 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Action Recognition with Knowledge Bases
Paper and Code
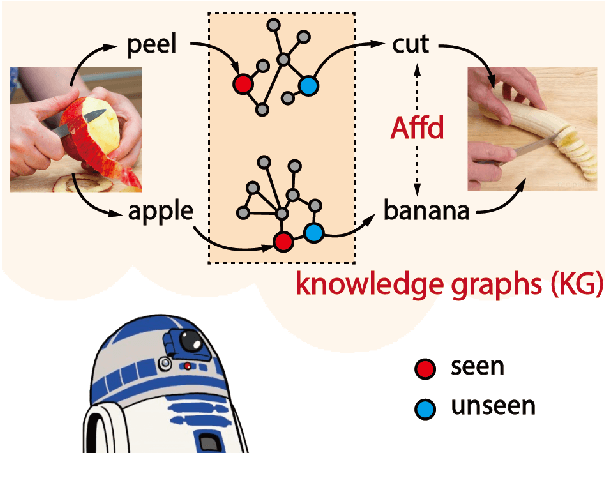
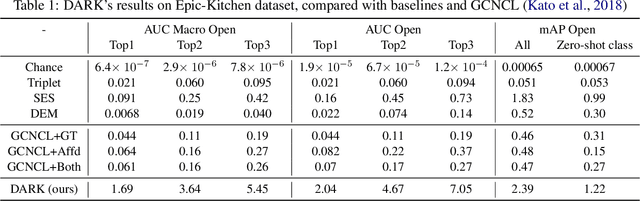
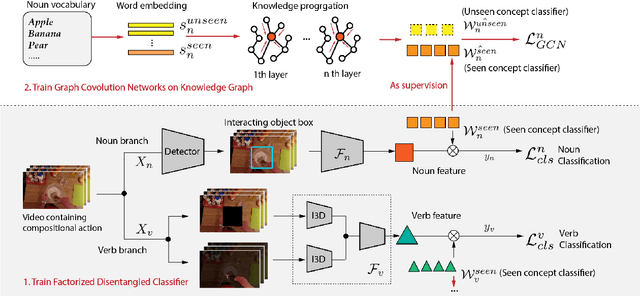
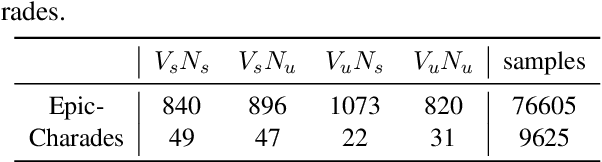
Action in video usually involves the interaction of human with objects. Action labels are typically composed of various combinations of verbs and nouns, but we may not have training data for all possible combinations. In this paper, we aim to improve the generalization ability of the compositional action recognition model to novel verbs or novel nouns that are unseen during training time, by leveraging the power of knowledge graphs. Previous work utilizes verb-noun compositional action nodes in the knowledge graph, making it inefficient to scale since the number of compositional action nodes grows quadratically with respect to the number of verbs and nouns. To address this issue, we propose our approach: Disentangled Action Recognition with Knowledge-bases (DARK), which leverages the inherent compositionality of actions. DARK trains a factorized model by first extracting disentangled feature representations for verbs and nouns, and then predicting classification weights using relations in external knowledge graphs. The type constraint between verb and noun is extracted from external knowledge bases and finally applied when composing actions. DARK has better scalability in the number of objects and verbs, and achieves state-of-the-art performance on the Charades dataset. We further propose a new benchmark split based on the Epic-kitchen dataset which is an order of magnitude bigger in the numbers of classes and samples, and benchmark various models on this benchmark.