 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStratified Avatar Generation from Sparse Observations
Paper and Code
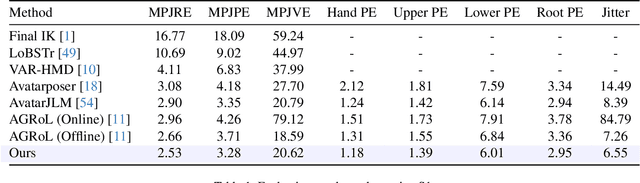
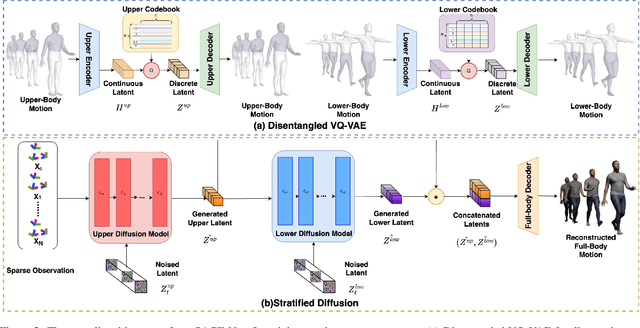
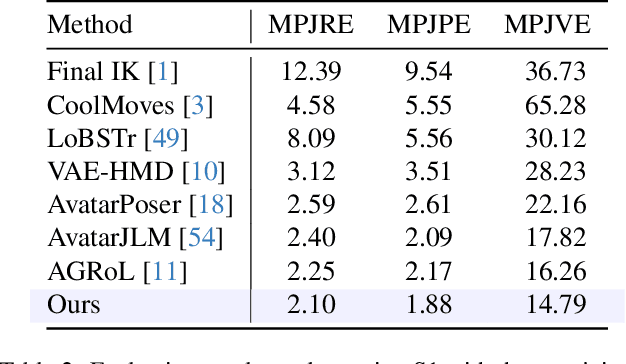
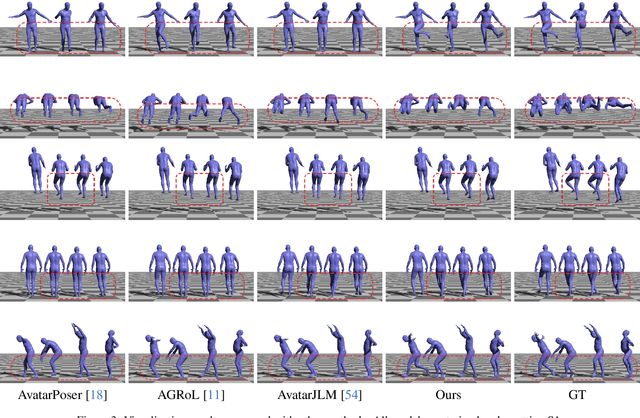
Estimating 3D full-body avatars from AR/VR devices is essential for creating immersive experiences in AR/VR applications. This task is challenging due to the limited input from Head Mounted Devices, which capture only sparse observations from the head and hands. Predicting the full-body avatars, particularly the lower body, from these sparse observations presents significant difficulties. In this paper, we are inspired by the inherent property of the kinematic tree defined in the Skinned Multi-Person Linear (SMPL) model, where the upper body and lower body share only one common ancestor node, bringing the potential of decoupled reconstruction. We propose a stratified approach to decouple the conventional full-body avatar reconstruction pipeline into two stages, with the reconstruction of the upper body first and a subsequent reconstruction of the lower body conditioned on the previous stage. To implement this straightforward idea, we leverage the latent diffusion model as a powerful probabilistic generator, and train it to follow the latent distribution of decoupled motions explored by a VQ-VAE encoder-decoder model. Extensive experiments on AMASS mocap dataset demonstrate our state-of-the-art performance in the reconstruction of full-body motions.