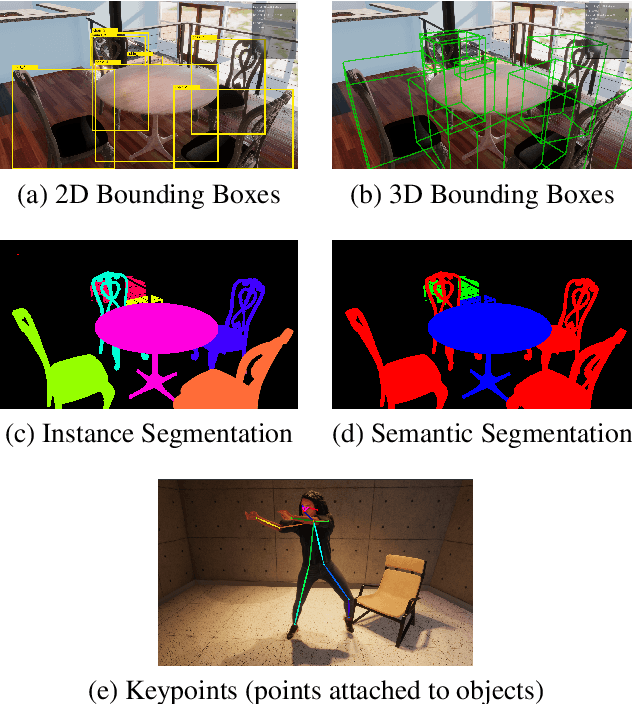
We introduce the Unity Perception package which aims to simplify and accelerate the process of generating synthetic datasets for computer vision tasks by offering an easy-to-use and highly customizable toolset. This open-source package extends the Unity Editor and engine components to generate perfectly annotated examples for several common computer vision tasks. Additionally, it offers an extensible Randomization framework that lets the user quickly construct and configure randomized simulation parameters in order to introduce variation into the generated datasets. We provide an overview of the provided tools and how they work, and demonstrate the value of the generated synthetic datasets by training a 2D object detection model. The model trained with mostly synthetic data outperforms the model trained using only real data.