 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Action Recognition with Knowledge Bases
Jul 04, 2022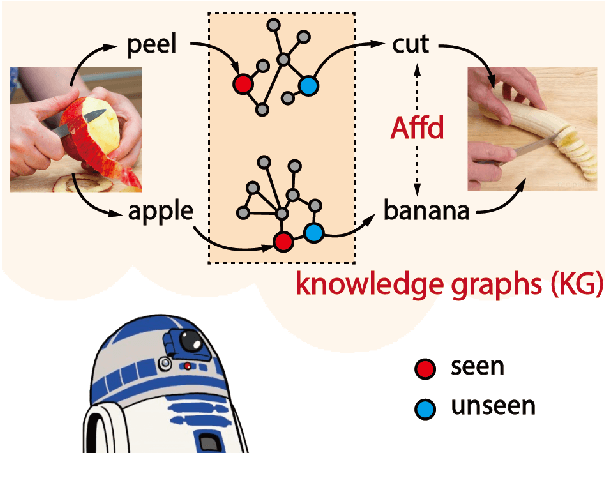
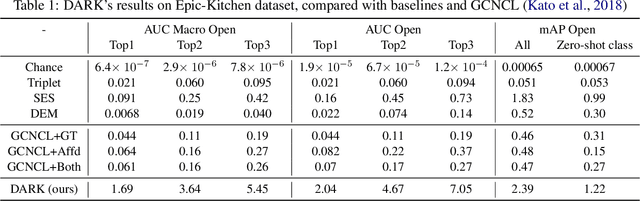
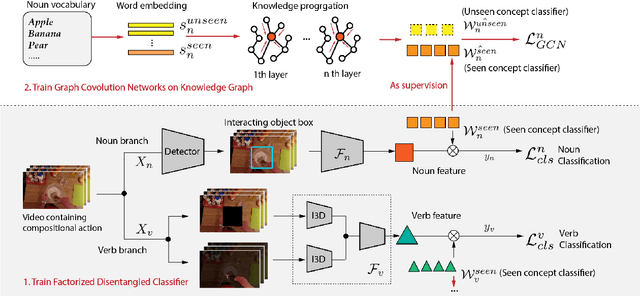
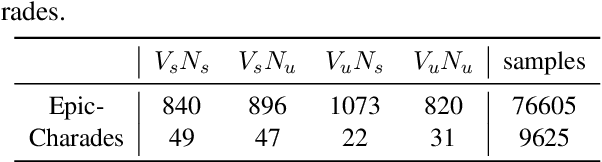
Action in video usually involves the interaction of human with objects. Action labels are typically composed of various combinations of verbs and nouns, but we may not have training data for all possible combinations. In this paper, we aim to improve the generalization ability of the compositional action recognition model to novel verbs or novel nouns that are unseen during training time, by leveraging the power of knowledge graphs. Previous work utilizes verb-noun compositional action nodes in the knowledge graph, making it inefficient to scale since the number of compositional action nodes grows quadratically with respect to the number of verbs and nouns. To address this issue, we propose our approach: Disentangled Action Recognition with Knowledge-bases (DARK), which leverages the inherent compositionality of actions. DARK trains a factorized model by first extracting disentangled feature representations for verbs and nouns, and then predicting classification weights using relations in external knowledge graphs. The type constraint between verb and noun is extracted from external knowledge bases and finally applied when composing actions. DARK has better scalability in the number of objects and verbs, and achieves state-of-the-art performance on the Charades dataset. We further propose a new benchmark split based on the Epic-kitchen dataset which is an order of magnitude bigger in the numbers of classes and samples, and benchmark various models on this benchmark.
Quantitative Understanding of VAE by Interpreting ELBO as Rate Distortion Cost of Transform Coding
Jul 30, 2020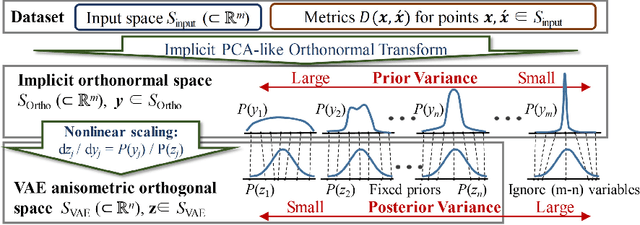
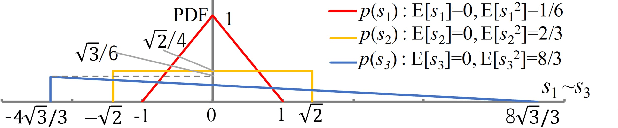
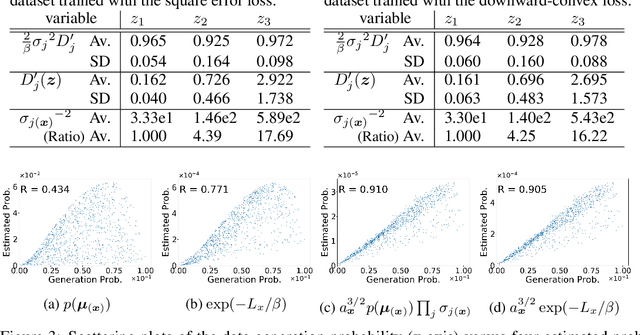
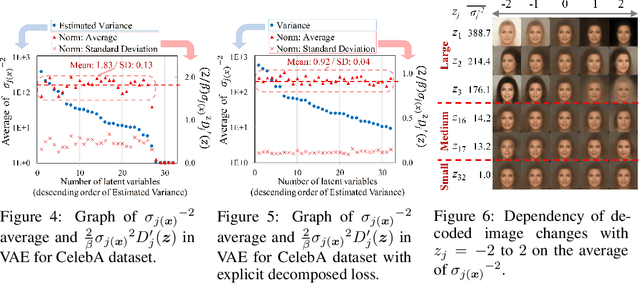
VAE (Variational autoencoder) estimates the posterior parameters (mean and variance) of latent variables corresponding to each input data. While it is used for many tasks, the transparency of the model is still an underlying issue. This paper provides a quantitative understanding of VAE property by interpreting ELBO maximization as Rate-distortion optimization of transform coding. According to the Rate-distortion theory, the optimal transform coding is achieved by using PCA-like orthonormal (orthogonal and unit norm) transform. From this analogy, we show theoretically and experimentally that VAE can be mapped to an implicit orthonormal transform with a scale factor derived from the posterior parameter. As a result, the quantitative importance of each latent variable can be evaluated like the eigenvalue of PCA. We can also estimate the data probabilities in the input space from the prior, loss metrics, and corresponding posterior parameters.
Rate-Distortion Optimization Guided Autoencoder for Generative Approach with quantitatively measurable latent space
Oct 10, 2019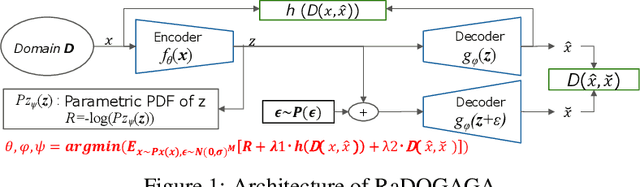



In the generative model approach of machine learning, it is essential to acquire an accurate probabilistic model and compress the dimension of data for easy treatment. However, in the conventional deep-autoencoder based generative model such as VAE, the probability of the real space cannot be obtained correctly from that of in the latent space, because the scaling between both spaces is not controlled. This has also been an obstacle to quantifying the impact of the variation of latent variables on data. In this paper, we propose Rate-Distortion Optimization guided autoencoder, in which the Jacobi matrix from real space to latent space has orthonormality. It is proved theoretically and experimentally that (i) the probability distribution of the latent space obtained by this model is proportional to the probability distribution of the real space because Jacobian between two spaces is constant; (ii) our model behaves as non-linear PCA, where energy of acquired latent space is concentrated on several principal components and the influence of each component can be evaluated quantitatively. Furthermore, to verify the usefulness on the practical application, we evaluate its performance in unsupervised anomaly detection and it outperforms current state-of-the-art methods.