 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEUCORE: Neural Concept Reasoning for Composed Image Retrieval
Paper and Code
Oct 02, 2023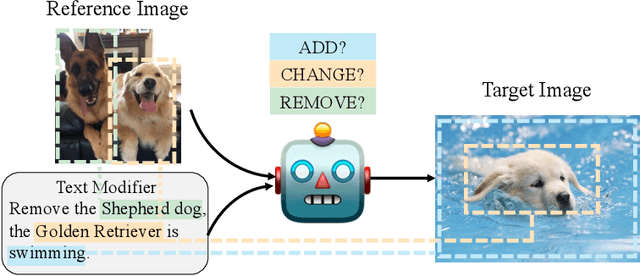

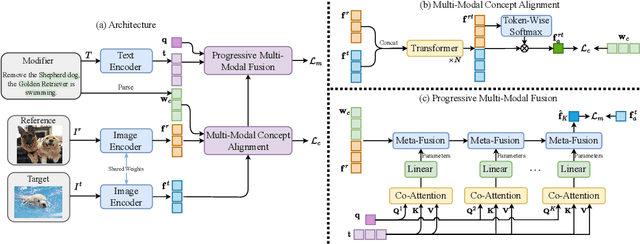
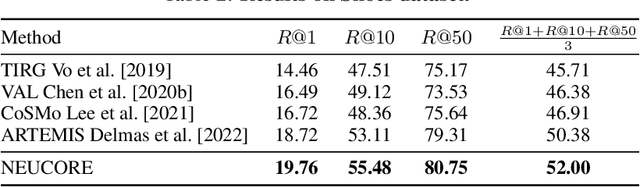
Composed image retrieval which combines a reference image and a text modifier to identify the desired target image is a challenging task, and requires the model to comprehend both vision and language modalities and their interactions. Existing approaches focus on holistic multi-modal interaction modeling, and ignore the composed and complimentary property between the reference image and text modifier. In order to better utilize the complementarity of multi-modal inputs for effective information fusion and retrieval, we move the multi-modal understanding to fine-granularity at concept-level, and learn the multi-modal concept alignment to identify the visual location in reference or target images corresponding to text modifier. Toward the end, we propose a NEUral COncept REasoning (NEUCORE) model which incorporates multi-modal concept alignment and progressive multimodal fusion over aligned concepts. Specifically, considering that text modifier may refer to semantic concepts not existing in the reference image and requiring to be added into the target image, we learn the multi-modal concept alignment between the text modifier and the concatenation of reference and target images, under multiple-instance learning framework with image and sentence level weak supervision. Furthermore, based on aligned concepts, to form discriminative fusion features of the input modalities for accurate target image retrieval, we propose a progressive fusion strategy with unified execution architecture instantiated by the attended language semantic concepts. Our proposed approach is evaluated on three datasets and achieves state-of-the-art results.