 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEXTS-Diff: TEXTS-Aware Diffusion Model for Real-World Text Image Super-Resolution
Jan 24, 2026Real-world text image super-resolution aims to restore overall visual quality and text legibility in images suffering from diverse degradations and text distortions. However, the scarcity of text image data in existing datasets results in poor performance on text regions. In addition, datasets consisting of isolated text samples limit the quality of background reconstruction. To address these limitations, we construct Real-Texts, a large-scale, high-quality dataset collected from real-world images, which covers diverse scenarios and contains natural text instances in both Chinese and English. Additionally, we propose the TEXTS-Aware Diffusion Model (TEXTS-Diff) to achieve high-quality generation in both background and textual regions. This approach leverages abstract concepts to improve the understanding of textual elements within visual scenes and concrete text regions to enhance textual details. It mitigates distortions and hallucination artifacts commonly observed in text regions, while preserving high-quality visual scene fidelity. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple evaluation metrics, exhibiting superior generalization ability and text restoration accuracy in complex scenarios. All the code, model, and dataset will be released.
Semantic Context Matters: Improving Conditioning for Autoregressive Models
Nov 18, 2025Recently, autoregressive (AR) models have shown strong potential in image generation, offering better scalability and easier integration with unified multi-modal systems compared to diffusion-based methods. However, extending AR models to general image editing remains challenging due to weak and inefficient conditioning, often leading to poor instruction adherence and visual artifacts. To address this, we propose SCAR, a Semantic-Context-driven method for Autoregressive models. SCAR introduces two key components: Compressed Semantic Prefilling, which encodes high-level semantics into a compact and efficient prefix, and Semantic Alignment Guidance, which aligns the last visual hidden states with target semantics during autoregressive decoding to enhance instruction fidelity. Unlike decoding-stage injection methods, SCAR builds upon the flexibility and generality of vector-quantized-based prefilling while overcoming its semantic limitations and high cost. It generalizes across both next-token and next-set AR paradigms with minimal architectural changes. SCAR achieves superior visual fidelity and semantic alignment on both instruction editing and controllable generation benchmarks, outperforming prior AR-based methods while maintaining controllability. All code will be released.
FLUX-Text: A Simple and Advanced Diffusion Transformer Baseline for Scene Text Editing
May 06, 2025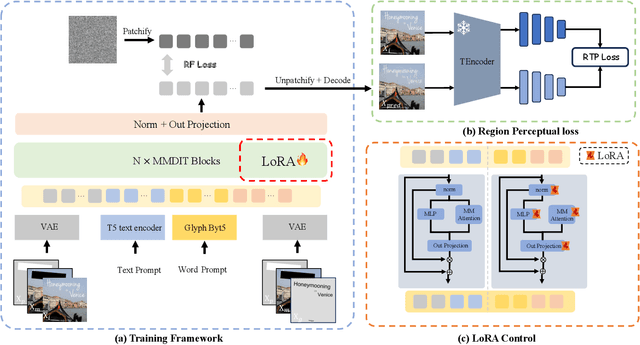
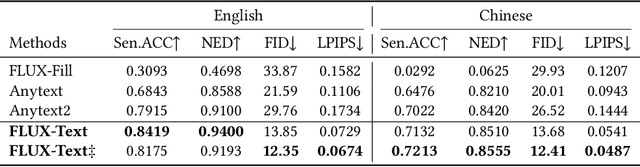
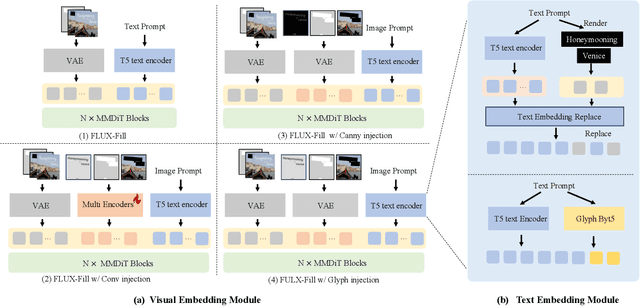

The task of scene text editing is to modify or add texts on images while maintaining the fidelity of newly generated text and visual coherence with the background. Recent works based on latent diffusion models (LDM) show improved text editing results, yet still face challenges and often generate inaccurate or unrecognizable characters, especially for non-Latin ones (\eg, Chinese), which have complex glyph structures. To address these issues, we present FLUX-Text, a simple and advanced multilingual scene text editing framework based on FLUX-Fill. Specifically, we carefully investigate glyph conditioning, considering both visual and textual modalities. To retain the original generative capabilities of FLUX-Fill while enhancing its understanding and generation of glyphs, we propose lightweight glyph and text embedding modules. Owning to the lightweight design, FLUX-Text is trained only with $100K$ training examples compared to current popular methods trained with 2.9M ones. With no bells and whistles, our method achieves state-of-the-art performance on text editing tasks. Qualitative and quantitative experiments on the public datasets demonstrate that our method surpasses previous works in text fidelity.
Towards Scalable Distributed Training of Deep Learning on Public Cloud Clusters
Oct 20, 2020
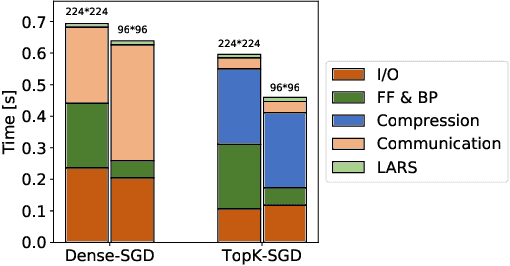
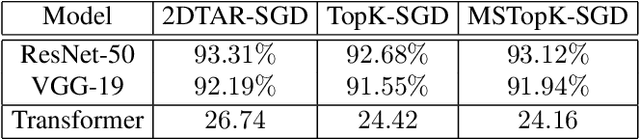
Distributed training techniques have been widely deployed in large-scale deep neural networks (DNNs) training on dense-GPU clusters. However, on public cloud clusters, due to the moderate inter-connection bandwidth between instances, traditional state-of-the-art distributed training systems cannot scale well in training large-scale models. In this paper, we propose a new computing and communication efficient top-k sparsification communication library for distributed training. To further improve the system scalability, we optimize I/O by proposing a simple yet efficient multi-level data caching mechanism and optimize the update operation by introducing a novel parallel tensor operator. Experimental results on a 16-node Tencent Cloud cluster (each node with 8 Nvidia Tesla V100 GPUs) show that our system achieves 25%-40% faster than existing state-of-the-art systems on CNNs and Transformer. We finally break the record on DAWNBench on training ResNet-50 to 93% top-5 accuracy on ImageNet.
Distributed Equivalent Substitution Training for Large-Scale Recommender Systems
Sep 10, 2019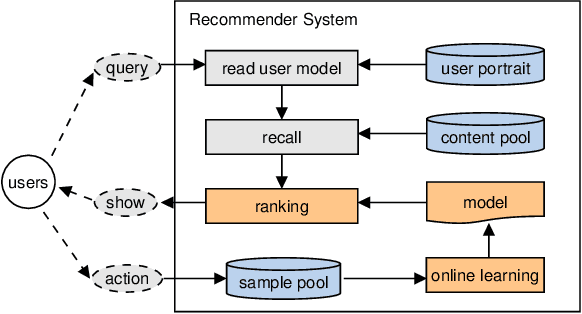
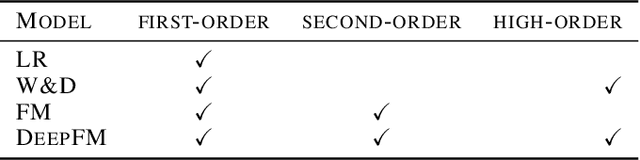
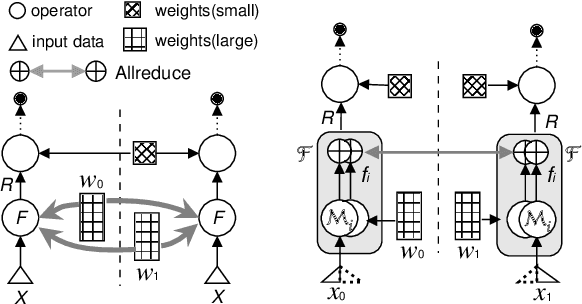
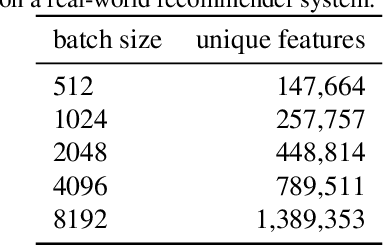
We present Distributed Equivalent Substitution (DES) training, a novel distributed training framework for recommender systems with large-scale dynamic sparse features. Our framework achieves faster convergence with less communication overhead and better computing resource utilization. DES strategy splits a weights-rich operator into sub-operators with co-located weights and aggregates partial results with much smaller communication cost to form a computationally equivalent substitution to the original operator. We show that for different types of models that recommender systems use, we can always find computational equivalent substitutions and splitting strategies for their weights-rich operators with theoretical communication load reduced ranging from 72.26% to 99.77%. We also present an implementation of DES that outperforms state-of-the-art recommender systems. Experiments show that our framework achieves up to 83% communication savings compared to other recommender systems, and can bring up to 4.5x improvement on throughput for deep models.