 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Action Recognition with Knowledge Bases
Jul 04, 2022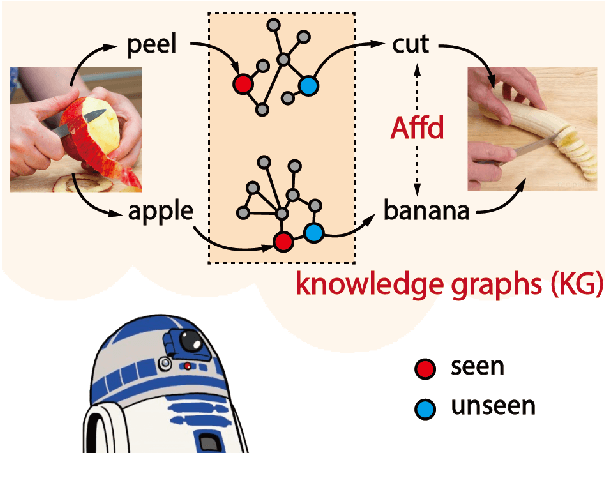
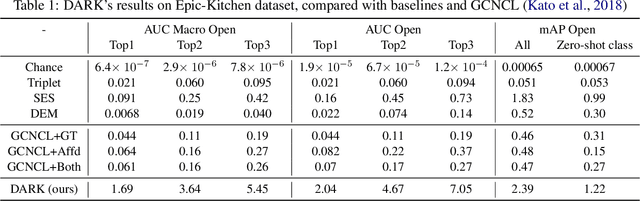
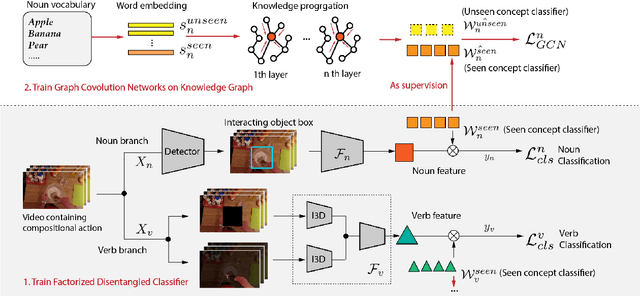
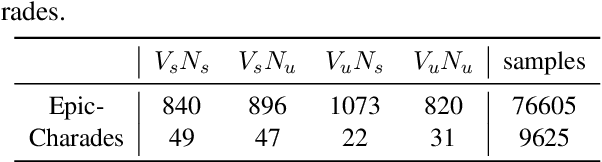
Action in video usually involves the interaction of human with objects. Action labels are typically composed of various combinations of verbs and nouns, but we may not have training data for all possible combinations. In this paper, we aim to improve the generalization ability of the compositional action recognition model to novel verbs or novel nouns that are unseen during training time, by leveraging the power of knowledge graphs. Previous work utilizes verb-noun compositional action nodes in the knowledge graph, making it inefficient to scale since the number of compositional action nodes grows quadratically with respect to the number of verbs and nouns. To address this issue, we propose our approach: Disentangled Action Recognition with Knowledge-bases (DARK), which leverages the inherent compositionality of actions. DARK trains a factorized model by first extracting disentangled feature representations for verbs and nouns, and then predicting classification weights using relations in external knowledge graphs. The type constraint between verb and noun is extracted from external knowledge bases and finally applied when composing actions. DARK has better scalability in the number of objects and verbs, and achieves state-of-the-art performance on the Charades dataset. We further propose a new benchmark split based on the Epic-kitchen dataset which is an order of magnitude bigger in the numbers of classes and samples, and benchmark various models on this benchmark.
Improving RNA Secondary Structure Design using Deep Reinforcement Learning
Nov 05, 2021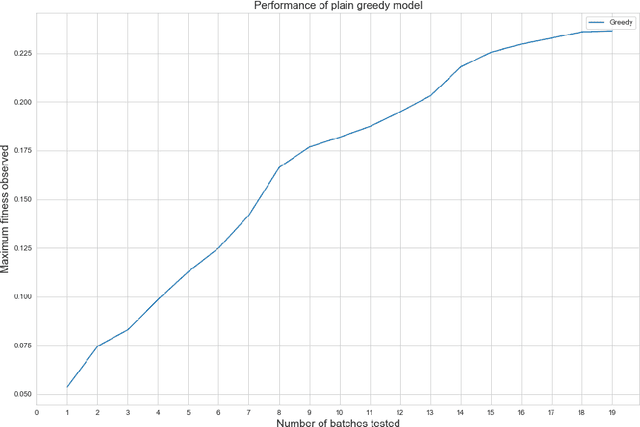
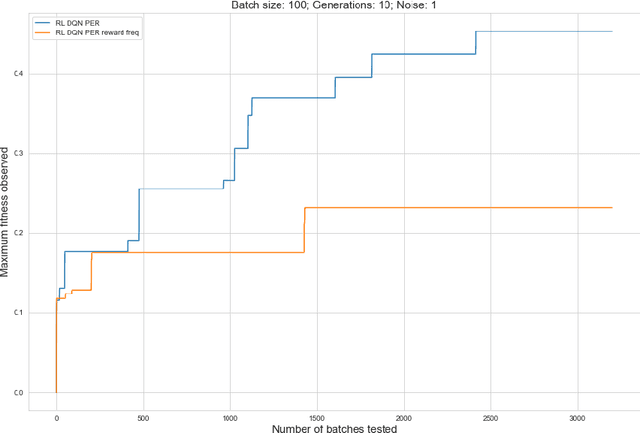
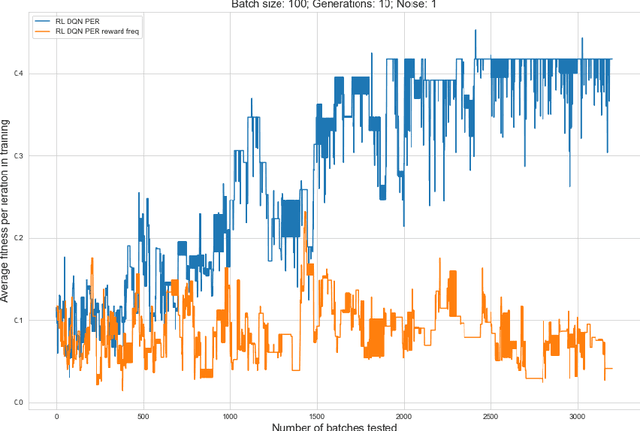
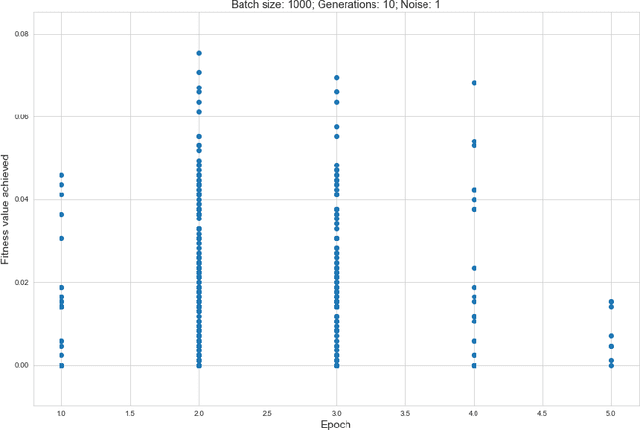
Rising costs in recent years of developing new drugs and treatments have led to extensive research in optimization techniques in biomolecular design. Currently, the most widely used approach in biomolecular design is directed evolution, which is a greedy hill-climbing algorithm that simulates biological evolution. In this paper, we propose a new benchmark of applying reinforcement learning to RNA sequence design, in which the objective function is defined to be the free energy in the sequence's secondary structure. In addition to experimenting with the vanilla implementations of each reinforcement learning algorithm from standard libraries, we analyze variants of each algorithm in which we modify the algorithm's reward function and tune the model's hyperparameters. We show results of the ablation analysis that we do for these algorithms, as well as graphs indicating the algorithm's performance across batches and its ability to search the possible space of RNA sequences. We find that our DQN algorithm performs by far the best in this setting, contrasting with, in which PPO performs the best among all tested algorithms. Our results should be of interest to those in the biomolecular design community and should serve as a baseline for future experiments involving machine learning in molecule design.
Weakly-Supervised Action Localization with Expectation-Maximization Multi-Instance Learning
Mar 31, 2020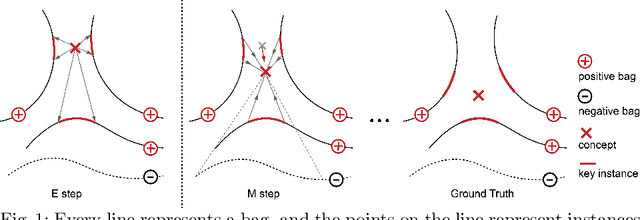
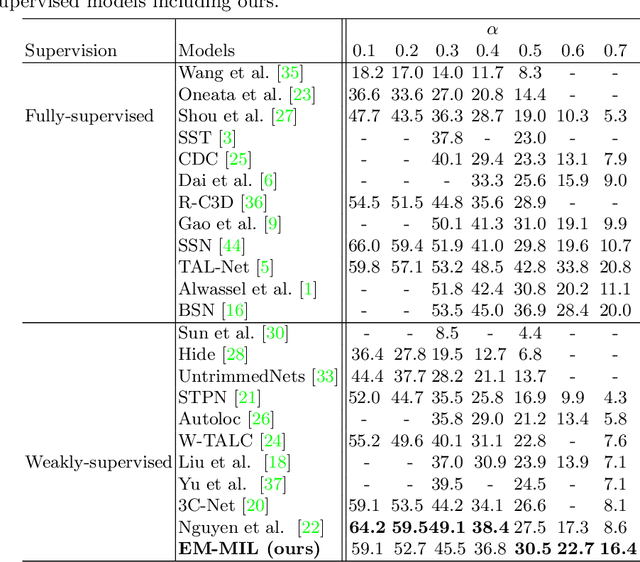
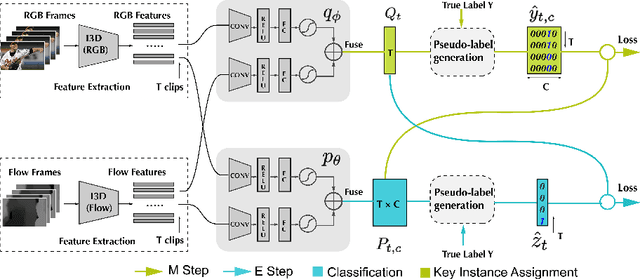
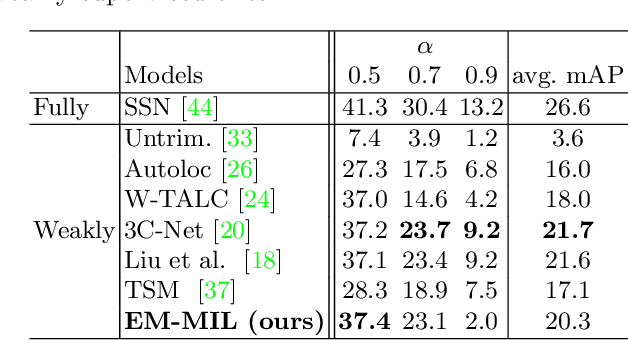
Weakly-supervised action localization problem requires training a model to localize the action segments in the video given only video level action label. It can be solved under the Multiple Instance Learning (MIL) framework, where a bag (video) contains multiple instances (action segments). Since only the bag's label is known, the main challenge is to assign which key instances within the bag trigger the bag's label. Most previous models use an attention-based approach. These models use attention to generate the bag's representation from instances and then train it via bag's classification. In this work, we explicitly model the key instances assignment as a hidden variable and adopt an Expectation-Maximization framework. We derive two pseudo-label generation schemes to model the E and M process and iteratively optimize the likelihood lower bound. We also show that previous attention-based models implicitly violate the MIL assumptions that instances in negative bags should be uniformly negative. In comparison, Our EM-MIL approach more accurately models these assumptions. Our model achieves state-of-the-art performance on two standard benchmarks, THUMOS14 and ActivityNet1.2, and shows the superiority of detecting relative complete action boundary in videos containing multiple actions.