 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Targeted Dynamic Chunking for Tokenization-Free Hierarchical Model
May 28, 2026Tokenization-free hierarchical models are emerging as a promising alternative to traditional Large Language Models (LLMs), addressing inherent preprocessing issues such as vocabulary design complexity, out-of-vocabulary (OOV) errors, and language-specific constraints. However, a significant challenge in these byte-level methods is the optimization of the compression ratio, a critical factor that dictates model performance for processing bytes data via chunks. In this paper, we propose Adaptive Targeted Dynamic Chunking (ATDC), a novel byte-compression control mechanism designed to enhance the effectiveness of dynamic chunking within hierarchical architectures. Our approach utilizes curriculum learning to progressively adjust the compression ratio during training, transitioning from low to high compression to stabilize the learning process. We provide an analysis establishing the relationship between the target compression ratio and Bytes-Per-Innermost-Chunk (BPIC), allowing for tracking of chunk-size evolution throughout the training phase. Evaluations conducted on the FineWeb-Edu 100B dataset demonstrate that hierarchical models equipped with ATDC achieve competitive Bits-Per-Byte (BPB) performance compared to conventional baselines operating at both byte and token levels. Furthermore, the proposed method exhibits more stable training dynamics and superior final performance across diverse downstream tasks compared to models using fixed compression ratios, while maintaining the inherent robustness and flexibility of byte-level processing.
Toward Unlimited Self-Learning Monte Carlo with Annealing Process Using VAE's Implicit Isometricity
Nov 25, 2022Self-learning Monte Carlo (SLMC) methods are recently proposed to accelerate Markov chain Monte Carlo (MCMC) methods by using a machine learning model.With generative models having latent variables, SLMC methods realize efficient Monte Carlo updates with less autocorrelation. However, SLMC methods are difficult to directly apply to multimodal distributions for which training data are difficult to obtain. In this paper, we propose a novel SLMC method called the ``annealing VAE-SLMC" to drastically expand the range of applications. Our VAE-SLMC utilizes a variational autoencoder (VAE) as a generative model to make efficient parallel proposals independent of any previous state by applying the theoretically derived implicit isometricity of the VAE. We combine an adaptive annealing process to the VAE-SLMC, making our method applicable to the cases where obtaining unbiased training data is difficult in practical sense due to slow mixing. We also propose a parallel annealing process and an exchange process between chains to make the annealing operation more precise and efficient. Experiments validate that our method can proficiently obtain unbiased samples from multiple multimodal toy distributions and practical multimodal posterior distributions, which is difficult to achieve with the existing SLMC methods.
Quantitative Understanding of VAE by Interpreting ELBO as Rate Distortion Cost of Transform Coding
Jul 30, 2020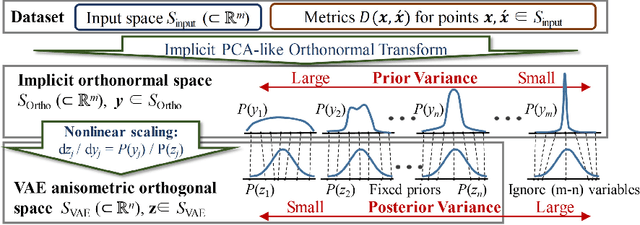
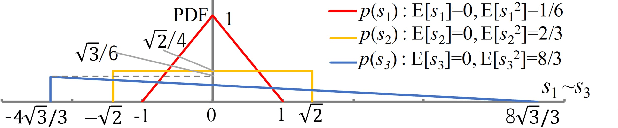
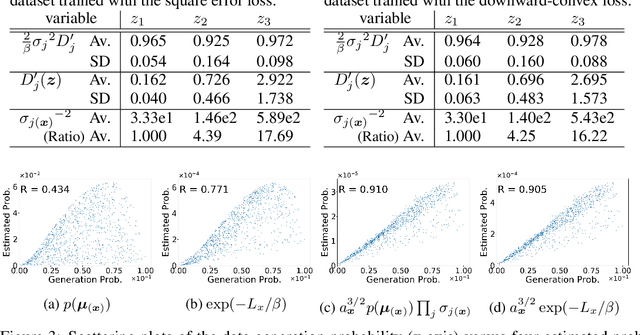
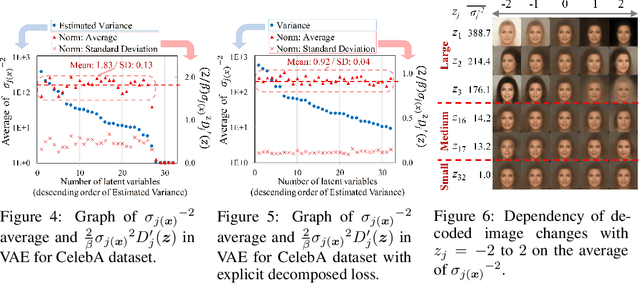
VAE (Variational autoencoder) estimates the posterior parameters (mean and variance) of latent variables corresponding to each input data. While it is used for many tasks, the transparency of the model is still an underlying issue. This paper provides a quantitative understanding of VAE property by interpreting ELBO maximization as Rate-distortion optimization of transform coding. According to the Rate-distortion theory, the optimal transform coding is achieved by using PCA-like orthonormal (orthogonal and unit norm) transform. From this analogy, we show theoretically and experimentally that VAE can be mapped to an implicit orthonormal transform with a scale factor derived from the posterior parameter. As a result, the quantitative importance of each latent variable can be evaluated like the eigenvalue of PCA. We can also estimate the data probabilities in the input space from the prior, loss metrics, and corresponding posterior parameters.
Rate-Distortion Optimization Guided Autoencoder for Generative Approach with quantitatively measurable latent space
Oct 10, 2019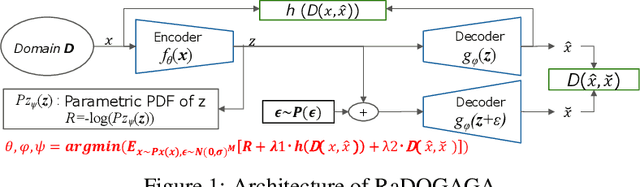



In the generative model approach of machine learning, it is essential to acquire an accurate probabilistic model and compress the dimension of data for easy treatment. However, in the conventional deep-autoencoder based generative model such as VAE, the probability of the real space cannot be obtained correctly from that of in the latent space, because the scaling between both spaces is not controlled. This has also been an obstacle to quantifying the impact of the variation of latent variables on data. In this paper, we propose Rate-Distortion Optimization guided autoencoder, in which the Jacobi matrix from real space to latent space has orthonormality. It is proved theoretically and experimentally that (i) the probability distribution of the latent space obtained by this model is proportional to the probability distribution of the real space because Jacobian between two spaces is constant; (ii) our model behaves as non-linear PCA, where energy of acquired latent space is concentrated on several principal components and the influence of each component can be evaluated quantitatively. Furthermore, to verify the usefulness on the practical application, we evaluate its performance in unsupervised anomaly detection and it outperforms current state-of-the-art methods.